Co tak naprawdę znaczą wskaźniki Clustered i Non clustered?
Mam ograniczoną ekspozycję na DB i używałem DB tylko jako programisty aplikacji. Chcę wiedzieć o Clustered i Non clustered indexes.
Wygooglowałem i znalazłem:
indeks klastrowy to specjalny rodzaj indeksu, który zmienia kolejność rekordy w tabeli są fizycznie przechowywany. Dlatego tabela może mieć tylko jeden klastrowy indeks. Węzły liściowe z klastrowego indeksu zawierają dane stron. Indeks niezakłócony to specjalny rodzaj indeksu, w którym logiczne kolejność indeksu nie dopasuj fizyczną przechowywaną kolejność wiersze na dysku. Węzeł liścia a indeks niezakłócony nie składa się z strony z danymi. Zamiast tego liść węzły zawierają wiersze indeksu.
To, co znalazłem w SO, to jakie są różnice między indeksem klastrowym a nie klastrowym?.
Czy ktoś może to wyjaśnić po angielsku?9 answers
W przypadku indeksu klastrowego wiersze są fizycznie przechowywane na dysku w tej samej kolejności co indeks. Dlatego może być tylko jeden klastrowy indeks.
W przypadku indeksu bez klastra istnieje druga lista, która zawiera wskaźniki do wierszy fizycznych. Możesz mieć wiele nieklastrowanych indeksów, chociaż każdy nowy indeks zwiększy czas potrzebny na zapis nowych rekordów.
Ogólnie szybszy jest odczyt z klastrowego indeksu, jeśli chcesz odzyskać wszystkie kolumny. Nie masz aby przejść najpierw do indeksu, a następnie do tabeli.
Zapis do tabeli z klastrowym indeksem może być wolniejszy, jeśli zachodzi potrzeba zmiany kolejności danych.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-07-06 19:34:12
Klastrowy indeks oznacza, że każesz bazie danych przechowywać bliskie wartości faktycznie blisko siebie na dysku. Ma to tę zaletę, że Szybkie skanowanie / pobieranie rekordów wchodzących w pewien zakres wartości klastrowych indeksu.
Na przykład, masz dwie tabele, klienta i zamówienia:
Customer
----------
ID
Name
Address
Order
----------
ID
CustomerID
Price
Jeśli chcesz szybko odzyskać wszystkie zamówienia jednego konkretnego klienta, możesz utworzyć klastrowy indeks w kolumnie "CustomerID" tabeli zamówień. W ten sposób rekordy z tym samym CustomerID będą fizycznie przechowywane blisko siebie na dysku (klastrowane), co przyspiesza ich pobieranie.
P. S. indeks na CustomerID oczywiście nie będzie unikalny, więc albo musisz dodać drugie pole do "unifikowania" indeksu, albo pozwolić bazie danych zająć się tym za ciebie, ale to już inna historia.
W odniesieniu do wielu indeksów. Możesz mieć tylko jeden klastrowy indeks na tabelę, ponieważ określa to, w jaki sposób dane są fizycznie ułożone. Jeśli chcesz analogię, wyobraź sobie duży pokój z wieloma stołami w nim. Stoły można umieścić w kilku rzędach lub połączyć je w jeden duży stół konferencyjny, ale nie w obie strony jednocześnie. Tabela może mieć inne indeksy, będą one następnie wskazywać na wpisy w indeksie klastrowym, który z kolei w końcu powie, gdzie znaleźć rzeczywiste dane.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-08-25 22:14:51
W Sql Server row oriented storage zarówno klastrowe, jak i niezaklustrowane indeksy są zorganizowane jako drzewa B.
