Dlaczego warto wiedzieć o CUDA Warps?
Mam GeForce GTX460 SE, więc jest: 6 SM x 48 rdzeni CUDA = 288 rdzeni CUDA. Wiadomo, że w jednej osnowie zawiera 32 wątki, a w jednym bloku jednocześnie (w czasie) może być wykonywana tylko jedna osnowa. Oznacza to, że w jednym wieloprocesorze (SM) może jednocześnie wykonywać tylko jeden blok, jeden osnowy i tylko 32 wątki, nawet jeśli dostępne są 48 rdzeni?
I dodatkowo, przykład do dystrybucji betonu wątku i bloku może być używany threadIdx.x i blockIdx.x. przydzielić używają jądra > > (). Ale jak przydzielić określoną liczbę Warp-ów i rozprowadzić je, a jeśli nie jest to możliwe, to po co się martwić o Warp?
2 answers
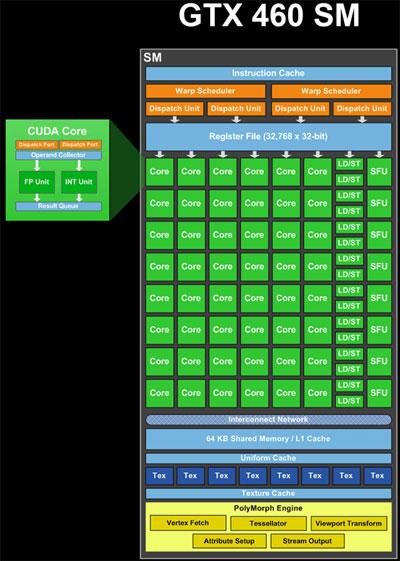
Jednostki Alu( rdzenie), load/store (LD/ST) I Special Function Units (SFU) (zielone na obrazku) są jednostkami pipelined. Przechowują wyniki wielu obliczeń lub operacji w tym samym czasie, na różnych etapach realizacji. Tak więc w jednym cyklu mogą zaakceptować nową operację i dostarczyć wyniki innej operacji, która została rozpoczęta dawno temu (około 20 cykli dla Alu, jeśli pamiętaj poprawnie). Tak więc pojedynczy SM w teorii ma zasoby do przetwarzania 48 * 20 cykli = 960 operacji ALU w tym samym czasie, czyli 960 / 32 wątki na osnowę = 30 wypaczeń. Ponadto może przetwarzać operacje LD / ST i operacje SFU bez względu na ich opóźnienie i przepustowość.
Harmonogram warp (żółty na obrazku) może zaplanować 2 * 32 wątki na warp = 64 wątki do potoków na cykl. Tak więc jest to liczba wyników, które można uzyskać na zegar. Więc, biorąc pod uwagę, że istnieje mieszanka zasobów obliczeniowych, 48 rdzeni, 16 LD/ST, 8 SFU, każdy, który ma różne opóźnienia, mieszanka WARP jest przetwarzana w tym samym czasie. W każdym cyklu planery warp próbują "sparować" dwa warpy, aby zmaksymalizować wykorzystanie SM.
Harmonogram wypaczania może wydawać wypaczenia z różnych bloków lub z różnych miejsc w tym samym bloku, jeśli instrukcje są niezależne. Tak więc wypaczenia z wielu bloków mogą być przetwarzane jednocześnie czas.
Dodając do złożoności, warpy, które wykonują instrukcje, dla których jest mniej niż 32 zasoby, muszą być wydawane wielokrotnie dla wszystkich wątków, które mają być obsługiwane. Na przykład, jest 8 SFUs, więc oznacza to, że warp zawierający instrukcję wymagającą SFUs musi być zaplanowany 4 razy.
Opis ten jest uproszczony. Istnieją również inne ograniczenia, które decydują o tym, w jaki sposób GPU planuje pracę. Możesz znaleźć więcej informacje poprzez wyszukiwanie w sieci "fermi architecture".
Więc, wracając do twojego pytania,]}Dlaczego warto wiedzieć o Warpach?
Znając liczbę wątków w osnowie i biorąc to pod uwagę staje się ważne, gdy próbujesz zmaksymalizować wydajność algorytmu. Jeśli nie przestrzegasz tych zasad, tracisz wydajność:
W wywołaniu jądra,
<<<Blocks, Threads>>>, spróbuj wybrać liczbę wątków, które dzielą się równomiernie z liczba wątków w osnowie. Jeśli tego nie zrobisz, skończysz z uruchomieniem bloku zawierającego nieaktywne wątki.W jądrze staraj się, aby każdy wątek w warp podążał tą samą ścieżką kodu. Jeśli tego nie zrobisz, otrzymasz coś, co nazywa się rozbieżnością warp. Dzieje się tak, ponieważ procesor graficzny musi przepuszczać całą warp przez każdą z rozbieżnych ścieżek kodu.
W jądrze staraj się mieć każdy wątek w WARP load i przechowywać dane w określonych wzorach. Na przykład, mieć wątki w warp mają dostęp do kolejnych 32-bitowych słów w pamięci globalnej.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-08-05 16:26:16
Są wątkami pogrupowanymi w Warpy w kolejności 1 - 32, 33-64 ...?
Tak, model programowania gwarantuje, że wątki są pogrupowane w warpy w określonej kolejności.
Jako prosty przykład optymalizacji rozbieżnych ścieżek kodu można wykorzystać rozdzielenie wszystkich wątków w bloku w grupy 32 wątków? Na przykład: switch (threadIdx.s / 32) {case 0:/* 1 warp * / break; case 1:/* 2 warp * / break; / * Etc */ }
Dokładnie :)
Ile bajtów musi być odczytanych w jednym czasie dla pojedynczej Warp: 4 bajty * 32 wątki, 8 bajtów * 32 wątki lub 16 bajtów * 32 wątki? O ile wiem, jedna transakcja do pamięci globalnej w jednym czasie otrzymuje 128 bajtów.
Tak, transakcje w pamięci globalnej to 128 bajtów. Tak więc, jeśli każdy wątek odczytuje 32-bitowe słowo z kolejnych adresów (prawdopodobnie muszą być również wyrównane 128-bajtowo), wszystkie wątki w warp mogą być obsługiwane z pojedynczą transakcją(4 bajty * 32 wątki = 128 bajtów). Jeśli każdy wątek odczytuje więcej bajtów lub jeśli adresy nie są kolejne, należy wydać więcej transakcji(z osobnymi transakcjami dla każdej osobnej 128-bajtowej linii, która zostanie dotknięta).
Jest to opisane w podręczniku programowania CUDA 4.2, sekcja F. 4. 2, "Pamięć globalna". Jest tam również blurb mówiący, że sytuacja jest inna w przypadku danych, które są buforowane tylko w L2, ponieważ L2 cache ma 32-bajtowe linie cache. Nie wiem jak zorganizować dane do buforowania tylko w L2 lub ile transakcji jeden kończy się z.Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-08-06 02:54:01