W jaki sposób relacje super-i podtyp na diagramach ER są reprezentowane jako tabele?
Uczę się, jak interpretować diagramy relacji encji na wyrażenia SQL DDL i jestem zdezorientowany różnicami w notacji. Rozważmy relację rozłączną jak na poniższym diagramie:
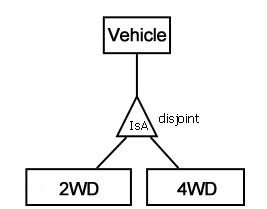
Będzie to reprezentowane jako:
- Pojazdy, tabele 2WD i 4WD (2WD i 4WD wskazywałyby na PK pojazdu); lub
- tylko tabele 2WD i 4WD (i brak tabeli pojazdów), które powielałyby wszelkie atrybuty pojazdu miał?
Myślę, że to są inne sposoby pisania relacji:
Szukam jasnego wyjaśnienia różnicy w odniesieniu do tego, jakie tabele skończy się dla każdego diagramu.
4 answers
Zapis ER
Istnieje kilka zapisów ER. Nie jestem zaznajomiony z tym, którego używasz, ale jest wystarczająco jasne, że próbujesz reprezentować Podtyp (aka. dziedziczenie, Kategoria, podklasa, hierarchia uogólnień...). To jest relacyjny kuzyn dziedziczenia OOP.
Wykonując Podtyp, zazwyczaj zajmujesz się następującymi decyzjami projektowymi:
-
Abstract vs. concrete: czy rodzic może zostać utworzony? W twoim przykładzie: czy
Vehiclemoże istnieć bez również być2WDlub4WD?1 -
Inclusive vs. exclusive: Czy można utworzyć więcej niż jedno dziecko dla tego samego rodzica? W twoim przykładzie, może
Vehiclebyć zarówno2WDi4WD?2 -
kompletny vs. niekompletny: czy spodziewasz się, że więcej dzieci zostanie dodanych w przyszłości? Czy w twoim przykładzie oczekujesz
BikelubPlane(itd...) może być później dodany do modelu bazy danych?
The Notacja inżynierii informacji rozróżnia inkluzywną i wyłączną relację podtypów. Z drugiej strony notacja IDEF1X nie rozpoznaje (bezpośrednio) tej różnicy, ale rozróżnia Podtyp kompletny i niekompletny (którego IE nie rozpoznaje).
Poniższy diagram z ERwin Methods Guide (Rozdział 5, relacje podtypów) ilustruje różnicę:
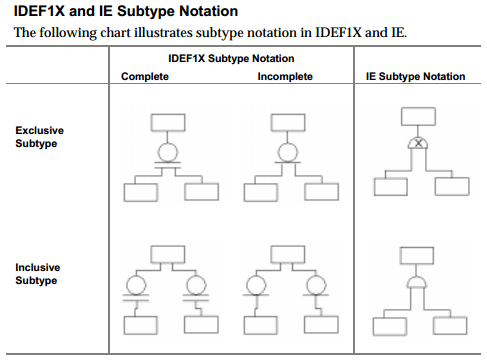
Ani IE, ani IDEF1X nie pozwalają bezpośrednio na określenie abstrakcji vs. konkretny rodzic.
Reprezentacja Fizyczna
Niestety, praktyczne bazy danych nie obsługują bezpośrednio dziedziczenia, więc musisz przekształcić ten diagram do rzeczywistych tabel. Istnieją ogólnie 3 podejścia do tego:
- Umieść wszystkie klasy w tej samej tabeli i pozostaw pola potomne NULL-able. Następnie możesz sprawdzić, czy odpowiedni podzbiór pól jest inny niż NULL.
- plusy: brak łączenia, więc niektóre zapytania mogą skorzystać. Can wymusić klucze poziomu nadrzędnego (np. jeśli chcesz uniknąć różnych Pojazdów
2WDi4WDo tym samym ID). Może łatwo wymusić inclusive vs. exclusive dzieci i abstrakcyjny vs. konkretny rodzic (po prostu zmieniając kontrolę). - wady: niektóre zapytania mogą być wolniejsze, ponieważ muszą odfiltrować" nieciekawe " dzieci. W zależności od DBMS, ograniczenia specyficzne dla dzieci mogą być problematyczne. Wiele Nulli może marnować składowanie. Mniej odpowiednie dla niepełnego podtypu - dodanie nowego dziecka wymaga zmiana istniejącej tabeli, co może być problematyczne w środowisku produkcyjnym.