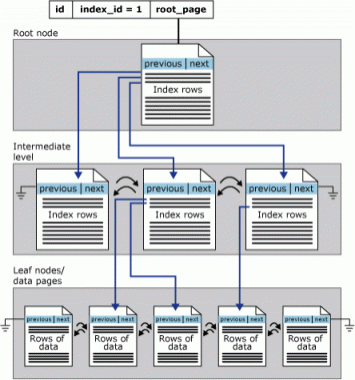
Kluczową różnicą między indeksami klastrowymi a indeksami nieklastrowymi jest to, że poziom liścia indeksu klastrowego jest tabelą. Ma to dwa implikacje.
- wiersze na stronach klastrowych indeksów zawsze zawierają coś dla każdej z (nierzadkich) kolumn w tabela (albo wartość, albo wskaźnik do rzeczywistej wartości).
- klastrowy indeks jest podstawową kopią tabeli.
Indeksy niezaklustrowane mogą również wykonać punkt 1, używając klauzuli INCLUDE (od SQL Server 2005) do jawnego włączenia wszystkich kolumn niekluczowych, ale są one drugorzędnymi reprezentacjami i zawsze jest inna kopia danych wokół (sama tabela).
CREATE TABLE T
(
A INT,
B INT,
C INT,
D INT
)
CREATE UNIQUE CLUSTERED INDEX ci ON T(A,B)
CREATE UNIQUE NONCLUSTERED INDEX nci ON T(A,B) INCLUDE (C,D)
Dwa powyższe indeksy będą prawie identyczne. Ze stronami indeksu górnego poziomu zawiera wartości dla kolumn kluczowych A,B i stron poziomu liścia zawierających A,B,C,D
W tabeli może być tylko jeden klastrowy indeks, ponieważ wiersze danych same mogą być sortowane tylko w jednej kolejności.
Powyższy cytat z SQL Server books online powoduje wiele zamieszania
Moim zdaniem byłoby to znacznie lepiej sformułowane jako.
W tabeli może być tylko jeden indeks klastrowy, ponieważ wiersze liścia indeksu klastrowego to wiersze tabeli.
Cytat książki online nie jest nieprawidłowy, ale powinieneś być jasny, że "sortowanie" zarówno Nie klastrowych i klastrowych indeksów jest logiczne, a nie fizyczne. Jeśli czytasz strony na poziomie liścia, postępując zgodnie z linkowaną listą i czytasz wiersze na stronie w kolejności tablicy szczelin, to będziesz czytać wiersze indeksu w kolejności posortowanej, ale fizycznie strony mogą nie być sortowane. Powszechnie panujące przekonanie, że przy klastrowym indeksie wiersze są zawsze przechowywane fizycznie na dysku w tej samej kolejności co indeks klucz jest false.
To byłaby absurdalna realizacja. Na przykład, jeśli wiersz jest wstawiony do środka tabeli 4GB, SQL Server nie musi kopiować 2GB danych do pliku, aby zrobić miejsce dla nowo wstawionego wiersza .Zamiast tego następuje podział strony. Każda strona na poziomie liścia zarówno klastrowych, jak i nie klastrowych indeksów ma adres (File:Page) następnej i poprzedniej strony w kluczu logicznym spokój. Strony te nie muszą być ani sąsiadujące ze sobą, ani uporządkowane według klucza.
Np. łańcuch linkowanych stron może być 1:2000 <-> 1:157 <-> 1:7053
Gdy następuje podział strony, nowa strona jest przydzielana z dowolnego miejsca w grupie plików(z zakresu mieszanego, dla małych tabel, lub nie pustego jednolitego zakresu należącego do tego obiektu lub nowo przydzielonego jednolitego zakresu). Może to nie być nawet w tym samym pliku, jeśli grupa plików zawiera więcej niż jeden.
Stopień, w jakim porządek logiczny i zbieżność różni się od wyidealizowanej wersji fizycznej stopniem fragmentacji logicznej.
W nowo utworzonej bazie danych z jednym plikiem wykonałem następujące czynności.
