Jak działa RecursiveIteratorIterator w PHP?
Jak działa RecursiveIteratorIterator?
Podręcznik PHP nie ma nic udokumentowanego ani wyjaśnionego. Jaka jest różnica między IteratorIterator A RecursiveIteratorIterator?
4 answers
RecursiveIteratorIterator jest betonem Iterator implementacja trawersowania drzewa . Pozwala programistom na poruszanie się po obiekcie kontenera, który implementuje interfejs RecursiveIterator, zobacz Iterator w Wikipedii, gdzie znajdują się ogólne zasady, typy, semantyka i wzorce iteratorów.
In different to IteratorIterator która jest konkretną Iterator realizacją obiektów w porządku liniowym (i domyślnie przyjmującą każdy rodzaj Traversable w konstruktorze), RecursiveIteratorIterator pozwala na zapętlenie wszystkich węzłów w uporządkowanym drzewie obiektów, a jego konstruktor przyjmuje RecursiveIterator.
W skrócie: RecursiveIteratorIterator pozwala na zapętlenie drzewa, IteratorIterator pozwala na zapętlenie listy. Pokażę to w kilku przykładach kodu poniżej.
Technicznie działa to poprzez zerwanie z liniowości przez przemierzanie wszystkich dzieci węzłów (jeśli takie istnieją). Jest to możliwe, ponieważ z definicji wszystkie dzieci węzła są ponownie RecursiveIterator. Na toplevel Iterator następnie wewnętrznie układa różne RecursiveIterator s według ich głębokości i utrzymuje wskaźnik do bieżącego aktywnego sub Iterator dla trawersalu.
Pozwala to na odwiedzenie wszystkich węzłów drzewa.
Podstawowe zasady są takie same jak w IteratorIterator: interfejs określa typ iteracji, a podstawowa klasa iteratora jest implementacją tych semantyki. Porównaj z poniższymi przykładami, dla pętli liniowej z foreach zwykle nie myślisz o implementacja wiele szczegółów, chyba że trzeba zdefiniować nowy Iterator (np. gdy jakiś konkretny typ nie implementuje Traversable).
Dla rekurencyjnego trawersu-chyba że nie używasz predefiniowanego Traversal, który ma już rekurencyjną iterację trawersu - Zwykle musisz utworzyć instancję istniejącej iteracji RecursiveIteratorIterator lub nawet napisać rekurencyjną iterację trawersu, która jest Traversable twoją własną, aby mieć tego typu iterację trawersu z foreach.
Wskazówka: prawdopodobnie nie wdrożyłeś ani jednego, ani drugiego własnego, więc może to być coś, co warto zrobić dla praktycznego doświadczenia różnic, które mają. Na końcu odpowiedzi znajdziesz sugestię DIY.
Różnice techniczne w skrócie:
- podczas gdy
IteratorIteratorzajmuje dowolneTraversabledla ruchu liniowego,RecursiveIteratorIteratorpotrzebuje bardziej szczegółowegoRecursiveIterator, aby pętla wokół drzewa. - gdzie
IteratorIteratorujawnia swoją głównąIteratorpoprzezgetInnerIerator(),RecursiveIteratorIteratordostarcza aktualną aktywną sub -Iteratortylko za pomocą tej metody. - podczas gdy
IteratorIteratornie jest świadomy niczego takiego jak rodzic lub dzieci,RecursiveIteratorIteratorwie, jak zdobyć i przemierzać dzieci, jak również. -
IteratorIteratornie potrzebuje stosu iteratorów,RecursiveIteratorIteratorma taki stos i zna aktywny pod-iterator. - gdzie
IteratorIteratorma swój porządek ze względu na liniowość i brak wyboru,RecursiveIteratorIteratorma wybór do dalszego trawersowania i musi decydować na każdy węzeł (decyduje tryb naRecursiveIteratorIterator). -
RecursiveIteratorIteratorma więcej metod niżIteratorIterator.
Podsumowując: RecursiveIterator to konkretny rodzaj iteracji (zapętlenia drzewa), która działa na własnych iteratorach, a mianowicie RecursiveIterator. Jest to ta sama podstawowa zasada, co w przypadku IteratorIerator, ale Typ iteracji jest inny (kolejność liniowa).
Idealnie możesz stworzyć swój własny zestaw. Jedyną konieczną rzeczą jest to, że Twój iterator implementuje Traversable, co jest możliwe poprzez Iterator lub IteratorAggregate. Wtedy możesz użyj go z foreach. Na przykład pewnego rodzaju obiekt iteracji rekurencyjnej w drzewie trójdzielnym wraz z interfejsem iteracji dla obiektu(obiektów) kontenera (kontenerów).
