Lista a Mapa
Czy Jest jakiś powód, aby preferować użycie map() zamiast rozumienia listy czy odwrotnie? Czy któraś z nich jest na ogół bardziej wydajna lub uważana za ogólnie bardziej pythoniczną od drugiej?
12 answers
map może być mikroskopowo szybszy w niektórych przypadkach(gdy nie tworzysz lambda do tego celu, ale używasz tej samej funkcji w map i listcomp). W innych przypadkach składanie List może być szybsze i większość (nie wszystkie) pythonistów uważa je za bardziej bezpośrednie i jaśniejsze.
Przykład małej przewagi prędkości map przy użyciu dokładnie tej samej funkcji:
$ python -mtimeit -s'xs=range(10)' 'map(hex, xs)'
100000 loops, best of 3: 4.86 usec per loop
$ python -mtimeit -s'xs=range(10)' '[hex(x) for x in xs]'
100000 loops, best of 3: 5.58 usec per loop
$ python -mtimeit -s'xs=range(10)' 'map(lambda x: x+2, xs)'
100000 loops, best of 3: 4.24 usec per loop
$ python -mtimeit -s'xs=range(10)' '[x+2 for x in xs]'
100000 loops, best of 3: 2.32 usec per loop
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-08-07 23:45:23
Przypadki
- typowy przypadek : prawie zawsze będziesz chciał używać rozumienia listy w Pythonie, ponieważ będzie bardziej oczywiste, co robisz początkującym programistom czytającym Twój kod. (Nie dotyczy to innych języków, w których mogą obowiązywać inne idiomy.) Będzie nawet bardziej oczywiste, co robisz programistom Pythona, ponieważ składanie list jest de facto standardem w Pythonie dla iteracji; są oczekiwane .
-
mniej powszechny przypadek: jednak jeśli już masz zdefiniowaną funkcję , często rozsądne jest użycie
map, choć jest uważane za "niepytoniczne". Na przykładmap(sum, myLists)jest bardziej elegancki / zwięzły niż[sum(x) for x in myLists]. Zyskujesz elegancję, że nie musisz tworzyć fałszywej zmiennej (np.sum(x) for x...lubsum(_) for _...lubsum(readableName) for readableName...), którą musisz wpisać dwa razy, tylko po to, aby iterację. Ten sam argument dotyczyfilterireduceoraz wszystkiego z modułuitertools: jeśli już mieć funkcję pod ręką, można iść do przodu i zrobić trochę programowania funkcjonalnego. Zyskuje to czytelność w niektórych sytuacjach, a traci ją w innych (np. początkujący Programiści, wiele argumentów)... ale czytelność Twojego kodu w dużej mierze zależy od twoich komentarzy. -
prawie nigdy : możesz używać funkcji
mapjako czystej abstrakcyjnej funkcji podczas programowania funkcyjnego, gdzie mapujeszmap, lub curryingmap, lub w inny sposób korzystać z mówienia omapjako funkcja. Na przykład w Haskell interfejs functora o nazwiefmapuogólnia mapowanie na dowolną strukturę danych. Jest to bardzo rzadkie w Pythonie, ponieważ gramatyka Pythona zmusza cię do używania stylu generatora do mówienia o iteracji; nie możesz go łatwo uogólnić. (Czasami jest to dobre, a czasami złe.) Prawdopodobnie możesz wymyślić rzadkie przykłady Pythona, gdziemap(f, *lists)jest rozsądną rzeczą do zrobienia. Najbliższy przykład, jaki mogę wymyślić, tosumEach = partial(map,sum), który jest jednowierszowcem, który jest bardzo mniej więcej równoważne:
def sumEach(myLists):
return [sum(_) for _ in myLists]
-
Po prostu używając
for- loop : Możesz również oczywiście użyć for-loop. Chociaż nie jest tak elegancki z punktu widzenia programowania funkcyjnego, czasami zmienne nielokalne czynią kod bardziej przejrzystym w imperatywnych językach programowania, takich jak python, ponieważ ludzie są bardzo przyzwyczajeni do czytania kodu w ten sposób. Pętle For są również, ogólnie, najbardziej wydajne, gdy wykonujesz tylko dowolną skomplikowaną operację, która nie buduje list like list-comprehensions i map są zoptymalizowane pod kątem (np. sumowania, tworzenia drzewa itp.) -- przynajmniej wydajny pod względem pamięci (niekoniecznie pod względem czasu, gdzie w najgorszym wypadku spodziewałbym się stałego czynnika, pomijając rzadką patologiczną czkawkę zbierania śmieci).