CREATE TABLE T
(
X TINYINT NOT NULL,
Y CHAR(3000) NULL
);
CREATE CLUSTERED INDEX ix
ON T(X);
GO
--Insert 100 rows with values 1 - 100 in random order
DECLARE @C1 AS CURSOR,
@X AS INT
SET @C1 = CURSOR FAST_FORWARD
FOR SELECT number
FROM master..spt_values
WHERE type = 'P'
AND number BETWEEN 1 AND 100
ORDER BY CRYPT_GEN_RANDOM(4)
OPEN @C1;
FETCH NEXT FROM @C1 INTO @X;
WHILE @@FETCH_STATUS = 0
BEGIN
INSERT INTO T (X)
VALUES (@X);
FETCH NEXT FROM @C1 INTO @X;
END
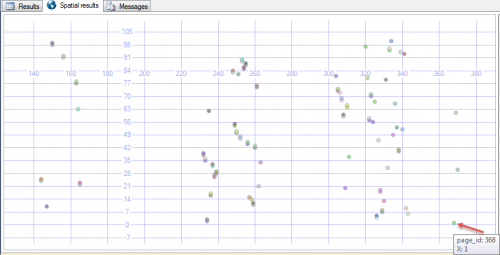
Następnie zaznaczono układ strony za pomocą
SELECT page_id,
X,
geometry::Point(page_id, X, 0).STBuffer(1)
FROM T
CROSS APPLY sys.fn_PhysLocCracker( %% physloc %% )
ORDER BY page_id
Wyniki były wszędzie. Pierwszy wiersz w kolejności klawiszy (z wartością 1 - podświetloną strzałką poniżej) znajdował się na prawie ostatniej stronie fizycznej.
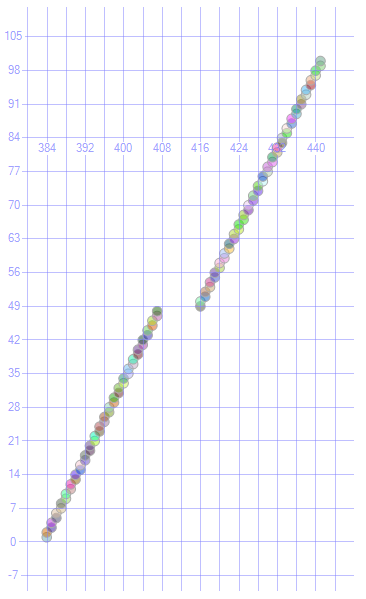
Fragmentacja może być zmniejszona lub usunięta poprzez przebudowę lub reorganizację indeks zwiększający korelację między porządkiem logicznym a porządkiem fizycznym.
Po uruchomieniu
ALTER INDEX ix ON T REBUILD;
Mam następujące
Jeśli tabela nie ma klastrowego indeksu, nazywa się to stertą.
Indeksy nieklasterowane mogą być budowane na stercie lub na indeksie klastrowym. Zawsze zawierają lokalizator wierszy z powrotem do tabeli podstawowej. W przypadku sterty jest to fizyczny identyfikator wiersza (rid) i składa się z trzech komponentów (File:Page:Slot). W w przypadku indeksu klastrowego lokalizator wierszy jest logiczny(klucz indeksu klastrowego).
W tym drugim przypadku, jeśli indeks nieklastrowany zawiera już naturalnie kolumny klucza CI jako kolumny klucza NCI lub INCLUDE - D, to nic nie jest dodawane. W przeciwnym razie brakujące kolumny klawiszy CI zostaną po cichu dodane do NCI.
SQL Server zawsze zapewnia, że kolumny kluczowe są unikalne dla obu typów indeksów. Mechanizm, w którym jest to wymuszane dla indeksów Nie zadeklarowanych jako unique różni się jednak między dwoma typami indeksów.
Indeksy klastrowe otrzymują uniquifier dodane dla dowolnych wierszy z wartościami klucza, które powielają istniejący wiersz. To tylko rosnąca liczba całkowita.
