Sortowanie 1 miliona 8-cyfrowych liczb w 1 MB PAMIĘCI RAM
Mam komputer z 1 MB RAM i nie ma innej pamięci lokalnej. Muszę go użyć, aby zaakceptować 1 milion 8-cyfrowych liczb dziesiętnych przez połączenie TCP, posortować je, a następnie wysłać posortowaną listę przez inne połączenie TCP.
Lista liczb może zawierać duplikaty, których nie mogę odrzucić. Kod zostanie umieszczony w ROM, więc nie muszę odejmować rozmiaru mojego kodu od 1 MB. Mam już kod do napędu portu Ethernet i obsługi połączeń TCP / IP i wymaga 2 KB dla danych stanu, w tym 1 KB bufora, za pomocą którego kod będzie odczytywał i zapisywał dane. Czy istnieje rozwiązanie tego problemu?
Źródła pytań i Odpowiedzi:
slashdot.org
30 answers
Jest jedna dość podstępna sztuczka, o której tu dotąd nie wspomniano. Zakładamy, że nie masz dodatkowego sposobu przechowywania danych, ale nie jest to do końca prawda.
Jednym ze sposobów obejścia Twojego problemu jest zrobienie następującej strasznej rzeczy, której nikt nie powinien próbować w żadnych okolicznościach: użyj ruchu sieciowego do przechowywania danych. I nie, nie mam na myśli NAS.
Możesz sortować liczby za pomocą tylko kilku bajtów pamięci RAM w następujący sposób:
- najpierw weź 2 zmienne:
COUNTERiVALUE. - najpierw ustaw wszystkie rejestry na
0; - za każdym razem, gdy otrzymujesz liczbę całkowitą
I, inkrementujCOUNTERi ustawVALUEnamax(VALUE, I); - następnie wyślij pakiet ICMP echo request z zestawem danych do I do routera. Wymaż I i powtórz.
- za każdym razem, gdy otrzymujesz zwrócony pakiet ICMP, po prostu wyodrębniasz liczbę całkowitą i wysyłasz ją ponownie w innym żądaniu echo. Powoduje to powstanie ogromnej liczby żądań ICMP scutting backward and forward zawierających liczby całkowite.
Gdy COUNTER osiągnie 1000000, masz wszystkie wartości zapisane w ciągłym strumieniu żądań ICMP, a VALUE zawiera teraz maksymalną liczbę całkowitą. Wybierz jakieś threshold T >> 1000000. Ustaw COUNTER Na zero. Za każdym razem, gdy otrzymujesz pakiet ICMP, inkrementuj COUNTER i wysyłaj zawartą liczbę całkowitą i wycofuj się w innym żądaniu echo, chyba że I=VALUE, w którym to przypadku przesyłaj ją do miejsca docelowego dla posortowanych liczb całkowitych. Raz COUNTER=T, zmniejsz VALUE przez 1, zresetuj COUNTER do zera i powtórz. Raz VALUE osiągnie zero powinieneś przesłać wszystkie liczby całkowite w kolejności od największej do najmniejszej do miejsca docelowego i użyć tylko około 47 bitów pamięci RAM dla dwóch stałych zmiennych (i każdej małej ilości potrzebnej do wartości tymczasowych).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-08-24 13:13:55
Oto działający kod C++ , który rozwiązuje problem.
dowód, że ograniczenia pamięci są spełnione:
redaktor: nie ma dowodu na maksymalne wymagania pamięci oferowane przez autora w tym poście lub na jego blogach. Ponieważ liczba bitów potrzebnych do zakodowania wartości zależy od wcześniej zakodowanych wartości, taki dowód jest prawdopodobnie nietrywialny. Autor zauważa, że największy zakodowany rozmiar mógł natknąć się empirycznie był 1011732 i dowolnie wybierał rozmiar bufora 1013000.
typedef unsigned int u32;
namespace WorkArea
{
static const u32 circularSize = 253250;
u32 circular[circularSize] = { 0 }; // consumes 1013000 bytes
static const u32 stageSize = 8000;
u32 stage[stageSize]; // consumes 32000 bytes
...
