Jakie jest znaczenie load factor w HashMap?
HashMap posiada dwie ważne właściwości: size i load factor. Przejrzałem dokumentację Javy i mówi ona, że 0.75f jest początkowym współczynnikiem obciążenia. Ale nie mogę znaleźć rzeczywistego zastosowania.
Czy ktoś może opisać, jakie są różne scenariusze, w których musimy ustawić współczynnik obciążenia i jakie są przykładowe idealne wartości dla różnych przypadków?
8 answers
Dokumentacja wyjaśnia to całkiem dobrze:
Instancja HashMap ma dwa parametry, które wpływają na jej wydajność: początkową pojemność i współczynnik obciążenia. Pojemność to liczba łyżek w tabeli hash, a pojemność początkowa to po prostu pojemność w momencie tworzenia tabeli hash. Współczynnik obciążenia jest miarą tego, w jaki sposób tabela hash może być pełna, zanim jej pojemność zostanie automatycznie zwiększona. Gdy liczba wpisów w tabeli hash przekroczenie iloczynu współczynnika obciążenia i aktualnej pojemności, tabela hash jest ponownie przerobiona (to znaczy wewnętrzne struktury danych są przebudowywane) tak, że tabela hash ma około dwukrotnie większą liczbę łyżek.
Jako ogólna zasada, domyślny współczynnik obciążenia (.75) oferuje dobry kompromis między kosztami czasu i przestrzeni. Wyższe wartości zmniejszają narzut przestrzeni, ale zwiększają koszty wyszukiwania (odzwierciedlone w większości operacji klasy HashMap, w tym get I put). Oczekiwana liczba zapisy na mapie i jej współczynnik obciążenia powinny być brane pod uwagę przy ustalaniu jej początkowej wydajności, aby zminimalizować liczbę operacji ponownego płukania. Jeśli początkowa pojemność jest większa niż maksymalna liczba wpisów podzielona przez współczynnik obciążenia, nigdy nie zostaną wykonane żadne operacje ponownego ładowania.
Podobnie jak w przypadku wszystkich optymalizacji wydajności, dobrym pomysłem jest unikanie przedwczesnej optymalizacji (tj. bez twardych danych o tym, gdzie są wąskie gardła).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-20 09:12:55
Domyślna początkowa Pojemność HashMap takes to 16, a współczynnik obciążenia to 0.75 f (tj. 75% aktualnego rozmiaru mapy). Współczynnik obciążenia oznacza, na jakim poziomie Pojemność HashMap powinna być podwojona.
Na przykład iloczyn pojemności i współczynnika obciążenia jako 16 * 0.75 = 12. Oznacza to, że po zapisaniu 12. pary klucz-wartość do HashMap, jej pojemność wynosi 32.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-07-24 04:34:23
Właściwie, z moich obliczeń, "idealny" współczynnik obciążenia jest bliższy logowi 2 (~ 0.7). Chociaż każdy współczynnik obciążenia mniejszy niż ten zapewni lepszą wydajność. Tak myślę .75 został prawdopodobnie wyciągnięty z kapelusza.
Dowód:
Można uniknąć łączenia i przewidywania gałęzi wykorzystując przewidywanie, czy wiadro jest puste lub nie. Wiadro jest prawdopodobnie puste, jeśli prawdopodobieństwo jego bycie pustym przekracza .5.
Niech s reprezentują rozmiar, a n liczbę dodanych kluczy. Korzystanie z dwumian twierdzenie, prawdopodobieństwo opróżnienia wiadra wynosi:
P(0) = C(n, 0) * (1/s)^0 * (1 - 1/s)^(n - 0)
Tak więc wiadro jest prawdopodobnie puste, jeśli jest ich mniej niż
log(2)/log(s/(s - 1)) keys
Gdy s osiąga nieskończoność i jeśli liczba dodanych klawiszy jest taka, że P (0) = .5, następnie N / S zbliża się szybko do loga(2):
lim (log(2)/log(s/(s - 1)))/s as s -> infinity = log(2) ~ 0.693...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-11-11 09:55:02
Co to jest współczynnik obciążenia ?
Ilość pojemności, która ma zostać wyczerpana, aby HashMap zwiększył swoją pojemność ?
