Can scipy.statystyki identyfikują i maskują oczywiste odstające wartości?
Z scipy.statystyki.linregress wykonuję prostą regresję liniową na niektórych zestawach wysoce skorelowanych danych eksperymentalnych X, y i początkowo wizualnie sprawdzając każdy wykres punktowy X, y dla odstających. Ogólniej (tj. programowo) czy istnieje sposób na identyfikację i maskowanie odstających wartości?
4 answers
Pakiet statsmodels ma to, czego potrzebujesz. Spójrz na ten mały fragment kodu i jego wyjście:
# Imports #
import statsmodels.api as smapi
import statsmodels.graphics as smgraphics
# Make data #
x = range(30)
y = [y*10 for y in x]
# Add outlier #
x.insert(6,15)
y.insert(6,220)
# Make graph #
regression = smapi.OLS(x, y).fit()
figure = smgraphics.regressionplots.plot_fit(regression, 0)
# Find outliers #
test = regression.outlier_test()
outliers = ((x[i],y[i]) for i,t in enumerate(test) if t[2] < 0.5)
print 'Outliers: ', list(outliers)
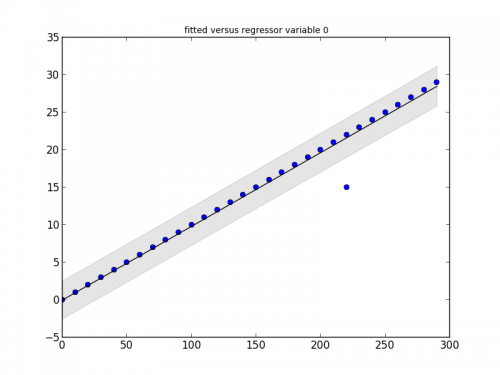
Outliers: [(15, 220)]
Edit
W nowszej wersji statsmodels, rzeczy się trochę zmieniły. Oto nowy fragment kodu, który pokazuje ten sam Typ detekcji odstających.
# Imports #
from random import random
import statsmodels.api as smapi
from statsmodels.formula.api import ols
import statsmodels.graphics as smgraphics
# Make data #
x = range(30)
y = [y*(10+random())+200 for y in x]
# Add outlier #
x.insert(6,15)
y.insert(6,220)
# Make fit #
regression = ols("data ~ x", data=dict(data=y, x=x)).fit()
# Find outliers #
test = regression.outlier_test()
outliers = ((x[i],y[i]) for i,t in enumerate(test.icol(2)) if t < 0.5)
print 'Outliers: ', list(outliers)
# Figure #
figure = smgraphics.regressionplots.plot_fit(regression, 1)
# Add line #
smgraphics.regressionplots.abline_plot(model_results=regression, ax=figure.axes[0])
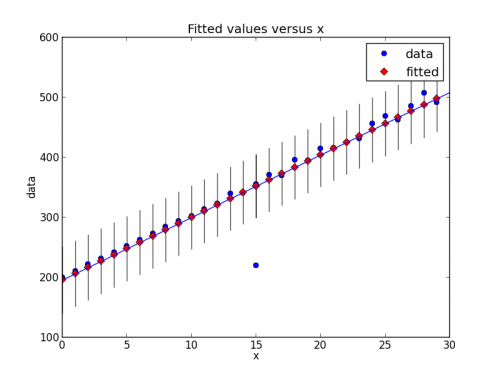
Outliers: [(15, 220)]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-04-24 12:54:09
Bardziej ogólnie (tj. programowo) czy istnieje sposób na identyfikację i maskowanie odstających wartości?
Istnieją różne algorytmy detekcji odstających; scikit-learn implementuje kilka z nich.
[Zastrzeżenie: jestem współpracownikiem scikit-learn.]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-04-19 15:46:58
Scipy.stats nie ma nic bezpośrednio dla odstających, więc jako odpowiedź na kilka linków i reklam statsmodels (co jest uzupełnieniem statystyk dla scipy.Statystyki)
Do identyfikacji outliers
Http://jpktd.blogspot.ca/2012/01/influence-and-outlier-measures-in.html
Http://jpktd.blogspot.ca/2012/01/anscombe-and-diagnostic-statistics.html
Zamiast maskowania, lepszym podejściem jest użycie solidnego estymatora]}Http://statsmodels.sourceforge.net/devel/rlm.html
Z przykładami, gdzie niestety działki nie są obecnie wyświetlane http://statsmodels.sourceforge.net/devel/examples/generated/tut_ols_rlm.html
RLM downweights outliers. Wyniki estymacji mają atrybut weights, a dla wartości odstających wagi są mniejsze niż 1. Można to również wykorzystać do znajdowania wartości odstających. RLM jest również bardziej wytrzymały, jeśli są kilka odstających.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-04-20 02:49:46
Możliwe jest również ograniczenie efektu odstających za pomocą scipy./ align = "left" / least_squares . W szczególności spójrz na parametr f_scale:
Wartość marginesu miękkiego pomiędzy pozostałościami inlier i outlier, domyślnie wynosi 1.0. ... Parametr ten nie ma wpływu na loss= 'liniowy', ale dla innych wartości strat ma kluczowe znaczenie.
Na stronie porównują 3 różne funkcje: normalną least_squares oraz dwie metody obejmujące f_scale:
res_lsq = least_squares(fun, x0, args=(t_train, y_train))
res_soft_l1 = least_squares(fun, x0, loss='soft_l1', f_scale=0.1, args=(t_train, y_train))
res_log = least_squares(fun, x0, loss='cauchy', f_scale=0.1, args=(t_train, y_train))

Jak widać, na normalne najmniejsze kwadraty mają znacznie większy wpływ wartości odstające danych i warto się bawić różnymi funkcjami loss w połączeniu z różnymi funkcjami f_scales. Możliwe funkcje strat są (wzięte z dokumentacji):
‘linear’ : Gives a standard least-squares problem.
‘soft_l1’: The smooth approximation of l1 (absolute value) loss. Usually a good choice for robust least squares.
‘huber’ : Works similarly to ‘soft_l1’.
‘cauchy’ : Severely weakens outliers influence, but may cause difficulties in optimization process.
‘arctan’ : Limits a maximum loss on a single residual, has properties similar to ‘cauchy’.
The scipy cookbook ma schludny samouczek na temat solidnej nieliniowej regresji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-04 14:57:13