Razem te dwie tablice zajmują 1045000 bajtów pamięci. To pozostawia 1048576 - 1045000 - 2×1024 = 1528 bajtów dla pozostałych zmiennych i przestrzeni stosu.
Działa w około 23 sekundy na moim Xeon W3520. Możesz sprawdzić, czy program działa używając następującego skryptu Pythona, przyjmując nazwę programusort1mb.exe.
from subprocess import *
import random
sequence = [random.randint(0, 99999999) for i in xrange(1000000)]
sorter = Popen('sort1mb.exe', stdin=PIPE, stdout=PIPE)
for value in sequence:
sorter.stdin.write('%08d\n' % value)
sorter.stdin.close()
result = [int(line) for line in sorter.stdout]
print('OK!' if result == sorted(sequence) else 'Error!')
Szczegółowe wyjaśnienie algorytmu można znaleźć w następujących seriach posty:
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-02-25 09:24:39
Proszę zobaczyć pierwszą poprawną odpowiedź lub późniejszą odpowiedź z kodowaniem arytmetycznym . poniżej możesz znaleźć zabawne, ale nie w 100% kuloodporne rozwiązanie.
Jest to dość interesujące zadanie, a tutaj jest inne rozwiązanie. Mam nadzieję, że ktoś uzna wynik za przydatny (a przynajmniej interesujący).
Etap 1: wstępna struktura danych, przybliżone podejście do kompresji, podstawowe wyniki
Zróbmy prostą matematykę: mamy 1M (1048576 bajtów) pamięci RAM początkowo dostępnej do przechowywania 10^6 8 cyfr dziesiętnych. [0;99999999]. Tak więc do zapisania jednej liczby potrzebne jest 27 bitów (przy założeniu, że będą używane liczby niepodpisane). Tak więc do przechowywania surowego strumienia potrzebne będzie ~3,5 M pamięci RAM. Ktoś już powiedział, że to nie wydaje się być wykonalne, ale powiedziałbym, że zadanie można rozwiązać, jeśli wejście jest "wystarczająco dobre". Zasadniczo chodzi o to, aby skompresować dane wejściowe o współczynniku kompresji 0.29 lub wyższym i dokonać sortowania w odpowiednim sposób.
Rozwiążmy najpierw problem z kompresją. Dostępne są już odpowiednie testy:
Http://www.theeggeadventure.com/wikimedia/index.php/Java_Data_Compression
"przeprowadziłem test, aby skompresować milion kolejnych liczb całkowitych za pomocą różne formy kompresji. Wyniki są następujące: "
None 4000027
Deflate 2006803
Filtered 1391833
BZip2 427067
Lzma 255040
Wygląda na to, że LZMA (Lempel–Ziv–Markov algorytm łańcucha ) jest dobrym wyborem do kontynuowania. Przygotowałem proste PoC, ale są jeszcze pewne szczegóły do podkreślenia:
- pamięć jest ograniczona, więc chodzi o to, aby presortować Liczby i używać skompresowane wiadra (rozmiar dynamiczny) jako tymczasowe przechowywanie
- łatwiej jest osiągnąć lepszy współczynnik kompresji dzięki wstępnie posortowanemu dane, więc dla każdego zasobnika istnieje statyczny bufor (liczby z bufora mają być sortowane przed LZMA)
- każdy kubeł posiada określony zakres, więc ostateczny sortowanie może być wykonane dla każde wiadro osobno
- Rozmiar wiadra może być odpowiednio ustawiony, więc będzie wystarczająco dużo pamięci, aby dekompresuj zapisane dane i wykonaj ostateczne sortowanie dla każdego zasobnika oddzielnie
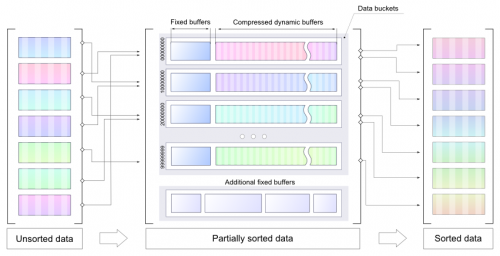
Należy pamiętać, że dołączony kod to POC , nie może być użyty jako ostateczne rozwiązanie, po prostu demonstruje pomysł użycia kilku mniejszych buforów do przechowywania presortowanych liczb w jakiś optymalny sposób (ewentualnie skompresowany). LZMA nie jest proponowana jako ostateczne rozwiązanie. Jest używany jako najszybszy możliwy sposób na wprowadź kompresję do tego PoC.