Przyjrzyjmy się przykładom z prawdziwego życia, które nie są tak abstrakcyjne. Między interfejsami, konkretnymi iteratorami, obiektami kontenerów i semantyką iteracji to może nie jest taki zły pomysł.
Weźmy jako przykład listę katalogów. Rozważ, że masz następujące drzewo plików i katalogów na dysku:
Iterator o kolejności liniowej przemieszcza się po folderze toplevel i plikach (lista pojedynczych katalogów), natomiast iterator rekurencyjny przemieszcza się również przez podfoldery i wyświetla listę wszystkich folderów i plików (Lista katalogów z listami jego podkatalogów):
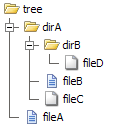
Non-Recursive Recursive
============= =========
[tree] [tree]
├ dirA ├ dirA
└ fileA │ ├ dirB
│ │ └ fileD
│ ├ fileB
│ └ fileC
└ fileA
Można łatwo porównać to z IteratorIterator, który nie wykonuje rekursji dla przemierzania drzewa katalogów. I RecursiveIteratorIterator, które mogą trawersować w drzewo jak pokazuje lista rekurencyjna.
Na początku bardzo podstawowy przykład z DirectoryIterator że realizuje Traversable co pozwala foreach to iterate over it:
$path = 'tree';
$dir = new DirectoryIterator($path);
echo "[$path]\n";
foreach ($dir as $file) {
echo " ├ $file\n";
}
Przykładowe wyjście dla powyższej struktury katalogów to:
[tree]
├ .
├ ..
├ dirA
├ fileA
Jak widzisz to nie jest jeszcze za pomocą IteratorIterator lub RecursiveIteratorIterator. Zamiast tego po prostu używa foreach, który działa na interfejsie Traversable.
As foreach domyślnie zna tylko Typ iteracji nazwanej porządkiem liniowym, możemy chcieć jawnie określić typ iteracji. Na pierwszy rzut oka może to wydawać się zbyt gadatliwe, ale dla celów demonstracyjnych (i aby różnica z RecursiveIteratorIterator bardziej widoczna później), pozwala określić liniowy Typ iteracji jawnie określając typ iteracji IteratorIterator dla listy katalogów:
$files = new IteratorIterator($dir);
echo "[$path]\n";
foreach ($files as $file) {
echo " ├ $file\n";
}
Ten przykład jest prawie identyczny z pierwszym, różnica polega na tym, że $files jest teraz typem IteratorIterator iteracja dla Traversable $dir:
$files = new IteratorIterator($dir);
Jak zwykle czynność iteracji wykonuje foreach:
foreach ($files as $file) {
Wyjście jest dokładnie to samo. Czym się różni? Inny jest obiekt używany w foreach. W pierwszym przykładzie jest to DirectoryIterator w drugim przykładzie jest to IteratorIterator. To pokazuje elastyczność iteratorów: można je zastąpić sobą, kod wewnątrz foreach po prostu kontynuować pracę zgodnie z oczekiwaniami.
Lets start to get the cała lista, łącznie z podkatalogami.
Ponieważ teraz określiliśmy Typ iteracji, rozważmy zmianę jej na inny typ iteracji.
Wiemy, że musimy teraz przejść całe drzewo, nie tylko pierwszy poziom. Aby mieć taką pracę z prostym foreach, potrzebujemy innego typu iteratora: RecursiveIteratorIterator. I że można tylko iterować nad obiektami kontenera, które mają RecursiveIterator interfejs .
Interfejs jest kontraktem. Dowolne Klasa implementująca to może być używana razem z RecursiveIteratorIterator. Przykładem takiej klasy jest RecursiveDirectoryIterator, co jest czymś w rodzaju rekurencyjnego wariantu DirectoryIterator.
Zobaczmy pierwszy przykład kodu przed napisaniem innego zdania ze słowem I:
$dir = new RecursiveDirectoryIterator($path);
echo "[$path]\n";
foreach ($dir as $file) {
echo " ├ $file\n";
}
Ten trzeci przykład jest prawie identyczny z pierwszym, jednak tworzy inny wynik:
[tree]
├ tree\.
├ tree\..
├ tree\dirA
├ tree\fileA
OK, nie tak różnie, nazwa pliku zawiera teraz ścieżkę w przód, ale reszta też wygląda podobnie.