"Pytonizm"
Nie lubię słowa "pythonic", ponieważ nie uważam, że pythonic jest zawsze elegancki w moich oczach. Niemniej jednak, map i filter i podobne funkcje (jak bardzo użyteczny moduł itertools) są prawdopodobnie uważane za niepytoniczne pod względem stylu.
Lenistwo
Pod względem wydajności, podobnie jak większość konstrukcji programowania funkcyjnego, mapa może być leniwa , a w rzeczywistości jest leniwa w Pythonie. Oznacza to, że możesz to zrobić (w python3), a na twoim komputerze nie zabraknie pamięci i utracisz wszystkie niezapisane dane:
>>> map(str, range(10**100))
<map object at 0x2201d50>
Spróbuj to zrobić ze zrozumieniem listy:
>>> [str(n) for n in range(10**100)]
# DO NOT TRY THIS AT HOME OR YOU WILL BE SAD #
Zwróć uwagę, że lista są również z natury leniwe, ale python zdecydował się zaimplementować je jako nie-leniwe . Mimo to python obsługuje składanie leniwych list w postaci wyrażeń generatora, w następujący sposób:
>>> (str(n) for n in range(10**100))
<generator object <genexpr> at 0xacbdef>
Można zasadniczo myśleć o składni [...] jako przekazaniu w wyrażeniu generatora do konstruktora listy, jak list(x for x in range(5)).
Krótki przykład
from operator import neg
print({x:x**2 for x in map(neg,range(5))})
print({x:x**2 for x in [-y for y in range(5)]})
print({x:x**2 for x in (-y for y in range(5))})
Składanie List nie jest leniwe, więc może wymagać więcej pamięci (chyba że używasz generatora comprehensions). Nawiasy kwadratowe [...] często sprawiają, że rzeczy są oczywiste, zwłaszcza gdy w bałaganie nawiasów. Z drugiej strony, czasami kończy się to gadatliwością, jak pisanie [x for x in.... Tak długo, jak długo zmienne iteratora są krótkie, składanie list jest zwykle bardziej przejrzyste, jeśli nie wcięcie kodu. Ale zawsze możesz wciąć swój kod.
print(
{x:x**2 for x in (-y for y in range(5))}
)
Lub rozbijać rzeczy:
rangeNeg5 = (-y for y in range(5))
print(
{x:x**2 for x in rangeNeg5}
)
Porównanie wydajności dla python3
map jest teraz leniwy:
% python3 -mtimeit -s 'xs=range(1000)' 'f=lambda x:x' 'z=map(f,xs)'
1000000 loops, best of 3: 0.336 usec per loop ^^^^^^^^^
dlatego jeśli nie wykorzystasz wszystkich swoich danych lub nie wiesz z wyprzedzeniem, ile Danych potrzebujesz, map W python3 (i wyrażeniach generatora w python2 lub python3) unikniesz obliczania ich wartości do ostatniej niezbędnej chwili. Zazwyczaj to zwykle przeważa nad kosztami wynikającymi z użycia map. Minusem jest to, że jest to bardzo ograniczone w Pythonie w przeciwieństwie do większości języków funkcyjnych: zyskujesz tę korzyść tylko wtedy, gdy masz dostęp do danych od lewej do prawej "w kolejności", ponieważ wyrażenia generatora Pythona można oceniać tylko w kolejności x[0], x[1], x[2], ....