Zobacz kod PoC poniżej (zwróć uwagę na to tylko demo, aby go skompilować LZMA-Java będzie potrzebne):
public class MemorySortDemo {
static final int NUM_COUNT = 1000000;
static final int NUM_MAX = 100000000;
static final int BUCKETS = 5;
static final int DICT_SIZE = 16 * 1024; // LZMA dictionary size
static final int BUCKET_SIZE = 1024;
static final int BUFFER_SIZE = 10 * 1024;
static final int BUCKET_RANGE = NUM_MAX / BUCKETS;
static class Producer {
private Random random = new Random();
public int produce() { return random.nextInt(NUM_MAX); }
}
static class Bucket {
public int size, pointer;
public int[] buffer = new int[BUFFER_SIZE];
public ByteArrayOutputStream tempOut = new ByteArrayOutputStream();
public DataOutputStream tempDataOut = new DataOutputStream(tempOut);
public ByteArrayOutputStream compressedOut = new ByteArrayOutputStream();
public void submitBuffer() throws IOException {
Arrays.sort(buffer, 0, pointer);
for (int j = 0; j < pointer; j++) {
tempDataOut.writeInt(buffer[j]);
size++;
}
pointer = 0;
}
public void write(int value) throws IOException {
if (isBufferFull()) {
submitBuffer();
}
buffer[pointer++] = value;
}
public boolean isBufferFull() {
return pointer == BUFFER_SIZE;
}
public byte[] compressData() throws IOException {
tempDataOut.close();
return compress(tempOut.toByteArray());
}
private byte[] compress(byte[] input) throws IOException {
final BufferedInputStream in = new BufferedInputStream(new ByteArrayInputStream(input));
final DataOutputStream out = new DataOutputStream(new BufferedOutputStream(compressedOut));
final Encoder encoder = new Encoder();
encoder.setEndMarkerMode(true);
encoder.setNumFastBytes(0x20);
encoder.setDictionarySize(DICT_SIZE);
encoder.setMatchFinder(Encoder.EMatchFinderTypeBT4);
ByteArrayOutputStream encoderPrperties = new ByteArrayOutputStream();
encoder.writeCoderProperties(encoderPrperties);
encoderPrperties.flush();
encoderPrperties.close();
encoder.code(in, out, -1, -1, null);
out.flush();
out.close();
in.close();
return encoderPrperties.toByteArray();
}
public int[] decompress(byte[] properties) throws IOException {
InputStream in = new ByteArrayInputStream(compressedOut.toByteArray());
ByteArrayOutputStream data = new ByteArrayOutputStream(10 * 1024);
BufferedOutputStream out = new BufferedOutputStream(data);
Decoder decoder = new Decoder();
decoder.setDecoderProperties(properties);
decoder.code(in, out, 4 * size);
out.flush();
out.close();
in.close();
DataInputStream input = new DataInputStream(new ByteArrayInputStream(data.toByteArray()));
int[] array = new int[size];
for (int k = 0; k < size; k++) {
array[k] = input.readInt();
}
return array;
}
}
static class Sorter {
private Bucket[] bucket = new Bucket[BUCKETS];
public void doSort(Producer p, Consumer c) throws IOException {
for (int i = 0; i < bucket.length; i++) { // allocate buckets
bucket[i] = new Bucket();
}
for(int i=0; i< NUM_COUNT; i++) { // produce some data
int value = p.produce();
int bucketId = value/BUCKET_RANGE;
bucket[bucketId].write(value);
c.register(value);
}
for (int i = 0; i < bucket.length; i++) { // submit non-empty buffers
bucket[i].submitBuffer();
}
byte[] compressProperties = null;