- plusy: brak łączenia, więc niektóre zapytania mogą skorzystać. Can wymusić klucze poziomu nadrzędnego (np. jeśli chcesz uniknąć różnych Pojazdów
- umieszcza wszystkie dzieci w osobnych tabelach, ale nie ma tabeli dla rodzica (zamiast tego powtarza pola i ograniczenia rodzica we wszystkich dzieciach). Ma większość cech (3), unikając łączenia, za cenę mniejszej możliwości utrzymania (ze względu na wszystkie te powtórzenia pól i ograniczeń) i niemożności wymuszenia kluczy na poziomie nadrzędnym lub reprezentowania konkretnego rodzica.
- Put zarówno rodzic, jak i dzieci w osobnych tabelach.
- Plusy: Czyste. Żadne pola/ograniczenia nie muszą być sztucznie powtarzane. Wymusza klawisze poziomu rodzica i łatwe dodawanie ograniczeń specyficznych dla dzieci. Nadaje się do niepełnego podtypowania (stosunkowo łatwo dodać więcej tabel potomnych). Niektóre zapytania mogą skorzystać, patrząc tylko na "interesujące" tabele(y) potomne.
- wady: niektóre zapytania mogą być join-heavy. Może być trudne do wyegzekwowania inclusive vs. ekskluzywne dzieci i abstrakcyjny vs. konkretny rodzic (mogą być egzekwowane deklaratywnie, jeśli DBMS obsługuje circular i deferred foreign keys, ale egzekwowanie ich na poziomie aplikacji jest zwykle uważane za mniejsze zło).
Jak widzisz, sytuacja jest mniej niż idealna - musisz iść na kompromis, niezależnie od wybranego podejścia. Podejście (3) powinno być prawdopodobnie punktem wyjścia i wybrać tylko jedną z alternatyw, jeśli istnieje przekonujący powód do zrobienia więc.
1 zgaduję, że to właśnie grubość linii oznacza na Twoich diagramach.
2 zgaduję, że to właśnie oznacza obecność lub brak "rozłąki" na waszych diagramach.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-08-20 12:31:12
To, co powiedzieli inni respondenci, plus następujące, które idą do kluczy głównych dla tabel podklasowych.
Twój przypadek wygląda jak przykład wzorca projektowego znanego jako" specjalizacja Generalizacyjna " lub w skrócie Gen-Spec. Pytanie, jak modelować gen-spec za pomocą tabel bazodanowych pojawia się cały czas w SO.
Gdybyś modelował Gen-spec w OOPL, takim jak Java, użyłbyś funkcji dziedziczenia podklasy, aby zająć się szczegółami dla Ciebie. Po prostu zdefiniuj klasę zajmującą się uogólnionymi obiektami, a następnie zdefiniuj zbiór podklas, po jednej dla każdego typu obiektu specjalistycznego. Każda podklasa rozszerzy klasę uogólnioną. To proste i proste.
Niestety relacyjny model danych nie ma wbudowanego dziedziczenia podklas, a systemy bazodanowe SQL nie oferują takiego obiektu, według mojej wiedzy. Ale nie masz pecha. Tabele można zaprojektować tak, aby modelowały modele gen-spec w sposób równoległy struktura klasowa OOP. Następnie musisz zorganizować wdrożenie własnego mechanizmu dziedziczenia, gdy nowe elementy są dodawane do klasy uogólnionej. Szczegóły poniżej.
Struktura klas jest dość prosta, z jedną tabelą dla klasy gen i jedną tabelą dla każdej podklasy spec. Oto fajna ilustracja ze strony Martina Fowlera. Dziedziczenie Tabeli Klas. zauważ, że na tym diagramie Cricketer jest zarówno podklasą, jak i superklasą. Musisz wybrać, które atrybuty w których stolikach. Diagram pokazuje jeden przykładowy atrybut w każdej tabeli.