Powiedzmy jednak, że mamy przygotowaną funkcję f, którą chcielibyśmy map, i ignorujemy lenistwo map, wymuszając natychmiast ewaluację za pomocą list(...). Otrzymujemy bardzo ciekawe wyniki:
% python3 -mtimeit -s 'xs=range(1000)' 'f=lambda x:x' 'z=list(map(f,xs))'
10000 loops, best of 3: 165/124/135 usec per loop ^^^^^^^^^^^^^^^
for list(<map object>)
% python3 -mtimeit -s 'xs=range(1000)' 'f=lambda x:x' 'z=[f(x) for x in xs]'
10000 loops, best of 3: 181/118/123 usec per loop ^^^^^^^^^^^^^^^^^^
for list(<generator>), probably optimized
% python3 -mtimeit -s 'xs=range(1000)' 'f=lambda x:x' 'z=list(f(x) for x in xs)'
1000 loops, best of 3: 215/150/150 usec per loop ^^^^^^^^^^^^^^^^^^^^^^
for list(<generator>)
W wynikach są w postaci AAA / BBB / CCC, gdzie A zostało wykonane z na circa-2010 Intel workstation z Pythonem 3.?.?, A B I C wykonano z AMD ok. workstation with python 3.2.1, with extremely different hardware. Rezultatem wydaje się być to, że składanie map i list jest porównywalne pod względem wydajności, na co najsilniej wpływają inne czynniki losowe. Jedyną rzeczą, którą możemy powiedzieć, wydaje się być to, że o dziwo, podczas gdy oczekujemy, że składanie list [...] będzie działać lepiej niż wyrażenia generatora (...), map jest również bardziej wydajne niż wyrażenia generatora (ponownie zakładając, że wszystkie wartości są oceniane/używane).
To ważne uświadomienie sobie, że testy te zakładają bardzo prostą funkcję( funkcję tożsamościową); jednak jest to w porządku, ponieważ gdyby funkcja była skomplikowana, to narzut wydajności byłby znikomy w porównaniu do innych czynników w programie. (Może nadal być interesujące przetestowanie z innymi prostymi rzeczami, takimi jak f=lambda x:x+x)
Jeśli jesteś wprawny w czytaniu zestawu Pythona, możesz użyć modułu dis, aby sprawdzić, czy to jest naprawdę to, co dzieje się za sceny:
>>> listComp = compile('[f(x) for x in xs]', 'listComp', 'eval')
>>> dis.dis(listComp)
1 0 LOAD_CONST 0 (<code object <listcomp> at 0x2511a48, file "listComp", line 1>)
3 MAKE_FUNCTION 0
6 LOAD_NAME 0 (xs)
9 GET_ITER
10 CALL_FUNCTION 1
13 RETURN_VALUE
>>> listComp.co_consts
(<code object <listcomp> at 0x2511a48, file "listComp", line 1>,)
>>> dis.dis(listComp.co_consts[0])
1 0 BUILD_LIST 0
3 LOAD_FAST 0 (.0)
>> 6 FOR_ITER 18 (to 27)
9 STORE_FAST 1 (x)
12 LOAD_GLOBAL 0 (f)
15 LOAD_FAST 1 (x)
18 CALL_FUNCTION 1
21 LIST_APPEND 2
24 JUMP_ABSOLUTE 6
>> 27 RETURN_VALUE
>>> listComp2 = compile('list(f(x) for x in xs)', 'listComp2', 'eval')
>>> dis.dis(listComp2)
1 0 LOAD_NAME 0 (list)
3 LOAD_CONST 0 (<code object <genexpr> at 0x255bc68, file "listComp2", line 1>)
6 MAKE_FUNCTION 0
9 LOAD_NAME 1 (xs)
12 GET_ITER
13 CALL_FUNCTION 1
16 CALL_FUNCTION 1
19 RETURN_VALUE
>>> listComp2.co_consts
(<code object <genexpr> at 0x255bc68, file "listComp2", line 1>,)
>>> dis.dis(listComp2.co_consts[0])
1 0 LOAD_FAST 0 (.0)
>> 3 FOR_ITER 17 (to 23)
6 STORE_FAST 1 (x)
9 LOAD_GLOBAL 0 (f)
12 LOAD_FAST 1 (x)
15 CALL_FUNCTION 1
18 YIELD_VALUE
19 POP_TOP
20 JUMP_ABSOLUTE 3
>> 23 LOAD_CONST 0 (None)
26 RETURN_VALUE
>>> evalledMap = compile('list(map(f,xs))', 'evalledMap', 'eval')
>>> dis.dis(evalledMap)
1 0 LOAD_NAME 0 (list)
3 LOAD_NAME 1 (map)
6 LOAD_NAME 2 (f)
9 LOAD_NAME 3 (xs)
12 CALL_FUNCTION 2
15 CALL_FUNCTION 1
18 RETURN_VALUE
Wydaje się, że lepiej używać składni [...] niż list(...). Niestety klasa map jest trochę nieprzejrzysta do demontażu, ale możemy zrobić to dzięki naszemu testowi prędkości.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-05-15 13:27:57
Python 2: powinieneś używać map i filter zamiast składania list.
