Czym jest strona kodująca/kodująca cmd.exe za pomocą?
Kiedy otwieram cmd.exe w Windows, jakiego kodowania używa?
Jak mogę sprawdzić, którego kodowania aktualnie używa? Czy zależy to od mojego ustawienia regionalnego, czy są jakieś zmienne środowiskowe do sprawdzenia?
Co się dzieje, gdy wpiszesz Plik z określonym kodowaniem? Czasami dostaję zniekształcone znaki (używane niepoprawne kodowanie), A czasami działa. Ale nie ufam nikomu, dopóki nie wiem, co się dzieje. Czy ktoś może to wyjaśnić?
5 answers
Tak, to frustrujące-czasami type i inne programy
Drukuj bełkot, a czasami nie.
Po pierwsze, znaki Unicode będą wyświetlane tylko , jeśli bieżąca czcionka konsoli zawiera znaki . Więc użyj czcionka TrueType, taka jak Lucida Console, zamiast domyślnej czcionki rastrowej.
Ale jeśli czcionka konsoli nie zawiera znaku, który próbujesz wyświetlić, zobaczysz znaki zapytania zamiast bełkotu. Kiedy masz bełkot, jest więcej dalej niż tylko ustawienia czcionek.
Gdy programy używają standardowych funkcji We/Wy biblioteki C, takich jak printf, na
kodowanie wyjściowe programu musi odpowiadać kodowaniu wyjściowemu konsoli , lub
dostaniesz bełkotu. chcp pokazuje i ustawia bieżącą stronę kodową. Wszystkie
wyjście przy użyciu standardowych funkcji We/Wy biblioteki C jest traktowane tak, jakby było w
strona kodowa wyświetlana przez chcp.
Dopasowanie kodowania wyjściowego programu do kodowania wyjściowego konsoli można osiągnąć w dwóch różne sposoby:
-
Program może pobrać bieżącą stronę kodową konsoli za pomocą
chcplubGetConsoleOutputCP, i skonfigurować się do wyjścia w tym kodowaniu, lub Ty lub program możesz ustawić bieżącą stronę kodową konsoli za pomocą
chcplubSetConsoleOutputCPaby dopasować domyślne kodowanie wyjściowe programu.
Jednak programy korzystające z API Win32 mogą pisać bezpośrednio ciągi UTF-16LE
do konsoli z
WriteConsoleW.
To jest jedyny sposób, aby uzyskać poprawne wyjście bez ustawiania stron kodowych. Oraz
nawet przy użyciu tej funkcji, jeśli ciąg znaków nie jest w kodowaniu UTF-16LE
na początek Program Win32 musi przekazać poprawną stronę kodową do
MultiByteToWideChar.
Ponadto WriteConsoleW nie będzie działać, jeśli wynik programu zostanie przekierowany;
w takim przypadku potrzeba więcej bałaganu.
type działa przez pewien czas, ponieważ sprawdza początek każdego pliku pod kątem
UTF-16LE znak kolejności bajtów
(BOM) , czyli bajty 0xFF 0xFE.
Jeśli znajdzie taki
znak, wyświetla znaki Unicode w pliku za pomocą WriteConsoleW
niezależnie od aktualnej strony kodowej. Ale kiedy typeing dowolny plik bez
UTF-16LE BOM, lub do używania znaków innych niż ASCII z dowolnym poleceniem
to nie wywołuje WriteConsoleW - trzeba będzie ustawić
kodowanie konsoli i kodowanie wyjścia programu, aby pasowały do siebie.
Jak możemy się tego dowiedzieć?
Oto testowy plik zawierający znaki Unicode:
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
Oto program Java do wydruku plik testowy w kilku różnych
Kodowanie Unicode. Może być w dowolnym języku programowania; drukuje tylko
Znaki ASCII lub zakodowane bajty do stdout.
import java.io.*;
public class Foo {
private static final String BOM = "\ufeff";
private static final String TEST_STRING
= "ASCII abcde xyz\n"
+ "German äöü ÄÖÜ ß\n"
+ "Polish ąęźżńł\n"
+ "Russian абвгдеж эюя\n"
+ "CJK 你好\n";
public static void main(String[] args)
throws Exception
{
String[] encodings = new String[] {
"UTF-8", "UTF-16LE", "UTF-16BE", "UTF-32LE", "UTF-32BE" };
for (String encoding: encodings) {
System.out.println("== " + encoding);
for (boolean writeBom: new Boolean[] {false, true}) {
System.out.println(writeBom ? "= bom" : "= no bom");
String output = (writeBom ? BOM : "") + TEST_STRING;
byte[] bytes = output.getBytes(encoding);
System.out.write(bytes);
FileOutputStream out = new FileOutputStream("uc-test-"
+ encoding + (writeBom ? "-bom.txt" : "-nobom.txt"));
out.write(bytes);
out.close();
}
}
}
}
Wyjście w domyślnej stronie kodowej? Totalna bzdura!
