Jak usunąć wady wypukłości w kwadracie Sudoku?
Robiłem fajny projekt: rozwiązywanie Sudoku z obrazu wejściowego za pomocą OpenCV (jak w Google goggles itp.). I wykonałem zadanie, ale na koniec znalazłem mały problem, dla którego przyszedłem tutaj.
Wykonałem programowanie przy użyciu API Pythona w OpenCV 2.3.1.
Poniżej to co zrobiłem:
- przeczytaj obraz
- Znajdź kontury
- Wybierz ten z maksymalnym obszarem (a także nieco równoważnym Kwadratowi).
-
Find the corner punktów.
Np. podane poniżej:

(zwróć uwagę, że zielona linia prawidłowo pokrywa się z rzeczywistą granicą Sudoku, więc Sudoku może być poprawnie wypaczone . Sprawdź następny obrazek)
-
Wypnij obraz do idealnego kwadratu
EG image:

Wykonaj OCR (do którego użyłem metody podanej w prostym rozpoznawaniu cyfr OCR w OpenCV-Python )
I metoda zadziałało dobrze.
Problem:
Zobacz to zdjęcie.
{kind=link}
Wykonanie kroku 4 na tym obrazku daje wynik poniżej:

Czerwona linia jest oryginalnym konturem, który jest prawdziwym konturem granicy sudoku.
Narysowana zielona linia jest przybliżonym konturem, który będzie konturem wypaczonego obrazu.
Co oczywiście jest różnicą między zieloną i czerwoną linią na górnej krawędzi sudoku. Więc podczas wypaczanie, nie rozumiem oryginalnej granicy Sudoku.
Moje Pytanie:
Jak wypaczać obrazek na prawidłowej granicy Sudoku, czyli czerwonej linii lub jak usunąć różnicę między czerwoną i zieloną linią? Czy jest na to jakaś metoda w OpenCV?
4 answers
Mam rozwiązanie, które działa, ale będziesz musiał przetłumaczyć je na OpenCV samodzielnie. Jest napisane w Mathematica.
Pierwszym krokiem jest dostosowanie jasności obrazu, dzieląc każdy piksel z wynikiem operacji zamknięcia:
src = ColorConvert[Import["http://davemark.com/images/sudoku.jpg"], "Grayscale"];
white = Closing[src, DiskMatrix[5]];
srcAdjusted = Image[ImageData[src]/ImageData[white]]

Następnym krokiem jest znalezienie obszaru sudoku, więc mogę ignorować (maskować) tło. W tym celu korzystam z analizy komponentów połączonych i wybieram komponent, który ma największą wypukłość powierzchnia:
components =
ComponentMeasurements[
ColorNegate@Binarize[srcAdjusted], {"ConvexArea", "Mask"}][[All,
2]];
largestComponent = Image[SortBy[components, First][[-1, 2]]]

Wypełniając ten obrazek, otrzymuję maskę do siatki sudoku:
mask = FillingTransform[largestComponent]

Teraz mogę użyć filtra pochodnego drugiego rzędu, aby znaleźć pionowe i poziome linie na dwóch oddzielnych obrazach:
lY = ImageMultiply[MorphologicalBinarize[GaussianFilter[srcAdjusted, 3, {2, 0}], {0.02, 0.05}], mask];
lX = ImageMultiply[MorphologicalBinarize[GaussianFilter[srcAdjusted, 3, {0, 2}], {0.02, 0.05}], mask];
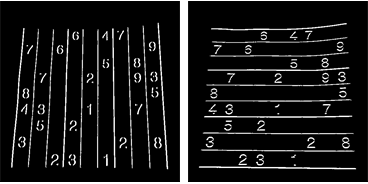
Ponownie używam analizy połączonych komponentów, aby wyodrębnić linie siatki z tych obrazów. Linie siatki są znacznie dłuższe niż cyfry, więc mogę użyć długości Suwmiarki, aby wybrać tylko linie siatki-połączone komponenty. Sortując je według pozycji, otrzymuję 2x10 obrazów maski dla każdej z pionowych / poziomych linii siatki na obrazie:
verticalGridLineMasks =
SortBy[ComponentMeasurements[
lX, {"CaliperLength", "Centroid", "Mask"}, # > 100 &][[All,
2]], #[[2, 1]] &][[All, 3]];
horizontalGridLineMasks =
SortBy[ComponentMeasurements[
lY, {"CaliperLength", "Centroid", "Mask"}, # > 100 &][[All,
2]], #[[2, 2]] &][[All, 3]];

Następnie biorę każdą parę pionowych / poziomych linii siatki, rozszerzam je, obliczam przecięcie piksel po pikselu i obliczam środek wyniku. Punkty te są przecięciami linii siatki:
centerOfGravity[l_] :=
ComponentMeasurements[Image[l], "Centroid"][[1, 2]]
gridCenters =
Table[centerOfGravity[
ImageData[Dilation[Image[h], DiskMatrix[2]]]*
ImageData[Dilation[Image[v], DiskMatrix[2]]]], {h,
horizontalGridLineMasks}, {v, verticalGridLineMasks}];