Dlaczego współczynnik obciążenia ?
Współczynnik obciążenia jest domyślnie 0.75 początkowej pojemności (16), dlatego 25% łyżek będzie wolne, zanim nastąpi wzrost pojemności, co powoduje, że wiele nowych łyżek z nowymi hashcodami wskazuje na nie, aby istniało tuż po zwiększeniu liczby łyżek.
Dlaczego mielibyście zachowaj wiele bezpłatnych łyżek i jaki jest wpływ przechowywania bezpłatnych łyżek na wydajność?
Jeśli ustawisz współczynnik ładowania Na 1.0, wtedy może się zdarzyć coś bardzo interesującego.
Powiedzmy, że dodajesz obiekt x do swojej hashmapy, którego hashCode to 888, a w Twojej hashmapie wiadro reprezentujące hashcode jest wolne, więc obiekt x zostanie dodany do wiadra, ale teraz ponownie powiedz, jeśli dodajesz kolejny obiekt y, którego hashCode to również 888, Twój obiekt y otrzyma dodano na pewno, ale na końcu wiadra (ponieważ wiadra to nic innego jak implementacja linkedList przechowująca klucz, wartość i następny) teraz ma to wpływ na wydajność ! Ponieważ twój obiekt y nie jest już obecny w główce wiadra, jeśli wykonasz wyszukiwanie, czas nie będzie O(1) Tym razem zależy to od tego, ile przedmiotów znajduje się w tym samym wiadrze. Przy okazji nazywa się to kolizją hashową i dzieje się to nawet wtedy, gdy współczynnik ładowania jest mniejszy niż 1.
Korelacja między wydajnością , kolizją hash i współczynnikiem obciążenia ?
Niższy współczynnik obciążenia = więcej wolnych łyżek = mniejsze szanse na kolizję = wysoka wydajność = duże zapotrzebowanie na przestrzeń.
popraw mnie, jeśli gdzieś się mylę.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-09-10 20:17:06
Z dokumentacji:
Współczynnik obciążenia jest miarą tego, jak pełna jest tabela hash, zanim jej pojemność zostanie automatycznie zwiększona
To naprawdę zależy od twoich konkretnych wymagań, nie ma "reguły" określającej Początkowy Współczynnik obciążenia.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-06-05 17:22:47
For HashMap DEFAULT_INITIAL_CAPACITY = 16and DEFAULT_LOAD_FACTOR = 0.75 f
oznacza to, że maksymalna liczba wszystkich wpisów w Hashmapie = 16 * 0.75 = 12. Gdy trzynasty element zostanie dodany pojemność (rozmiar tablicy) HashMap zostanie podwojona!
Doskonała ilustracja odpowiedziała na to pytanie:
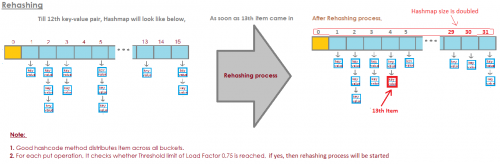 zdjęcie pochodzi stąd:
zdjęcie pochodzi stąd:
Https://javabypatel.blogspot.com/2015/10/what-is-load-factor-and-rehashing-in-hashmap.html
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-04-20 13:22:20
Wybrałbym rozmiar tabeli N * 1.5 lub n + (N > > 1), to dałoby współczynnik obciążenia .66666 ~ bez podziału, który jest powolny w większości systemów, szczególnie w systemach przenośnych, w których nie ma podziału w sprzęcie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-02-16 02:13:15
Jeśli wiadra będą zbyt pełne, musimy przejrzeć
Bardzo długa, powiązana lista.
/ Align = "left" / Oto przykład, w którym mam cztery wiadra.Mam słonia i borsuka w moim HashSet do tej pory.
To całkiem dobra sytuacja, prawda?Każdy element ma zero lub jeden element.
Teraz dodajemy jeszcze dwa elementy do naszego HashSet.
buckets elements
------- -------
0 elephant
1 otter
2 badger
3 cat
Każdy wiadro posiada tylko jeden element . Więc jeśli chcę wiedzieć, czy to zawiera pandę?