Z:\andrew\projects\sx\1259084>chcp
Active code page: 850
Z:\andrew\projects\sx\1259084>java Foo
== UTF-8
= no bom
ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
= bom
´╗┐ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
== UTF-16LE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
= bom
■A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
== UTF-16BE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
= bom
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
== UTF-32LE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺
R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦
C J K `O }Y
= bom
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺
R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦
C J K `O }Y
== UTF-32BE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
= bom
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
Jednak, co jeśli type pliki, które zostały zapisane? Zawierają dokładnie
te same bajty, które zostały wydrukowane na konsoli.
Z:\andrew\projects\sx\1259084>type *.txt
uc-test-UTF-16BE-bom.txt
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
uc-test-UTF-16BE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
uc-test-UTF-16LE-bom.txt
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
uc-test-UTF-16LE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
uc-test-UTF-32BE-bom.txt
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
uc-test-UTF-32BE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
uc-test-UTF-32LE-bom.txt
A S C I I a b c d e x y z
G e r m a n ä ö ü Ä Ö Ü ß
P o l i s h ą ę ź ż ń ł
R u s s i a n а б в г д е ж э ю я
C J K 你 好
uc-test-UTF-32LE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺
R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦
C J K `O }Y
uc-test-UTF-8-bom.txt
´╗┐ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
uc-test-UTF-8-nobom.txt
ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
tylko to co dziala to plik UTF-16LE, z BOM, wydrukowany na
konsola via type.
Jeśli użyjemy czegoś innego niż type do wydrukowania pliku, otrzymamy śmieci:
Z:\andrew\projects\sx\1259084>copy uc-test-UTF-16LE-bom.txt CON
■A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
1 file(s) copied.
Z faktu, że copy CON nie wyświetla poprawnie Unicode, możemy
wnioskować, że polecenie type ma logikę wykrywania BOM UTF-16LE w
uruchom plik i użyj specjalnych interfejsów API systemu Windows, aby go wydrukować.
Możemy to zobaczyć otwierając cmd.exe w debuggerze, gdy przejdzie do type
out a file:
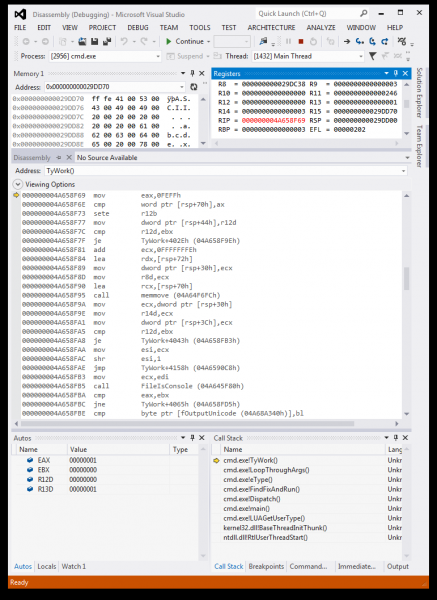
Po otwarciu type plik sprawdza, czy BOM 0xFEFF - czyli bajty
0xFF 0xFE in little-endian-and if there is such a BOM, type sets an
wewnętrzna fOutputUnicode flaga. Ta flaga jest sprawdzana później, aby zdecydować
czy zadzwonić WriteConsoleW.
Ale to jedyny sposób, aby uzyskać type wyjście Unicode, i tylko dla plików
które mają Bom i są w UTF-16LE. Dla wszystkich innych plików oraz dla programów
które nie mają specjalnego kodu do obsługi wyjścia konsoli, Twoje pliki będą
interpretowane zgodnie z aktualną stroną kodową i prawdopodobnie pojawi się jako
bełkot.
Możesz emulować jak type wyprowadza Unicode do konsoli w swoich własnych programach jak tak:
#include <stdio.h>
#define UNICODE
#include <windows.h>
static LPCSTR lpcsTest =
"ASCII abcde xyz\n"
"German äöü ÄÖÜ ß\n"
"Polish ąęźżńł\n"
"Russian абвгдеж эюя\n"
"CJK 你好\n";
int main() {
int n;
wchar_t buf[1024];
HANDLE hConsole = GetStdHandle(STD_OUTPUT_HANDLE);
n = MultiByteToWideChar(CP_UTF8, 0,
lpcsTest, strlen(lpcsTest),
buf, sizeof(buf));
WriteConsole(hConsole, buf, n, &n, NULL);
return 0;
}
Ten program działa do drukowania Unicode na konsoli Windows przy użyciu Domyślna strona kodowa.
Dla przykładowego programu Java, możemy uzyskać trochę poprawnego wyjścia przez w przeciwieństwie do poprzednich wersji, nie jest to możliwe.]}
Z:\andrew\projects\sx\1259084>chcp 65001
Active code page: 65001
Z:\andrew\projects\sx\1259084>java Foo
== UTF-8
= no bom
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
ж эюя
CJK 你好
你好
好
�
= bom
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
еж эюя
CJK 你好
你好
好
�
== UTF-16LE
= no bom
A S C I I a b c d e x y z
…
Jednak program w C, który ustawia Unicode UTF-8 codepage:
#include <stdio.h>
#include <windows.h>
int main() {
int c, n;
UINT oldCodePage;
char buf[1024];
oldCodePage = GetConsoleOutputCP();
if (!SetConsoleOutputCP(65001)) {
printf("error\n");
}
freopen("uc-test-UTF-8-nobom.txt", "rb", stdin);
n = fread(buf, sizeof(buf[0]), sizeof(buf), stdin);
fwrite(buf, sizeof(buf[0]), n, stdout);
SetConsoleOutputCP(oldCodePage);
return 0;
}
Ma poprawne wyjście:
Z:\andrew\projects\sx\1259084>.\test
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
Morał tej historii?