Jak pokazuje przykład, nawet obiekt directory jest już połączony z interfejsem RecursiveIterator, to jeszcze nie wystarczy, aby foreach przemierzał całe drzewo katalogów. W tym miejscu RecursiveIteratorIterator zaczyna działać. przykład 4 pokazuje jak:
$files = new RecursiveIteratorIterator($dir);
echo "[$path]\n";
foreach ($files as $file) {
echo " ├ $file\n";
}
Użycie RecursiveIteratorIterator zamiast tylko poprzedniego $dir spowoduje, że foreach będzie przemierzać wszystkie pliki i katalogi w sposób rekurencyjny. Następnie wyświetla wszystkie pliki, jako Typ iteracji obiektu został określony teraz:
[tree]
├ tree\.
├ tree\..
├ tree\dirA\.
├ tree\dirA\..
├ tree\dirA\dirB\.
├ tree\dirA\dirB\..
├ tree\dirA\dirB\fileD
├ tree\dirA\fileB
├ tree\dirA\fileC
├ tree\fileA
To powinno już wykazać różnicę między trawersem płaskim A drzewnym. {[19] } jest w stanie przemierzać dowolną strukturę przypominającą drzewo jako listę elementów. Ponieważ jest więcej informacji (jak poziom, na którym obecnie odbywa się iteracja), można uzyskać dostęp do obiektu iterator podczas iteracji nad nim i na przykład wciąć wyjście:
echo "[$path]\n";
foreach ($files as $file) {
$indent = str_repeat(' ', $files->getDepth());
echo $indent, " ├ $file\n";
}
I wyjście przykład 5:
[tree]
├ tree\.
├ tree\..
├ tree\dirA\.
├ tree\dirA\..
├ tree\dirA\dirB\.
├ tree\dirA\dirB\..
├ tree\dirA\dirB\fileD
├ tree\dirA\fileB
├ tree\dirA\fileC
├ tree\fileA
Jasne, że to nie wygra konkursu piękności, ale pokazuje, że z iteratorem rekurencyjnym jest więcej dostępnych informacji niż tylko kolejność liniowa klucza i wartości . Nawet foreach może wyrazić tylko ten rodzaj liniowości, dostęp do iteratora pozwala uzyskać więcej informacji.
Podobnie jak meta-informacje, istnieją również różne sposoby poruszania się po drzewie i tym samym porządkowania danych wyjściowych. To jest na Mode of the RecursiveIteratorIterator i można go ustawić za pomocą konstruktora.
Następny przykład powie RecursiveDirectoryIterator, aby usunąć wpisy z kropkami (. i ..), ponieważ ich nie potrzebujemy. Ale również tryb rekurencji zostanie zmieniony tak, aby element nadrzędny (podkatalog) był pierwszy (SELF_FIRST) przed potomkami (pliki i podkatalog w podkatalogu):
$dir = new RecursiveDirectoryIterator($path, RecursiveDirectoryIterator::SKIP_DOTS);
$files = new RecursiveIteratorIterator($dir, RecursiveIteratorIterator::SELF_FIRST);
echo "[$path]\n";
foreach ($files as $file) {
$indent = str_repeat(' ', $files->getDepth());
echo $indent, " ├ $file\n";
}
Wyjście pokazuje wpisy podkatalogu poprawnie wymienione, jeśli porównasz z poprzedni wynik tych nie było:
[tree]
├ tree\dirA
├ tree\dirA\dirB
├ tree\dirA\dirB\fileD
├ tree\dirA\fileB
├ tree\dirA\fileC
├ tree\fileA
-
LEAVES_ONLY(domyślnie): tylko listy plików, bez katalogów. -
SELF_FIRST(powyżej): Lista katalogów, a następnie pliki tam. -
CHILD_FIRST(w / O przykład): najpierw Wyświetla listę plików w podkatalogu, a następnie katalogu.
Wyjście przykład 5 z dwoma inne tryby:
LEAVES_ONLY CHILD_FIRST
[tree] [tree]
├ tree\dirA\dirB\fileD ├ tree\dirA\dirB\fileD
├ tree\dirA\fileB ├ tree\dirA\dirB
├ tree\dirA\fileC ├ tree\dirA\fileB
├ tree\fileA ├ tree\dirA\fileC
├ tree\dirA
├ tree\fileA
Kiedy porównasz to ze standardowym trawersem, wszystkie te rzeczy nie są dostępne. Iteracja rekurencyjna jest więc nieco bardziej skomplikowana, gdy trzeba ją ogarnąć, jednak jest łatwa w użyciu, ponieważ zachowuje się jak iterator, wkładasz go do foreach i gotowe.
