Jaka jest różnica między łańcuchami Markowa a ukrytym modelem Markowa?
Jaka jest różnica między modelami łańcucha Markowa a ukrytym modelem Markowa? Czytałem w Wikipedii, ale nie mogłem zrozumieć różnic.
5 answers
Aby wyjaśnić za pomocą przykładu, użyję przykładu z przetwarzania języka naturalnego. Wyobraź sobie, że chcesz poznać prawdopodobieństwo tego zdania:
Lubię kawę
W modelu Markowa można oszacować jego prawdopodobieństwo, obliczając:
P(WORD = I) x P(WORD = enjoy | PREVIOUS_WORD = I) x P(word = coffee| PREVIOUS_WORD = enjoy)
Wyobraźmy sobie, że chcieliśmy znać znaczniki części mowy tego zdania, to znaczy, czy słowo jest czasownikiem przeszłym, rzeczownikiem itp.
Nie obserwowaliśmy żadnych znaczników części mowy w tym zdaniu, ale Załóżmy, że tam są. W ten sposób obliczamy prawdopodobieństwo sekwencji znaczników części mowy. W naszym przypadku rzeczywistą sekwencją jest:
PRP-VBP-NN
(gdzie PRP= "zaimek osobisty", VBP= "czasownik, nie-3. osoba liczby pojedynczej obecny", NN= "Rzeczownik, liczba pojedyncza lub masa". Zobacz https://cs.nyu.edu/grishman/jet/guide/PennPOS.html do pełnego zapisu znaczników Penn POS)
Ale czekaj! Jest to sekwencja, którą możemy zastosować Markowa model do. Ale nazywamy to ukrytym, ponieważ Sekwencja części mowy nigdy nie jest bezpośrednio obserwowana. Oczywiście w praktyce obliczymy wiele takich sekwencji i chcielibyśmy znaleźć ukrytą sekwencję, która najlepiej wyjaśnia naszą obserwację (np. częściej widzimy słowa takie jak 'the', 'this', generowane z znacznika determiner (DET))Najlepsze wyjaśnienie, jakie kiedykolwiek spotkałem, znajduje się w artykule z 1989 roku autorstwa Lawrence ' a R. Rabinera: http://www.cs.ubc.ca / ~ murphyk / Bayes / rabiner. pdf
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-07-26 17:19:33
Model Markowa jest maszyną stanową , której zmiany stanu są prawdopodobieństwami. W ukrytym modelu Markowa nie znasz prawdopodobieństwa, ale znasz wyniki.
Na przykład, kiedy rzucasz monetą, możesz uzyskać prawdopodobieństwo, ale jeśli nie widzisz rzutów i ktoś porusza jednym z pięciu palców przy każdym rzucie monetą, możesz wykonać ruchy palcem i użyć ukrytego modelu Markowa, aby uzyskać najlepsze odgadnięcie rzutów monetą.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-25 18:49:59
Ponieważ Matt użył tagów części mowy jako przykładu HMM, Mogę dodać jeszcze jeden przykład: Rozpoznawanie mowy. Prawie wszystkie systemy ciągłego rozpoznawania mowy o dużym słownictwie (lvcsr) są oparte na HMMs.
"Przykład Matta": I enjoy coffee
W modelu Markowa, można oszacować jego prawdopodobieństwo, obliczając:
P(WORD = I) x P(WORD = enjoy | PREVIOUS_WORD = I) x P(word = coffee| PREVIOUS_WORD = enjoy)
W ukrytym modelu Markowa,
Powiedzmy, że 30 różnych osób czyta zdanie"lubię przytulać się" i my muszę to rozpoznać. Każda osoba wymawia to zdanie inaczej. Nie wiemy więc, czy dana osoba miała na myśli "przytulanie " czy"przytulanie". Będziemy mieli tylko probabilistyczny rozkład rzeczywistego słowa.
W skrócie, Ukryty model Markowa jest statystycznym modelem Markowa, w którym modelowany system przyjmuje się za proces Markowa z niezauważonymi (ukrytymi) Stanami.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-02 06:18:17
Ukryte modele Markowa to podwójnie osadzony proces stochastyczny z dwoma poziomami.
Górny poziom jest procesem Markowa, a stany są nieobserwowalne.
W rzeczywistości obserwacja jest funkcją probabilistyczną wyższych stanów Markowa.
Różne stany Markowa będą miały różne funkcje probabilistyczne obserwacji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-10-11 18:05:25
Jak to rozumiem, pytanie brzmi: "jaka jest różnica między procesem Markowa a ukrytym procesem Markowa?"
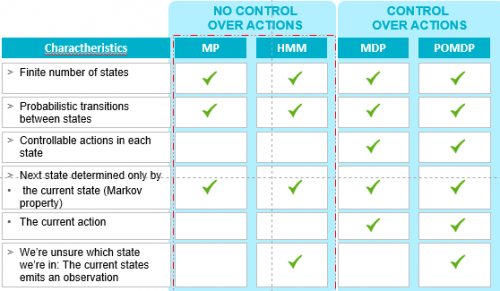
Proces Markowa (MP) jest procesem stochastycznym o skończonej liczbie stanów (1) probabilistycznych przejściach między tymi stanami (3) Następny stan określony tylko przez bieżący stan (własność Markowa)
Ukryty proces Markowa (HMM) jest również procesem stochastycznym (1) skończona liczba stanów (2) probabilistyczne przejścia między tymi stanami (3) Następny stan określony tylko przez bieżący stan (własność Markowa) i (4) nie jesteśmy pewni, w którym stanie jesteśmy: bieżący stan emituje obserwację.
Przykład - (HMM) Giełda:
Na giełdzie ludzie handlują z wartością firmy. Załóżmy, że rzeczywista wartość akcji wynosi $100 (jest to nieobserwowalne, a w rzeczywistości nigdy o tym nie wiesz). To, co naprawdę widzisz, to wartość, z którą jest przedmiotem handlu: Załóżmy, że w tym przypadku 90 USD (jest to obserwowalne).
Dla osób zainteresowanych w Markov: interesujące jest to, kiedy zaczniesz podejmować działania na tych modelach (w poprzednim przykładzie, aby zdobyć pieniądze). Dotyczy to procesów decyzyjnych Markowa (MDP) i częściowo obserwowalnych procesów decyzyjnych Markowa (POMDPs). Aby ocenić ogólną klasyfikację tych modeli, podsumowałem na poniższym zdjęciu główne cechy każdego modelu Markowa.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-06-08 02:13:23