Dla indeksów nieklasyfikowanych nie zadeklarowanych jako unique SQL Server po cichu dodaje lokalizator wierszy do klucza indeksu nieklasyfikowanego. Dotyczy to wszystkich wierszy, a nie tylko tych, które są faktycznie duplikatami.
Nomenklatura clustered vs non clustered jest również używana do przechowywania kolumn indeksy. W artykule rozszerzenia kolumn SQL Server przechowują Stany
Chociaż dane magazynu kolumn nie są tak naprawdę "grupowane" na żadnym kluczu, my postanowiło zachować tradycyjną konwencję SQL Server polegającą na odwołaniu do indeksu podstawowego jako indeksu klastrowego.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-01-07 14:43:52
Zdaję sobie sprawę, że to bardzo stare pytanie, ale pomyślałem, że zaproponuję analogię, która pomoże zilustrować dobre odpowiedzi powyżej.
CLUSTERED INDEX
Jeśli wejdziesz do Biblioteki Publicznej, zobaczysz, że wszystkie książki są ułożone w określonej kolejności (najprawdopodobniej system dziesiętny Deweya lub DDS). Odpowiada to "indeksowi grupowemu" ksiąg. Jeśli DDS# dla książki, którą chcesz był 005.7565 F736s, możesz zacząć od zlokalizowania rzędu półek z książkami, który jest oznaczony Czy coś w tym stylu. (Ten znak endcap na końcu stosu odpowiada "węźle pośrednim" w indeksie.) W końcu przewierciłbyś się do określonej półki oznaczonej 005.7450 - 005.7600, następnie skanowałbyś, aż znalazłeś książkę z określonym DDS#, i w tym momencie znalazłeś swoją książkę.
INDEKS BEZKLASOWY
Ale gdybyś nie przyszedł do biblioteki z DDS# swojej książki zapamiętanej, wtedy potrzebowałbyś drugiego indeksu, aby ci pomóc. W w dawnych czasach można było znaleźć przed biblioteką wspaniałe Biuro szuflad znane jako "katalog kart". W nim były tysiące kart 3x5 - po jednej dla każdej książki, posortowane w porządku alfabetycznym (być może według tytułu). Odpowiada to "indeksie bezklasowym" . Te katalogi kart zostały zorganizowane w hierarchiczną strukturę, tak aby każda szuflada była oznaczona zakresem kart, które zawierała (Ka - Kl, na przykład; tj. "węzeł pośredni"). Po raz kolejny wierciłbyś w dopóki nie znalazłeś swojej książki, ale w tym przypadku, gdy już ją znalazłeś (tj. "węzeł liścia"), nie masz samej książki, ale tylko kartę z numerem index (DDS#), za pomocą której możesz znaleźć faktyczną książkę w indeksie klastrowym.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-11-03 17:43:46
Poniżej znajdziesz kilka cech indeksów klastrowych i nieklastrowych:
Indeksy Klastrowe
- indeksy klastrowe to indeksy, które jednoznacznie identyfikują wiersze w tabeli SQL.
- każda tabela może mieć dokładnie jeden klastrowy indeks.
- możesz utworzyć indeks klastrowy, który obejmuje więcej niż jedną kolumnę. Na przykład:
create Index index_name(col1, col2, col.....). - domyślnie kolumna z kluczem głównym ma już klastrowy indeks.
Non-clustered Indeksy
- Nieklasowane indeksy są jak proste indeksy. Są one po prostu używane do szybkiego pobierania danych. Nie jestem pewien, czy masz unikalne dane.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-07-10 00:22:19
Bardzo prostą, nietechniczną zasadą byłoby, że klastrowe indeksy są zwykle używane dla klucza podstawowego (lub przynajmniej unikalnej kolumny) i że nieklastrowe są używane w innych sytuacjach (może klucz obcy). Rzeczywiście, SQL Server domyślnie utworzy klastrowy indeks w kolumnie(kolumnach) klucza głównego. Jak już się nauczyłeś, klastrowy indeks odnosi się do sposobu fizycznego sortowania danych na dysku, co oznacza, że jest to dobry wszechstronny wybór w większości sytuacji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-08-09 16:17:21
Clustered Index
Indeks klastrowy określa fizyczną kolejność danych w tabeli.Z tego powodu tabela ma tylko 1 klastrowy indeks.