Mogę bardzo szybko spojrzeć na wiadro numer 1 i to nie jest
Tam i
Wiem, że nie ma go w naszej kolekcji.If I wanna know if it contains cat, I look at bucket
Numer 3,
Znajduję kota, bardzo szybko wiem, czy jest w naszym
Kolekcja.
A jeśli dodam koalę, to nie jest tak źle.
buckets elements
------- -------
0 elephant
1 otter -> koala
2 badger
3 cat
Może teraz zamiast w wiadrze numer 1 tylko patrząc na
Jeden element,
Muszę spojrzeć na dwa.Ale przynajmniej nie muszę patrzeć na słonia, borsuka i
Cat.
Jeśli znowu Szukam pandy, to może być tylko w wiadrze
Liczba 1 i
Nie muszę patrzeć na nic innego niż wydra i
Koala.Ale teraz włożyłem aligatora do wiadra numer 1 i możesz
Zobacz, dokąd to zmierza.Że jeśli wiadro numer 1 będzie coraz większe i większe oraz
Większy, to w zasadzie muszę przejrzeć wszystkie
Te elementy do znalezienia
Coś, co powinno być w wiadrze numer 1. buckets elements
------- -------
0 elephant
1 otter -> koala ->alligator
2 badger
3 cat
Jeśli zacznę dodawać ciągi do innych wiader,
Racja, problem staje się coraz większy w każdym]}Pojedyncze wiadro.
Jak powstrzymamy nasze wiadra przed zbytnim zapełnieniem?
Rozwiązaniem jest to, że
"the HashSet can automatically
resize the number of buckets."
Jest HashSet getting
Za dużo.Traci tę przewagę nad tym wszystkim dla
Elementy.
I po prostu stworzy więcej wiader (zazwyczaj dwa razy więcej niż wcześniej) i
Następnie umieść elementy w odpowiednim wiadrze.
Oto nasza podstawowa implementacja HashSet z oddzielnym
Łańcuchowanie. Teraz mam zamiar utworzyć "self-zmiana rozmiaru HashSet".
Ten HashSet zda sobie sprawę, że wiadra są
Getting too full oraz
Potrzebuje więcej wiader.LoadFactor to kolejne pole w naszej klasie HashSet.
LoadFactor reprezentuje średnią liczbę elementów na
Wiadro,
Powyżej którego chcemy zmienić rozmiar.
LoadFactor to równowaga między przestrzenią a czasem.Jeśli wiadra będą zbyt pełne, zmienimy rozmiar.
To wymaga czasu, oczywiście, ale
To może zaoszczędzić nam czas na drodze, jeśli wiadra są
Trochę więcej pusty.
Zobaczmy przykład.Oto HashSet, do tej pory dodaliśmy cztery elementy.
Słoń, Pies, Kot i ryba. buckets elements
------- -------
0
1 elephant
2 cat ->dog
3 fish
4
5
W tym momencie zdecydowałem, że the loadFactor, the
Próg,
Średnia liczba elementów na wiadro, że jestem w porządku
Z, wynosi 0,75.
Liczba wiadrów to wiadra.długość, która wynosi 6 i
W tym momencie nasz HashSet ma cztery elementy, więc
Obecny rozmiar to 4.
Zmienimy Rozmiar HashSet, czyli dodamy więcej wiader,
Gdy średnia liczba elementów na wiadro przekracza
The loadFactor.
To jest, gdy obecny rozmiar podzielony przez wiadra.długość to
Większy niż loadFactor.
W tym momencie średnia liczba elementów na wiadro
To 4 podzielone przez 6.
4 żywioły, 6 wiader, czyli 0,67.To mniej niż próg, który ustawiłem na 0,75, więc jesteśmy
Ok. Nie musimy zmieniać rozmiaru.Ale teraz powiedzmy, że dodamy woodchuck.
buckets elements
------- -------
0
1 elephant
2 woodchuck-> cat ->dog
3 fish
4
5
W tym momencie obecny rozmiar to 5.
A teraz średnia liczba elementów na wiadro
Jest aktualnym rozmiarem podzielonym przez wiadra.długość.
To 5 elementów podzielonych przez 6 wiader to 0,83.
I to przekracza loadFactor, który wynosił 0,75.