for (int i = 0; i < bucket.length; i++) { // compress the data
compressProperties = bucket[i].compressData();
}
printStatistics();
for (int i = 0; i < bucket.length; i++) { // decode & sort buckets one by one
int[] array = bucket[i].decompress(compressProperties);
Arrays.sort(array);
for(int v : array) {
c.consume(v);
}
}
c.finalCheck();
}
public void printStatistics() {
int size = 0;
int sizeCompressed = 0;
for (int i = 0; i < BUCKETS; i++) {
int bucketSize = 4*bucket[i].size;
size += bucketSize;
sizeCompressed += bucket[i].compressedOut.size();
System.out.println(" bucket[" + i
+ "] contains: " + bucket[i].size
+ " numbers, compressed size: " + bucket[i].compressedOut.size()
+ String.format(" compression factor: %.2f", ((double)bucket[i].compressedOut.size())/bucketSize));
}
System.out.println(String.format("Data size: %.2fM",(double)size/(1014*1024))
+ String.format(" compressed %.2fM",(double)sizeCompressed/(1014*1024))
+ String.format(" compression factor %.2f",(double)sizeCompressed/size));
}
}
static class Consumer {
private Set<Integer> values = new HashSet<>();
int v = -1;
public void consume(int value) {
if(v < 0) v = value;
if(v > value) {
throw new IllegalArgumentException("Current value is greater than previous: " + v + " > " + value);
}else{
v = value;
values.remove(value);
}
}
public void register(int value) {
values.add(value);
}
public void finalCheck() {
System.out.println(values.size() > 0 ? "NOT OK: " + values.size() : "OK!");
}
}
public static void main(String[] args) throws IOException {
Producer p = new Producer();
Consumer c = new Consumer();
Sorter sorter = new Sorter();
sorter.doSort(p, c);
}
}
Z liczb losowych daje następujące:
bucket[0] contains: 200357 numbers, compressed size: 353679 compression factor: 0.44
bucket[1] contains: 199465 numbers, compressed size: 352127 compression factor: 0.44
bucket[2] contains: 199682 numbers, compressed size: 352464 compression factor: 0.44
bucket[3] contains: 199949 numbers, compressed size: 352947 compression factor: 0.44
bucket[4] contains: 200547 numbers, compressed size: 353914 compression factor: 0.44
Data size: 3.85M compressed 1.70M compression factor 0.44
Dla prostej sekwencji rosnącej (używa się jednego wiadra) tworzy ona:
bucket[0] contains: 1000000 numbers, compressed size: 256700 compression factor: 0.06
Data size: 3.85M compressed 0.25M compression factor 0.06
EDIT
Wniosek:
- Nie próbuj oszukać Natury
- używaj prostszej kompresji z mniejszą pamięcią footprint
- niektóre dodatkowe wskazówki są naprawdę potrzebne. Powszechne rozwiązanie kuloodporne nie wydaje się być wykonalne.
Etap 2: zwiększona kompresja, zakończenie
Jak już wspomniano w poprzedniej sekcji, można zastosować dowolną odpowiednią technikę kompresji. Więc pozbądźmy się LZMA na rzecz prostszego i lepszego (jeśli to możliwe) podejścia. Istnieje wiele dobrych rozwiązań, w tym kodowanie arytmetyczne, drzewo Radix itd.
W każdym razie prosty, ale użyteczny schemat kodowania będzie bardziej ilustracyjny niż kolejna zewnętrzna biblioteka, dostarczająca sprytnego algorytmu. Rzeczywiste rozwiązanie jest dość proste: ponieważ istnieją wiadra z częściowo posortowanymi danymi, można używać delt zamiast liczb.