A obiektywny powód, dla którego powinieneś je preferować, mimo że nie są "Pythoniczne" jest taki:
Wymagają funkcji / lambda jako argumentów, które wprowadzają nowy zakres .
Zostałem ugryziony przez to nie raz:
for x, y in somePoints:
# (several lines of code here)
squared = [x ** 2 for x in numbers]
# Oops, x was silently overwritten!
Ale gdybym zamiast tego powiedział:
for x, y in somePoints:
# (several lines of code here)
squared = map(lambda x: x ** 2, numbers)
Można powiedzieć, że byłem głupi, że używałem ta sama nazwa zmiennej w tym samym zakresie.
Nie byłem. kod był w porządku pierwotnie -- dwa x nie były w tym samym zakresie.
Problem pojawił się dopiero po tym, jak przeniosłem wewnętrzny blok do innej sekcji kodu (Czytaj: problem podczas konserwacji, a nie Rozwoju) i nie spodziewałem się tego.
Tak, jeśli nigdy nie popełnisz tego błędu wtedy zestawienie listy jest bardziej eleganckie.
Ale z osobistego doświadczenia (i z widzenia innych popełnij ten sam błąd) widziałem, że zdarzyło się to wystarczająco dużo razy, że myślę, że nie jest warte bólu, przez który musisz przejść, gdy te błędy wkradają się do Twojego kodu.
Wniosek:
Użyj map i filter. Zapobiegają subtelnym trudnym do zdiagnozowania błędom związanym z zakresem.
Uwaga boczna:
Nie zapomnij rozważyć użycie imap i ifilter (W itertools), jeśli są odpowiednie dla twojej sytuacji!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-20 09:12:55
Właściwie, map i składanie list zachowuje się zupełnie inaczej w języku Python 3. Spójrz na następujący program Python 3:
def square(x):
return x*x
squares = map(square, [1, 2, 3])
print(list(squares))
print(list(squares))
Można oczekiwać, że wyświetli linię "[1, 4, 9]" dwa razy, ale zamiast tego wyświetli " [1, 4, 9]", a następnie "[]". Za pierwszym razem squares wygląda na to, że zachowuje się jak ciąg trzech elementów, ale za drugim jako pusty.
W języku Python 2 map zwraca zwykłą starą listę, podobnie jak składanie list w oba języki. Najważniejsze jest to, że wartość zwracana map w Pythonie 3 (i imap w Pythonie 2) nie jest listą - jest iteratorem!
Elementy są zużywane podczas iteracji nad iteratorem, w przeciwieństwie do iteracji nad listą. Dlatego squares wygląda pusto w ostatniej linii print(list(squares)).
Podsumowując:
- mając do czynienia z iteratorami musisz pamiętać, że są one stateczne i że mutują podczas ich przemieszczania się.
- listy są bardziej są przewidywalne, ponieważ zmieniają się tylko wtedy, gdy wyraźnie je mutujesz; są to kontenery.
- i bonus: liczby, ciągi i krotki są jeszcze bardziej przewidywalne, ponieważ w ogóle nie mogą się zmienić; są to wartości .