Ostatnim krokiem jest zdefiniowanie dwóch funkcji interpolacyjnych dla mapowania X / Y przez te punkty i przekształcenie obrazu korzystanie z tych funkcji:
fnX = ListInterpolation[gridCenters[[All, All, 1]]];
fnY = ListInterpolation[gridCenters[[All, All, 2]]];
transformed =
ImageTransformation[
srcAdjusted, {fnX @@ Reverse[#], fnY @@ Reverse[#]} &, {9*50, 9*50},
PlotRange -> {{1, 10}, {1, 10}}, DataRange -> Full]

Wszystkie operacje są podstawową funkcją przetwarzania obrazu, więc powinno to być możliwe również w OpenCV. Transformacja obrazu oparta na splajnach może być trudniejsza, ale nie sądzę, że naprawdę jej potrzebujesz. Prawdopodobnie użycie transformacji perspektywicznej, której używasz teraz na każdej pojedynczej komórce, da wystarczająco dobre wyniki.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-04-20 07:21:37
Odpowiedź Nikie ' ego rozwiązała mój problem, ale jego odpowiedź była w Mathematica. Więc pomyślałem, że powinienem dać jego adaptację OpenCV tutaj. Ale po zaimplementowaniu zauważyłem, że kod OpenCV jest znacznie większy niż kod mathematica Nikie ' ego. Poza tym, nie mogłem znaleźć metody interpolacji wykonanej przez nikie w OpenCV ( chociaż można to zrobić za pomocą scipy, powiem to, kiedy nadejdzie czas.)
1. Wstępne przetwarzanie obrazu ( operacja zamykania)
import cv2
import numpy as np
img = cv2.imread('dave.jpg')
img = cv2.GaussianBlur(img,(5,5),0)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
mask = np.zeros((gray.shape),np.uint8)
kernel1 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(11,11))
close = cv2.morphologyEx(gray,cv2.MORPH_CLOSE,kernel1)
div = np.float32(gray)/(close)
res = np.uint8(cv2.normalize(div,div,0,255,cv2.NORM_MINMAX))
res2 = cv2.cvtColor(res,cv2.COLOR_GRAY2BGR)
Wynik :

2. Znajdowanie kwadratu Sudoku i tworzenie obrazu Maski
thresh = cv2.adaptiveThreshold(res,255,0,1,19,2)
contour,hier = cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
max_area = 0
best_cnt = None
for cnt in contour:
area = cv2.contourArea(cnt)
if area > 1000:
if area > max_area:
max_area = area
best_cnt = cnt
cv2.drawContours(mask,[best_cnt],0,255,-1)
cv2.drawContours(mask,[best_cnt],0,0,2)
res = cv2.bitwise_and(res,mask)
Wynik:

3. Znajdowanie pionowych linii
kernelx = cv2.getStructuringElement(cv2.MORPH_RECT,(2,10))
dx = cv2.Sobel(res,cv2.CV_16S,1,0)
dx = cv2.convertScaleAbs(dx)
cv2.normalize(dx,dx,0,255,cv2.NORM_MINMAX)
ret,close = cv2.threshold(dx,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
close = cv2.morphologyEx(close,cv2.MORPH_DILATE,kernelx,iterations = 1)
contour, hier = cv2.findContours(close,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
for cnt in contour:
x,y,w,h = cv2.boundingRect(cnt)
if h/w > 5:
cv2.drawContours(close,[cnt],0,255,-1)
else:
cv2.drawContours(close,[cnt],0,0,-1)
close = cv2.morphologyEx(close,cv2.MORPH_CLOSE,None,iterations = 2)
closex = close.copy()
Wynik:

4. Znajdowanie Linii Poziomych
kernely = cv2.getStructuringElement(cv2.MORPH_RECT,(10,2))
dy = cv2.Sobel(res,cv2.CV_16S,0,2)
dy = cv2.convertScaleAbs(dy)
cv2.normalize(dy,dy,0,255,cv2.NORM_MINMAX)
ret,close = cv2.threshold(dy,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
close = cv2.morphologyEx(close,cv2.MORPH_DILATE,kernely)
contour, hier = cv2.findContours(close,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
for cnt in contour:
x,y,w,h = cv2.boundingRect(cnt)
if w/h > 5:
cv2.drawContours(close,[cnt],0,255,-1)
else:
cv2.drawContours(close,[cnt],0,0,-1)
close = cv2.morphologyEx(close,cv2.MORPH_DILATE,None,iterations = 2)
closey = close.copy()
Wynik:

Oczywiście, ten nie jest zbyt dobry.
5. Znajdowanie Punktów Siatki
res = cv2.bitwise_and(closex,closey)
Wynik:

6. Poprawiono wady
Tutaj Nikie robi jakąś interpolację, o której nie mam zbyt wiele wiedzy. I nie mogłem znaleźć żadnej odpowiedniej funkcji dla tego OpenCV. (może tam jest, Nie wiem).
Zobacz ten SOF, który wyjaśnia, jak to zrobić za pomocą SciPy, którego nie chcę używać : transformacja obrazu w OpenCV
Więc tutaj wziąłem 4 rogi każdego sub-kwadratu i zastosowałem perspektywę osnowy do każdego.
W tym celu najpierw znajdujemy centroidy.
contour, hier = cv2.findContours(res,cv2.RETR_LIST,cv2.CHAIN_APPROX_SIMPLE)
centroids = []
for cnt in contour:
mom = cv2.moments(cnt)
(x,y) = int(mom['m10']/mom['m00']), int(mom['m01']/mom['m00'])
cv2.circle(img,(x,y),4,(0,255,0),-1)
centroids.append((x,y))
Ale powstałe centroidy nie będą sortowane. Sprawdź poniższy obrazek, aby zobaczyć ich kolejność:

centroids = np.array(centroids,dtype = np.float32)
c = centroids.reshape((100,2))
c2 = c[np.argsort(c[:,1])]
b = np.vstack([c2[i*10:(i+1)*10][np.argsort(c2[i*10:(i+1)*10,0])] for i in xrange(10)])
bm = b.reshape((10,10,2))
Teraz patrz poniżej ich kolejność:

Na koniec stosujemy transformację i tworzymy nowy obraz o rozmiarze 450x450.
output = np.zeros((450,450,3),np.uint8)
for i,j in enumerate(b):
ri = i/10
ci = i%10
if ci != 9 and ri!=9:
src = bm[ri:ri+2, ci:ci+2 , :].reshape((4,2))
dst = np.array( [ [ci*50,ri*50],[(ci+1)*50-1,ri*50],[ci*50,(ri+1)*50-1],[(ci+1)*50-1,(ri+1)*50-1] ], np.float32)
retval = cv2.getPerspectiveTransform(src,dst)
warp = cv2.warpPerspective(res2,retval,(450,450))
output[ri*50:(ri+1)*50-1 , ci*50:(ci+1)*50-1] = warp[ri*50:(ri+1)*50-1 , ci*50:(ci+1)*50-1].copy()
Wynik:
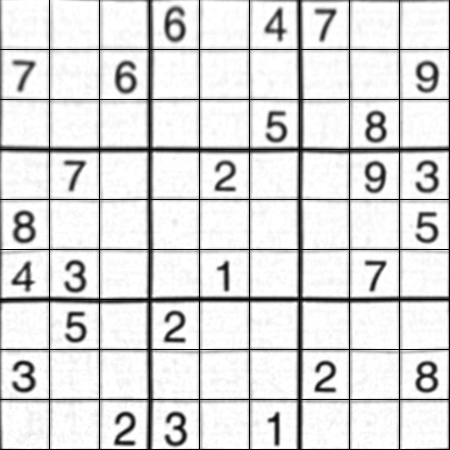
Wynik jest prawie taki sam jak Nikie, ale długość kodu jest duża. Może być, lepsze metody są dostępne tam, ale do tego czasu działa to OK.
Pozdrawiam ARK.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 10:31:10
Możesz spróbować użyć pewnego rodzaju modelowania opartego na siatce dowolnego wypaczania. A ponieważ sudoku jest już siatką, to nie powinno być zbyt trudne.
Więc możesz spróbować wykryć granice każdego podregionu 3x3, a następnie wypaczać Każdy region indywidualnie. Jeśli Detekcja się powiedzie, dałoby to lepsze przybliżenie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-04-18 06:54:09
Chcę dodać, że powyższa metoda działa tylko wtedy, gdy plansza sudoku stoi prosto, w przeciwnym razie test proporcji wysokość / szerokość (lub odwrotnie) najprawdopodobniej się nie powiedzie i nie będziesz w stanie wykryć krawędzi sudoku. (Chcę również dodać, że jeśli linie, które nie są prostopadłe do granic obrazu, operacje sobel (dx I dy) nadal będą działać, ponieważ linie nadal będą miały krawędzie w odniesieniu do obu osi.)
Aby móc wykryć linie proste należy pracować nad analizą konturu lub pikseli takie jak contourArea/boundingRectArea, górne lewe i dolne prawe punkty...
Edit: udało mi się sprawdzić, czy zestaw konturów tworzy linię, czy nie, stosując regresję liniową i sprawdzając błąd. Jednak regresja liniowa przebiegała słabo, gdy nachylenie linii jest zbyt duże (tj. >1000) lub jest bardzo bliskie 0. Dlatego zastosowanie testu proporcji powyżej (w większości upvoted odpowiedzi) przed regresją liniową jest logiczne i nie działa dla mnie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-10-11 11:10:54