Parsing HTML using Python
Szukam modułu parsera HTML dla Pythona, który pomoże mi uzyskać tagi w postaci list/słowników/obiektów Pythona.
Jeśli mam dokument w postaci:
<html>
<head>Heading</head>
<body attr1='val1'>
<div class='container'>
<div id='class'>Something here</div>
<div>Something else</div>
</div>
</body>
</html>
To powinno dać mi sposób na dostęp do zagnieżdżonych tagów poprzez nazwę lub id znacznika HTML tak, że mogę w zasadzie poprosić go o dostarczenie mi zawartości/tekstu w znaczniku div z class='container' zawartym w znaczniku body, lub czegoś podobnego.
Jeśli używałeś funkcji "Inspect element" Firefoksa (zobacz HTML) wiedziałbyś, że daje Ci wszystkie tagi w ładny sposób zagnieżdżony jak drzewo.
Wolałbym wbudowany moduł, ale to może być prośba o trochę za dużo.
Przeszedłem przez wiele pytań na Stack Overflow i kilka blogów w Internecie i większość z nich sugerują BeautifulSoup lub lxml lub HTMLParser, ale kilka z nich szczegółowo funkcjonalność i po prostu kończy się debatą nad tym, który z nich jest szybszy/bardziej skuteczny.
7 answers
Tak, że mogę w zasadzie poprosić go, aby mi zawartość / tekst w znaczniku div z class = 'container' zawartym w tagu body, lub coś podobnego.
try:
from BeautifulSoup import BeautifulSoup
except ImportError:
from bs4 import BeautifulSoup
html = #the HTML code you've written above
parsed_html = BeautifulSoup(html)
print parsed_html.body.find('div', attrs={'class':'container'}).text
Nie potrzebujesz opisów występów chyba-poczytaj jak działa BeautifulSoup. Spójrz na jego oficjalną dokumentację .
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-03-04 16:01:22
Chyba szukasz pyquery :
Pyquery: biblioteka podobna do jQuery dla Pythona.
Przykład tego, co chcesz może być jak:
from pyquery import PyQuery
html = # Your HTML CODE
pq = PyQuery(html)
tag = pq('div#id') # or tag = pq('div.class')
print tag.text()
I używa tych samych selektorów co element inspect Firefoksa lub Chrome ' a. Na przykład:
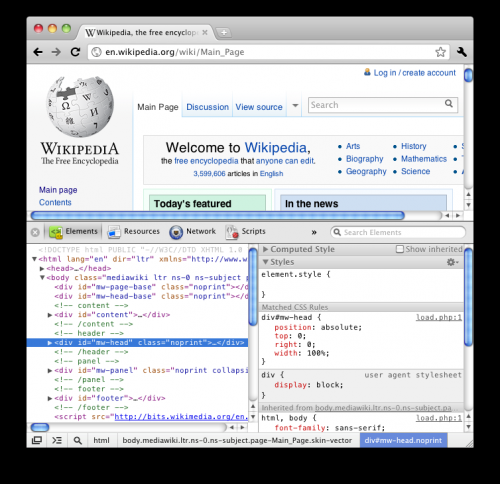
Kontrolowany selektor elementów to ' div#mw-head.noprint". Więc w pyquery wystarczy podać ten selektor:
pq('div#mw-head.noprint')
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-07-19 15:22:35
Tutaj możesz przeczytać więcej o różnych parserach HTML w Pythonie i ich wydajności. Chociaż artykuł jest trochę przestarzały, nadal daje dobry przegląd.
Wydajność parsera HTML w Pythonie
Polecam BeautifulSoup, mimo że nie jest wbudowany. Tylko dlatego, że tak łatwo jest pracować z tego rodzaju zadaniami. Eg:import urllib2
from BeautifulSoup import BeautifulSoup
page = urllib2.urlopen('http://www.google.com/')
soup = BeautifulSoup(page)
x = soup.body.find('div', attrs={'class' : 'container'}).text
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-03-08 16:24:35
W porównaniu z innymi bibliotekami parsera lxml jest niezwykle szybki:
- http://blog.dispatched.ch/2010/08/16/beautifulsoup-vs-lxml-performance/
- http://www.ianbicking.org/blog/2008/03/python-html-parser-performance.html
I z {[2] }jest dość łatwy w użyciu do skrobania stron HTML:
from lxml.html import parse
doc = parse('http://www.google.com').getroot()
for div in doc.cssselect('a'):
print '%s: %s' % (div.text_content(), div.get('href'))
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-11-08 01:21:28
Polecam lxml do parsowania HTML. Zobacz "Parsing HTML" (na stronie lxml).
Z mojego doświadczenia wynika, że piękna zupa psuje jakiś skomplikowany HTML. Wierzę, że to dlatego, że Beautiful Soup nie jest parserem, a bardzo dobrym analizatorem strun.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-10-25 18:50:16
Polecam użycie justext library:
Https://github.com/miso-belica/jusText
Użycie: Python2:
import requests
import justext
response = requests.get("http://planet.python.org/")
paragraphs = justext.justext(response.content, justext.get_stoplist("English"))
for paragraph in paragraphs:
print paragraph.text
Python3:
import requests
import justext
response = requests.get("http://bbc.com/")
paragraphs = justext.justext(response.content, justext.get_stoplist("English"))
for paragraph in paragraphs:
print (paragraph.text)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-07-15 15:51:02
Użyłbym EHP
Oto jest:
from ehp import *
doc = '''<html>
<head>Heading</head>
<body attr1='val1'>
<div class='container'>
<div id='class'>Something here</div>
<div>Something else</div>
</div>
</body>
</html>
'''
html = Html()
dom = html.feed(doc)
for ind in dom.find('div', ('class', 'container')):
print ind.text()
Wyjście:
Something here
Something else
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-03-20 09:44:48