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-12-02 18:52:28
Jeśli planujesz pisać dowolny kod asynchroniczny, równoległy lub rozproszony, prawdopodobnie wolisz map niż rozumienie listy - ponieważ większość pakietów asynchronicznych, równoległych lub rozproszonych dostarcza map funkcję przeciążającą map Pythona. Następnie przekazując odpowiednią funkcję map do reszty kodu, może nie być konieczne modyfikowanie oryginalnego kodu seryjnego, aby działał równolegle (etc).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-06-08 17:03:13
Uważam, że składanie listy jest na ogół bardziej wyraziste niż map - obie to robią , ale ta pierwsza oszczędza psychicznego obciążenia próbującego zrozumieć, co może być złożonym wyrażeniem lambda.
Jest też gdzieś wywiad (nie mogę go znaleźć od ręki), gdzie Guido wymienia lambdas i funkcje funkcyjne jako rzecz, której najbardziej żałuje, że akceptuje w Pythonie, więc można wysnuć argument, że są one nie-Pythoniczne z racji to.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-08-07 23:59:05
Oto jeden możliwy przypadek:
map(lambda op1,op2: op1*op2, list1, list2)
Kontra:
[op1*op2 for op1,op2 in zip(list1,list2)]
Domyślam się, że zip() jest niefortunnym i niepotrzebnym obciążeniem, które musisz sobie poświęcić, jeśli nalegasz na używanie zestawień list zamiast mapy. Byłoby świetnie, gdyby ktoś to wyjaśnił, czy to twierdząco, czy negatywnie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-08-03 21:33:19
Więc od Pythona 3, map() jest iteratorem, musisz pamiętać czego potrzebujesz: iteratora lub list obiektu.
Jak już wspomniał @AlexMartelli , map() jest szybsze niż zrozumienie listy tylko wtedy, gdy nie używasz funkcji lambda.
Przedstawię Ci kilka porównań czasowych.
Python 3.5.2 i CPython
użyłem Jupiter notebook a szczególnie %timeit wbudowana Magia dowództwo
pomiary : s = = 1000 ms = = 1000 * 1000 µs = 1000 * 1000 * 1000 ns
Konfiguracja:
x_list = [(i, i+1, i+2, i*2, i-9) for i in range(1000)]
i_list = list(range(1000))
Wbudowana funkcja:
%timeit map(sum, x_list) # creating iterator object
# Output: The slowest run took 9.91 times longer than the fastest.
# This could mean that an intermediate result is being cached.
# 1000000 loops, best of 3: 277 ns per loop
%timeit list(map(sum, x_list)) # creating list with map
# Output: 1000 loops, best of 3: 214 µs per loop
%timeit [sum(x) for x in x_list] # creating list with list comprehension
# Output: 1000 loops, best of 3: 290 µs per loop
lambda funkcja:
%timeit map(lambda i: i+1, i_list)
# Output: The slowest run took 8.64 times longer than the fastest.
# This could mean that an intermediate result is being cached.
# 1000000 loops, best of 3: 325 ns per loop
%timeit list(map(lambda i: i+1, i_list))
# Output: 1000 loops, best of 3: 183 µs per loop
%timeit [i+1 for i in i_list]
# Output: 10000 loops, best of 3: 84.2 µs per loop
Istnieje również coś takiego jak wyrażenie generatora, zobacz PEP-0289 . Więc pomyślałem, że przydałoby się dodać go do porównania
%timeit (sum(i) for i in x_list)
# Output: The slowest run took 6.66 times longer than the fastest.
# This could mean that an intermediate result is being cached.
# 1000000 loops, best of 3: 495 ns per loop
%timeit list((sum(x) for x in x_list))
# Output: 1000 loops, best of 3: 319 µs per loop
%timeit (i+1 for i in i_list)