Podobnie jak "słownik" nie ma potrzeby stosowania żadnego innego indeksu, jego indeks już według słów
Nonclustered Index
Nieklasowany indeks jest analogiczny do indeksu w książce.Dane są przechowywane w jednym miejscu. na indeks jest przechowywany w innym miejscu, a indeks ma wskaźniki do miejsca przechowywania data.Z tego powodu tabela ma więcej niż 1 niezakłócony indeks.
Podobnie jak " książka chemiczna "w staring jest oddzielny indeks wskazujący lokalizację rozdziału, a na" końcu " jest inny indeks wskazujący lokalizację wspólnych słów
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-01-21 18:47:09
Clustered Index
Indeksy klastrowe sortują i przechowują wiersze danych w tabeli lub widoku na podstawie ich kluczowych wartości. Są to kolumny zawarte w definicji indeksu. W tabeli może być tylko jeden klastrowany indeks, ponieważ same wiersze danych mogą być sortowane tylko w jednej kolejności.
Wiersze danych w tabeli są przechowywane w posortowanej kolejności tylko wtedy, gdy tabela zawiera indeks klastrowy. Gdy tabela ma indeks klastrowy, tabela jest nazywana klastrowy stół. Jeśli tabela nie ma indeksu klastrowego, jej wiersze danych są przechowywane w nieuporządkowanej strukturze zwanej stertą.
Nonclustered
Indeksy niezakłócone mają strukturę oddzieloną od wierszy danych. Indeks niezakłócony zawiera niezakłócone wartości klucza indeksu, a każdy wpis wartości klucza zawiera wskaźnik do wiersza danych, który zawiera wartość klucza. Wskaźnik od wiersza indeksu w indeksie niezakłóconym do wiersza danych nazywa się lokalizatorem wierszy. Struktura rzędu lokalizator zależy od tego, czy strony z danymi są przechowywane w stercie czy w tabeli klastrowej. W przypadku sterty lokalizator wierszy jest wskaźnikiem do wiersza. W przypadku klastrowej tabeli lokalizator wierszy jest klastrowym kluczem indeksu.
Możesz dodać kolumny niekey do poziomu liścia indeksu niezakłóconego, aby ominąć istniejące limity klucza indeksu i wykonać w pełni pokryte, zindeksowane, zapytania. Aby uzyskać więcej informacji, zobacz Tworzenie indeksów z dołączonymi kolumnami. Szczegółowe informacje na temat limitów klucza indeksu znajdują się w sekcji Maksymalna pojemność Specyfikacje dla SQL Server.
Odniesienie: https://docs.microsoft.com/en-us/sql/relational-databases/indexes/clustered-and-nonclustered-indexes-described{[18]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-08-28 00:10:59
Jeśli plik zawierający rekordy jest uporządkowany sekwencyjnie, indeks klastrowania jest indeksem, którego klucz wyszukiwania określa również kolejność sekwencyjną pliku. Indeksy grupowania są również nazywane indeksami pierwotnymi; termin indeks pierwotny może wydawać się oznaczający indeks na kluczu podstawowym, ale takie indeksy mogą być w rzeczywistości zbudowane na dowolnym kluczu wyszukiwania. Klucz wyszukiwania indeksu grupowania jest często kluczem podstawowym, choć niekoniecznie tak jest. Indeksy, których klucz wyszukiwania określa kolejność od kolejności sekwencyjnej pliku nazywane są indeksami nieklustrującymi lub indeksami wtórnymi. Terminy "clustered" i "nonclustered" są często używane zamiast " clustering " i " noncluster}."
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-07-12 16:24:38