Trudnym szczegółem jest sposób definiowania kluczy podstawowych dla tych tabel. Tabela klasy gen otrzymuje klucz podstawowy w zwykły sposób (chyba, że ta tabela jest specjalizacją jeszcze innej uogólnienia, np.). Większość projektantów nadaje kluczowi głównemu standardową nazwę, taką jak "Id". Używają funkcji autonumber do wypełnienia pola Id. Tabele klasy spec otrzymują klucz podstawowy, który może być nazwany "Id", ale funkcja autonumber nie jest używana. Zamiast tego klucz podstawowy każdej tabeli podklasy jest ograniczony do odniesienia się do klucza podstawowego tabeli uogólnionej. To sprawia, że każdy z wyspecjalizowanych kluczy podstawowych jest zarówno kluczem obcym, jak i kluczem podstawowym. Należy pamiętać, że w przypadku krykiecistów, pole Id będzie odwoływać się do pola Id w Players, ale pole Id w Bowlers będzie odwoływać się do pola Id w Cricketers.
Teraz, gdy dodajesz nowe elementy, musisz zachować integralność odnośników, Oto jak.
Najpierw wstawiasz nowy wiersz do tabeli gen, dostarczając dane dla wszystkich jej atrybutów, z wyjątkiem klucza podstawowego. Mechanizm autonumber generuje unikalny klucz podstawowy. Następnie wstawiasz nowy wiersz do odpowiedniej tabeli specyfikacji, w tym dane dla wszystkich jej atrybutów, w tym klucz główny. Klucz podstawowy, którego używasz, jest kopią nowo wygenerowanego klucza podstawowego. Tę propagację klucza pierwotnego można nazwać "dziedzictwem ubogiego człowieka".
Teraz kiedy chcesz wszystkie dane uogólnione wraz ze wszystkimi danymi specjalistycznymi z jednej podklasy, wszystko, co musisz zrobić, to połączyć dwie tabele nad wspólnymi kluczami. Wszystkie dane, które nie odnoszą się do podklasy, o której mowa, znikną z join. Jest gładka, łatwa i szybka.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-08-20 17:01:26
Zazwyczaj, gdy wykonujesz relację typu Super-Typ/pod-typ w projekcie bazy danych, musisz utworzyć oddzielną tabelę dla ogólnego typu encji (Super-typ) i oddzielne tabele dla wyspecjalizowanych wersji encji (pod-Typ), które są wyłączone lub nie. W Twoim przypadku musisz utworzyć tabelę dla pojazdu i klucza podstawowego oraz niektóre atrybuty, które są wspólne lub wspólne dla wszystkich podtypów. Następnie musisz utworzyć oddzielne tabele dla 2WD i 4WD wraz z określonymi atrybutami tylko do tych stołów. Na przykład

Następnie możesz odpytywać te tabele za pomocą łączników SQL
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-12-31 09:18:11
Nie zawsze jest tylko jeden sposób implementacji konkretnego modelu danych. Często zachodzi transformacja, która następuje po przejściu z modelu logicznego do modelu fizycznego.
Standardowy SQL nie ma czystego sposobu na wymuszenie disjoint ograniczeń podtypu.
Jeśli twoim celem jest wyegzekwowanie jak największej liczby reguł modelu za pomocą schematu, to standardowym podejściem do implementacji modelu jest użycie tabeli dla supertype i po jednej dla każdego z podtypy. Zapewnia to, że dla każdej jednostki używane są tylko odpowiednie atrybuty.
Istnieje mniej lub bardziej standardowa sztuczka SQL służąca do wymuszania ograniczenia rozłącznego. Zniechęca niektórych ludzi, ponieważ narusza zasady normalizacji w nieistotny sposób. Mimo to, niektórzy uważają technikę za estetycznie obraźliwą, ponieważ istnieje techniczne naruszenie 2NF.
Ta technika polega na dodaniu atrybutu partycjonowania do supertype i włączeniu tego partycjonowania atrybut w każdym podtypie, dodając go do klucza głównego podtypu. Wraz z ograniczeniami sprawdzania, które nakładają określone wartości dla atrybutów partycjonowania, zapewnia to, że każda jednostka może mieć co najwyżej jeden podtyp. Technika jest szczegółowo udokumentowana w wielu miejscach, takich jak ten blog .
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-08-20 12:30:23