# Output: The slowest run took 6.83 times longer than the fastest.
# This could mean that an intermediate result is being cached.
# 1000000 loops, best of 3: 506 ns per loop
%timeit list((i+1 for i in i_list))
# Output: 10000 loops, best of 3: 125 µs per loop
Potrzebujesz list obiektu:
Use list comprehension if it ' s custom function, use list(map()) if there is builtin function
Nie potrzebujesz list obiektu, potrzebujesz tylko iterowalnego:
Zawsze używaj map()!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 11:47:31
Przeprowadziłem szybki test porównujący trzy metody wywołania metody obiektu. Różnica czasu w tym przypadku jest znikoma i jest kwestią danej funkcji(zobacz odpowiedź @ Alex Martelli ). Tutaj przyjrzałem się następującym metodom:
# map_lambda
list(map(lambda x: x.add(), vals))
# map_operator
from operator import methodcaller
list(map(methodcaller("add"), vals))
# map_comprehension
[x.add() for x in vals]
Spojrzałem na listy (przechowywane w zmiennej vals) zarówno liczb całkowitych (Python int), jak i liczb zmiennoprzecinkowych (Python float) w celu zwiększenia rozmiarów list. Następująca Klasa DummyNum to "considered": {]}
class DummyNum(object):
"""Dummy class"""
__slots__ = 'n',
def __init__(self, n):
self.n = n
def add(self):
self.n += 5
W szczególności metoda add. Atrybut __slots__ jest prostą optymalizacją w Pythonie do zdefiniowania całkowitej pamięci potrzebnej klasie (atrybutów), zmniejszając rozmiar pamięci.
Oto powstałe działki.
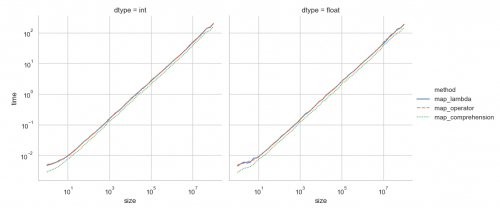
Jak wspomniano wcześniej, zastosowana technika robi minimalną różnicę i powinieneś kodować w sposób najbardziej czytelny dla Ciebie lub w konkretnych okolicznościach. W tym przypadku lista (map_comprehension) jest najszybszy dla obu typów dodatków w obiekcie, zwłaszcza przy krótszych listach.
Odwiedź ten pastebin dla źródła używanego do generowania wykresu i danych.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-07-19 00:43:08
Próbowałem kodu przez @ alex-martelli, ale znalazłem pewne rozbieżności
python -mtimeit -s "xs=range(123456)" "map(hex, xs)"
1000000 loops, best of 5: 218 nsec per loop
python -mtimeit -s "xs=range(123456)" "[hex(x) for x in xs]"
10 loops, best of 5: 19.4 msec per loop
Mapa zajmuje tyle samo czasu, nawet dla bardzo dużych zakresów, podczas gdy używanie rozumienia list zajmuje dużo czasu, co wynika z mojego kodu. Tak więc, poza tym, że zostałem uznany za "niepythoniczny", nie miałem do czynienia z żadnymi problemami z wydajnością związanymi z używaniem map.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-12-16 04:35:00
Uważam, że najbardziej Pythonicznym sposobem jest użycie rozumienia listy zamiast map i filter. Powodem jest to, że składanie list jest jaśniejsze niż map i filter.
In [1]: odd_cubes = [x ** 3 for x in range(10) if x % 2 == 1] # using a list comprehension
In [2]: odd_cubes_alt = list(map(lambda x: x ** 3, filter(lambda x: x % 2 == 1, range(10)))) # using map and filter
In [3]: odd_cubes == odd_cubes_alt
Out[3]: True
Jak widzicie, rozumienie nie wymaga dodatkowych lambda wyrażeń, jakich potrzebuje map. Co więcej, Zrozumienie pozwala również na łatwe filtrowanie, podczas gdy map wymaga filter, aby umożliwić filtrowanie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-09-11 19:26:00

Źródło Obrazu: Experfy
Możesz sam zobaczyć, co jest lepsze między-listą a funkcją Map
(zrozumienie listy zajmuje mniej czasu, aby przetworzyć 1 milion rekordów w porównaniu z funkcją mapy)
Mam nadzieję, że to pomoże! Powodzenia:)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2021-01-14 16:44:23