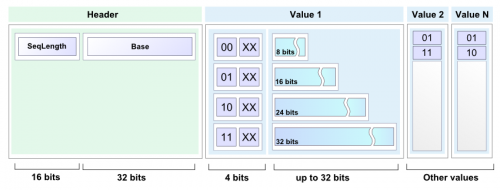
Random input test pokazuje nieco lepsze wyniki:
bucket[0] contains: 10103 numbers, compressed size: 13683 compression factor: 0.34
bucket[1] contains: 9885 numbers, compressed size: 13479 compression factor: 0.34
...
bucket[98] contains: 10026 numbers, compressed size: 13612 compression factor: 0.34
bucket[99] contains: 10058 numbers, compressed size: 13701 compression factor: 0.34
Data size: 3.85M compressed 1.31M compression factor 0.34
Przykładowy kod
public static void encode(int[] buffer, int length, BinaryOut output) {
short size = (short)(length & 0x7FFF);
output.write(size);
output.write(buffer[0]);
for(int i=1; i< size; i++) {
int next = buffer[i] - buffer[i-1];
int bits = getBinarySize(next);
int len = bits;
if(bits > 24) {
output.write(3, 2);
len = bits - 24;
}else if(bits > 16) {
output.write(2, 2);
len = bits-16;
}else if(bits > 8) {
output.write(1, 2);
len = bits - 8;
}else{
output.write(0, 2);
}
if (len > 0) {
if ((len % 2) > 0) {
len = len / 2;
output.write(len, 2);
output.write(false);
} else {
len = len / 2 - 1;
output.write(len, 2);
}
output.write(next, bits);
}
}
}
public static short decode(BinaryIn input, int[] buffer, int offset) {
short length = input.readShort();
int value = input.readInt();
buffer[offset] = value;
for (int i = 1; i < length; i++) {
int flag = input.readInt(2);
int bits;
int next = 0;
switch (flag) {
case 0:
bits = 2 * input.readInt(2) + 2;
next = input.readInt(bits);
break;
case 1:
bits = 8 + 2 * input.readInt(2) +2;
next = input.readInt(bits);
break;
case 2:
bits = 16 + 2 * input.readInt(2) +2;
next = input.readInt(bits);
break;
case 3:
bits = 24 + 2 * input.readInt(2) +2;
next = input.readInt(bits);
break;
}
buffer[offset + i] = buffer[offset + i - 1] + next;
}
return length;
}
Proszę zauważyć, że podejście to:
- nie zużywa dużo pamięć
- Działa ze strumieniami
- zapewnia nie takie złe wyniki
Pełny kod można znaleźć tutaj , implementacje BinaryInput i BinaryOutput można znaleźć tutaj
Zakończenie
Brak ostatecznego wniosku:) czasami naprawdę dobrze jest przenieść jeden poziom w górę i przejrzeć zadanie z punktu widzenia meta-poziomu .
Fajnie było spędzić trochę czasu z tym zadaniem. BTW, jest dużo ciekawe Odpowiedzi poniżej. Dziękuję za uwagę i szczęśliwe rozpieszczanie.Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:10:10
Rozwiązanie jest możliwe tylko ze względu na różnicę między 1 megabajtem a 1 milionem bajtów. Istnieje około 2 do mocy 8093729.5 różne sposoby wyboru 1 miliona 8-cyfrowych liczb z dozwolonymi duplikatami i kolejność nieistotna, więc maszyna z tylko 1 milionem bajtów pamięci RAM nie ma wystarczającej liczby stanów, aby reprezentować wszystkie możliwości. Ale 1M (mniej 2K dla TCP/IP) to 1022*1024*8 = 8372224 bitów, więc rozwiązanie jest możliwe.
Część 1, roztwór początkowy
To podejście wymaga trochę więcej niż 1M, poprawię go, aby zmieścił się w 1M później.
Będę przechowywać zwartą posortowaną listę liczb z zakresu od 0 do 99999999 jako sekwencję sublist liczb 7-bitowych. Pierwsza sublist posiada numery od 0 do 127, druga sublist posiada numery od 128 do 255 itd. 100000000/128 to dokładnie 781250, więc 781250 takie podlisty będą potrzebne.