Myślę, że to wystarczająco dużo przykładów na jedną odpowiedź. Możesz znaleźć Pełny kod źródłowy, a także przykład wyświetlania ładnie wyglądających drzew ascii w tym gist: https://gist.github.com/3599532
zrób to sam: wykonaj
RecursiveTreeIteratorpracę linia po linii.
przykład 5 wykazał, że dostępne są meta-informacje o stanie iteratora. Jednak zostało to celowo zademonstrowane w iteracji foreach. W prawdziwym życiu to naturalnie należy do RecursiveIterator.
Lepszym przykładem jest RecursiveTreeIterator, it takes care wcięcia, prefiksu i tak dalej. Zobacz następujący fragment kodu:
$dir = new RecursiveDirectoryIterator($path, RecursiveDirectoryIterator::SKIP_DOTS);
$lines = new RecursiveTreeIterator($dir);
$unicodeTreePrefix($lines);
echo "[$path]\n", implode("\n", iterator_to_array($lines));
{[110] } jest przeznaczony do pracy linia po linii, wyjście jest dość proste z jednym małym problemem:
[tree]
├ tree\dirA
│ ├ tree\dirA\dirB
│ │ └ tree\dirA\dirB\fileD
│ ├ tree\dirA\fileB
│ └ tree\dirA\fileC
└ tree\fileA
W połączeniu z RecursiveDirectoryIterator wyświetla całą ścieżkę, a nie tylko nazwę pliku. Reszta wygląda dobrze. Dzieje się tak dlatego, że nazwy plików są generowane przez SplFileInfo. Powinny one być wyświetlane jako nazwy podstawowe. Pożądanym wyjściem jest po:
/// Solved ///
[tree]
├ dirA
│ ├ dirB
│ │ └ fileD
│ ├ fileB
│ └ fileC
└ fileA
Utwórz klasę dekoratora, która może być używana z RecursiveTreeIterator zamiast RecursiveDirectoryIterator. Powinna ona zawierać nazwę podstawową bieżącego SplFileInfo zamiast nazwy ścieżki. Ostateczny fragment kodu może wtedy wyglądać następująco:
$lines = new RecursiveTreeIterator(
new DiyRecursiveDecorator($dir)
);
$unicodeTreePrefix($lines);
echo "[$path]\n", implode("\n", iterator_to_array($lines));
Te fragmenty, w tym $unicodeTreePrefix są częścią gist w dodatek: zrób to sam: wykonaj RecursiveTreeIterator praca linia po linii..
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-09-02 22:24:46
Jaka jest różnica między
IteratorIteratoriRecursiveIteratorIterator?
Aby zrozumieć różnicę między tymi dwoma iteratorami, należy najpierw zrozumieć trochę o używanych konwencjach nazewniczych i o tym, co rozumiemy przez Iteratory "rekurencyjne".
Iteratory rekurencyjne i nie rekurencyjne
PHP ma nie - "rekurencyjne" Iteratory, takie jak ArrayIterator i FilesystemIterator. Istnieją również Iteratory "rekurencyjne", takie jak RecursiveArrayIterator i RecursiveDirectoryIterator. Te ostatnie mają metody umożliwiające ich wiercenie w dół, te pierwsze nie.
Gdy instancje tych iteratorów są zapętlone samodzielnie, nawet rekurencyjne, wartości pochodzą tylko z "górnego" poziomu, nawet jeśli są zapętlone nad zagnieżdżoną tablicą lub katalogiem z podkatalogami.
Iteratory rekurencyjne implementują zachowanie rekurencyjne (poprzez hasChildren(), getChildren()) ale nie wykorzystuj tego.
Może lepiej pomyśleć o iteratorach rekurencyjnych jako iteratorach "rekurencyjnych", mają one zdolność do iteracji rekurencyjnej, ale po prostu iteracja nad instancją jednej z tych klas tego nie zrobi. Aby wykorzystać rekurencyjne zachowanie, Czytaj dalej.
RecursiveIteratorIterator
To tutaj RecursiveIteratorIterator wchodzi do gry. Posiada wiedzę o tym, jak wywoływać Iteratory "rekurencyjne" w taki sposób, aby wwiercić się w strukturę w normalnej, płaskiej pętli. Wprowadza rekurencyjne zachowanie w działanie. Zasadniczo wykonuje pracę stepping nad każdą z wartości w iteratorze, sprawdzając, czy istnieją "dzieci" do rekurencji, czy nie, i wchodząc do i z tych kolekcji dzieci. Przyklejasz instancję RecursiveIteratorIterator do foreach, aona zanurza się w strukturze, abyś nie musiał.