- Można drukować pliki UTF-16LE z BOM niezależnie od bieżącej strony kodowej]}
- programy Win32 można zaprogramować tak, aby wyjście Unicode do konsoli, za pomocą
WriteConsoleW. - inne programy, które ustawiają stronę kodową i odpowiednio dostosowują kodowanie wyjściowe, mogą drukować Unicode na konsoli, niezależnie od tego, jaka była strona kodowa, gdy program rozpoczęte
- za wszystko inne będziesz musiał zadzierać
chcp, i prawdopodobnie nadal będzie dziwnie wyjście.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-06-12 05:34:15
Typ
chcp
Aby zobaczyć aktualną stronę kodu(jak już powiedział Dewfy).
Użyj
nlsinfo
Aby zobaczyć wszystkie zainstalowane strony kodowe i dowiedzieć się, co oznacza Twój numer strony kodowej.
Aby używać nlsinfo, musisz mieć zainstalowany System Windows Server 2003 Resource kit (działa na Windows XP).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-08-12 09:36:26
Aby odpowiedzieć na drugie zapytanie re. jak działa kodowanie, Joel Spolsky napisał świetny artykuł wprowadzający na ten temat . Zdecydowanie zalecane.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-08-11 08:39:47
Polecenie CHCP pokazuje bieżącą stronę kodową. Ma trzy cyfry: 8xx i różni się od Windows 12xx. więc wpisując tekst tylko w języku angielskim nie zauważysz żadnej różnicy, ale Rozszerzona strona kodowa (jak Cyrylica) zostanie wydrukowana nieprawidłowo.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-08-12 08:35:58
Byłem sfrustrowany przez problemy ze stroną kodową systemu Windows oraz problemy z przenośnością i lokalizacją programów C, które powodują. Poprzednie posty szczegółowo opisywały kwestie, więc nie będę nic dodawać w tym zakresie.
Krótko mówiąc, w końcu napisałem własną warstwę biblioteki kompatybilności UTF-8 nad standardową biblioteką Visual C++. Zasadniczo ta Biblioteka zapewnia, że standardowy program C działa poprawnie, na dowolnej stronie kodowej, przy użyciu UTF-8 wewnętrznie.
Ta biblioteka, o nazwie MsvcLibX, jest dostępna jako open source pod adresem https://github.com/JFLarvoire/SysToolsLib . Główne cechy:
- źródła C zakodowane w UTF-8, używając zwykłych łańcuchów znaków [] C i standardowych interfejsów API biblioteki C.
- na dowolnej stronie kodowej wszystko jest przetwarzane wewnętrznie jako UTF-8 w kodzie, włączając w to funkcję main() argv [], ze standardowym wejściem i wyjściem automatycznie konwertowanym na właściwą stronę kodową.
- Wszystkie stdio.plik h funkcje obsługują ścieżki UTF-8 > 260 znaków, w rzeczywistości do 64 Kb.
- te same źródła mogą kompilować i łączyć się z powodzeniem w Windows przy użyciu Visual C++ i MsvcLibX i biblioteki Visual C++ C, a w Linuksie przy użyciu GCC i standardowej biblioteki C Linuksa, bez potrzeby stosowania # ifdef ... # endif blocks.
- dodaje pliki nagłówkowe powszechne w Linuksie, ale brakujące w Visual C++. Ex: unistd.h
- dodaje brakujące funkcje, takie jak te dla We/Wy katalogu, zarządzanie dowiązaniami symbolicznymi itp. Obsługa UTF-8 oczywiście: -).
Więcej szczegółów w MSVCLIBX README na GitHub , w tym jak zbudować bibliotekę i używać jej we własnych programach.
Sekcja release w powyższym repozytorium GitHub zawiera kilka programów korzystających z tej biblioteki MsvcLibX, które pokażą jej możliwości. Ex: spróbuj mojego, który.narzędzie exe z katalogami o nazwach innych niż ASCII w ścieżce, wyszukiwanie programów o nazwach innych niż ASCII i zmiana kodu stron.
Innym użytecznym narzędziem jest conv.program exe. Ten program może łatwo przekonwertować strumień danych z dowolnej strony kodowej na dowolną inną. Domyślnie jest to wejście na stronie kodowej systemu Windows, a wyjście na bieżącej stronie kodowej konsoli. Pozwala to na poprawne wyświetlanie danych generowanych przez aplikacje GUI systemu Windows (np. Notatnik) w konsoli poleceń, za pomocą prostego polecenia: type WINFILE.txt | conv
Ta biblioteka MsvcLibX w żadnym wypadku nie jest kompletna, a wkład w jej Ulepszanie jest mile widziany!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-10-20 17:06:59