Aby rozwiązać ten problem, w zlecenie wykonania
Wiadra może trochę
Bardziej puste tak, że operacje takie jak określenie czy
Wiadro zawiera
Element będzie trochę mniej złożony, chcę zmienić rozmiar
Mój HashSet.Zmiana rozmiaru HashSet wymaga dwóch kroków.
Najpierw podwoję liczbę wiader, miałem 6 wiader,
Teraz będę miał 12 wiader.Zauważ tutaj, że loadFactor, który ustawiłem na 0.75 pozostaje taki sam.
Ale liczba zmienionych wiader to 12,
Liczba elementów pozostała taka sama, wynosi 5.
5 podzielone przez 12 to Około 0.42, to dobrze pod naszą
LoadFactor,
Więc już wszystko w porządku.Ale nie skończyliśmy, ponieważ niektóre z tych elementów są w
Nie to wiadro. Na przykład słoń.Słoń był w wiadrze numer 2, ponieważ liczba
Postacie w słoniu
Było 8.
Mamy 6 wiader, 8 minus 6 to 2.
Dlatego znalazł się na 2.Ale teraz, gdy mamy 12 wiader, 8 mod 12 to 8, więc
Słoń nie należy już do wiadra numer 2. Słoń należy do wiadra numer 8. A co z woodchuckiem? Woodchuck był tym, który zaczął cały problem. Woodchuck wylądował w wiadrze numer 3.Ponieważ 9 mod 6 to 3.
Ale teraz robimy 9 mod 12.9 mod 12 to 9, woodchuck idzie do wiadro numer 9.
I widzisz przewagę tego wszystkiego.
Teraz wiadro numer 3 ma tylko dwa elementy, podczas gdy przed miał 3.
Oto nasz kod,
Gdzie mieliśmy nasz HashSet z oddzielnym łańcuchem
Nie zmieniał rozmiaru.
Oto nowa implementacja, w której używamy zmiany rozmiaru.
Większość tego kodu jest taka sama,
Nadal będziemy ustalać, czy zawiera
Wartość już.
Jeśli nie, wtedy dowiemy się, które wiadro to
Powinno wejść i
Następnie dodaj go do tego wiadra, dodaj go do tej LinkedList.
Ale teraz zwiększamy pole currentSize.
CurrentSize było polem, które śledziło liczbę
Elementów w naszym HashSet.
/ Align = "left" / ]}Przy średnim obciążeniu,
Średnia liczba elementów na wiadro.
Zrobimy ten podział tutaj.
Musimy zrobić trochę castingu tutaj, aby upewnić się
Że dostaniemy podwójną.A następnie porównamy to średnie obciążenie z polem
Które ustawiłem jako
0.75 kiedy stworzyłem ten HashSet, na przykład, który był
The loadFactor.
Jeśli średnie obciążenie jest większe od obciążenia,
To oznacza, że na wiadrze jest zbyt wiele elementów
/ Align = "left" /Więc oto nasz wdrożenie metody reinsert
Wszystkie żywioły.Najpierw stworzę lokalną zmienną o nazwie oldBuckets.
Co odnosi się do wiadra, które obecnie stoją
Zanim zacznę zmieniać rozmiar wszystkiego.
Uwaga nie tworzę jeszcze nowej tablicy połączonych list.
Zmieniam nazwę wiadra na oldBuckets.Teraz pamiętaj, wiadra były polem w naszej klasie, idę
Aby utworzyć nową tablicę
Z listy połączone, ale będzie to miało dwa razy więcej elementów
Tak jak za pierwszym razem.Teraz muszę zrobić reinserting,
Przejrzę wszystkie stare wiadra.Każdy element w oldBuckets jest LinkedList łańcuchów
To jest wiadro.Przejdę przez to wiadro i zdobędę każdy element w tym
Wiadro. A teraz wrzucę to do newBuckets.I will get its hashCode.
Dowiem się, który to indeks.
A teraz dostaję nowe wiadro, nową listę LinkedList
Struny i
Dodam do tego nowego wiadra.Podsumowując, Hashsety, jak widzieliśmy, są tablicami połączonych
Listy, czyli wiadra.SELF zmiana rozmiaru HashSet może zrealizować za pomocą pewnego stosunku lub
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-09-27 16:44:26