Jeśli RecursiveIteratorIterator nie został użyty, musiałbyś napisać własne pętle rekurencyjne, aby wykorzystać rekurencyjne zachowanie, sprawdzając w stosunku do iteratora" recursible " hasChildren() i używając getChildren().
Więc to a krótki przegląd RecursiveIteratorIterator, Czym się różni od IteratorIterator? Zadajesz to samo pytanie co Jaka jest różnica między kotkiem a drzewkiem? tylko dlatego, że oba pojawiają się w tej samej encyklopedii (lub podręczniku, dla iteratorów), nie oznacza, że powinieneś się mylić między tymi dwoma.
IteratorIterator
Zadaniem IteratorIterator jest wzięcie dowolnego Traversable obiektu i zawinięcie go w taki sposób, aby spełniał on interfejs Iterator. A use for this jest wtedy w stanie zastosować zachowanie specyficzne dla iteratora na obiekcie innym niż iterator.
Aby dać praktyczny przykład, DatePeriod klasa jest Traversable, ale nie Iterator. Jako takie, możemy zapętlać jego wartości za pomocą foreach(), ale nie możemy robić innych rzeczy, które normalnie zrobilibyśmy z iteratorem, takich jak filtrowanie.
Zadanie: pętla w poniedziałki, środy i piątki w ciągu najbliższych czterech tygodni.
tak, jest to trywialne przez foreach - ing nad DatePeriod i za pomocą if() W pętli; ale nie o to chodzi w tym przykładzie!
$period = new DatePeriod(new DateTime, new DateInterval('P1D'), 28);
$dates = new CallbackFilterIterator($period, function ($date) {
return in_array($date->format('l'), array('Monday', 'Wednesday', 'Friday'));
});
foreach ($dates as $date) { … }
Powyższy fragment nie zadziała, ponieważ CallbackFilterIterator oczekuje instancji klasy, która implementuje interfejs Iterator, a DatePeriod Nie działa. Ponieważ jednak jest Traversable, możemy łatwo spełnić ten wymóg używając IteratorIterator.
$period = new IteratorIterator(new DatePeriod(…));
Jak widzisz, nie ma to nic wspólnego z iteracją nad klasami iteratorowymi ani z rekurencją, i w tym tkwi różnica między IteratorIterator a RecursiveIteratorIterator.
Podsumowanie
RecursiveIteraratorIterator jest do iteracji przez RecursiveIterator ("recursible" iterator), wykorzystując dostępne rekurencyjne zachowanie.
IteratorIterator jest do stosowania zachowania Iterator do obiektów nie-iteratora, Traversable.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-09-02 14:39:32
RecursiveDirectoryIterator wyświetla całą ścieżkę, a nie tylko nazwę pliku. Reszta wygląda dobrze. Dzieje się tak, ponieważ nazwy plików są generowane przez SplFileInfo. Powinny one być wyświetlane jako nazwy podstawowe. Pożądane wyjście jest następujące:
$path =__DIR__;
$dir = new RecursiveDirectoryIterator($path, FilesystemIterator::SKIP_DOTS);
$files = new RecursiveIteratorIterator($dir,RecursiveIteratorIterator::SELF_FIRST);
while ($files->valid()) {
$file = $files->current();
$filename = $file->getFilename();
$deep = $files->getDepth();
$indent = str_repeat('│ ', $deep);
$files->next();
$valid = $files->valid();
if ($valid and ($files->getDepth() - 1 == $deep or $files->getDepth() == $deep)) {
echo $indent, "├ $filename\n";
} else {
echo $indent, "└ $filename\n";
}
}
Wyjście:
tree
├ dirA
│ ├ dirB
│ │ └ fileD
│ ├ fileB
│ └ fileC
└ fileA
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-10-11 09:14:12
W przypadku stosowania z iterator_to_array(), RecursiveIteratorIterator będzie rekurencyjnie chodził po tablicy, aby znaleźć wszystkie wartości. Co oznacza, że spłaszczy oryginalną tablicę.
IteratorIterator zachowa oryginalną strukturę hierarchiczną.
Ten przykład pokaże ci wyraźnie różnicę:
$array = array(
'ford',
'model' => 'F150',
'color' => 'blue',
'options' => array('radio' => 'satellite')
);
$recursiveIterator = new RecursiveIteratorIterator(new RecursiveArrayIterator($array));
var_dump(iterator_to_array($recursiveIterator, true));
$iterator = new IteratorIterator(new ArrayIterator($array));
var_dump(iterator_to_array($iterator,true));
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-08-30 20:56:22