Każda sublist składa się z 2-bitowego nagłówka sublist, po którym następuje ciało sublist. Ciało sublist zajmuje 7 bitów / align = "left" / Wszystkie sublisty są połączone ze sobą, a format umożliwia określenie, gdzie kończy się jedna sublista, a zaczyna Następna. Całkowita ilość miejsca wymagana do pełnego wypełnienia listy wynosi 2*781250 + 7*1000000 = 8562500 bitów, czyli około 1,021 M-bajtów.
4 Możliwe wartości nagłówka sublist to:
00 pusta sublist, nic nie następuje.
01 Singleton, w subliście jest tylko jeden wpis, a następne 7 bitów trzyma to.
10 sublist posiada co najmniej 2 odrębne numery. Wpisy są przechowywane w porządku nie malejącym, z tym że ostatni wpis jest mniejszy lub równy pierwszemu. Pozwala to na identyfikację końca sublisty. Na przykład liczby 2,4,6 będą zapisywane jako (4,6,2). Liczby 2,2,3,4,4 będą zapisywane jako (2,3,4,4,2).
11 sublist zawiera 2 lub więcej powtórzeń pojedynczej liczby. Kolejne 7 bitów daje liczbę. Potem zero lub więcej 7-bitowe wpisy z wartością 1, a następnie 7-bitowe wpisy z wartością 0. Długość ciała sublist dyktuje liczbę powtórzeń. Na przykład liczby 12,12 będą przechowywane jako (12,0), liczby 12,12,12 będą przechowywane jako (12,1,0), 12,12,12,12 będą (12,1,1,0) i tak dalej.
Zaczynam od pustej listy, odczytuję kilka liczb i przechowuję je jako 32-bitowe liczby całkowite, sortuję nowe liczby na miejscu (prawdopodobnie za pomocą heapsort), a następnie scalam je w Nowy kompakt posortowana lista. Powtarzaj, aż nie będzie więcej liczb do odczytania, a następnie przejdź po zwartej liście jeszcze raz, aby wygenerować wynik.
Poniższy wiersz przedstawia pamięć tuż przed rozpoczęciem operacji scalania listy. "O" S są regionem, który zawiera posortowane 32-bitowe liczby całkowite. "X" są regionem, który zawiera starą listę zwartą. Znaki " = "są pokojem rozszerzeń dla listy zwartej, 7 bitów dla każdej liczby całkowitej W"O" s. " Z " S są innymi przypadkowymi narzutami.
ZZZOOOOOOOOOOOOOOOOOOOOOOOOOO==========XXXXXXXXXXXXXXXXXXXXXXXXXX
The merge routine rozpoczyna odczyt na lewym "O" i na lewym "X", a zaczyna zapis na lewym"=". Wskaźnik zapisu nie łapie wskaźnika odczytu listy zwartej, dopóki wszystkie nowe liczby całkowite nie zostaną połączone, ponieważ oba wskaźniki zwiększają liczbę o 2 bity dla każdej sublisty i o 7 bitów dla każdego wpisu w starej liście zwartej, i jest wystarczająco dużo miejsca dla 7-bitowych wpisów dla nowych liczb.
Część 2. wciskanie na 1M
Aby przecisnąć powyższe rozwiązanie na 1M, potrzebuję aby uczynić kompaktowy format listy nieco bardziej kompaktowym. Pozbędę się jednego z typów sublist, tak, że będą tylko 3 różne możliwe wartości nagłówka sublist. Następnie mogę użyć "00", " 01 " i " 1 " jako wartości nagłówka sublist i zapisać kilka bitów. Typy sublist to:
Pusta sublista, nic nie następuje.
B Singleton, jest tylko jeden wpis w subliście i następne 7 bitów go trzyma.
C sublist posiada co najmniej 2 różne liczby. Wpisy są przechowywane w kolejność nie malejąca, z tym że ostatni wpis jest mniejszy lub równy pierwszemu. Pozwala to na identyfikację końca sublisty. Na przykład liczby 2,4,6 będą zapisywane jako (4,6,2). Liczby 2,2,3,4,4 będą zapisywane jako (2,3,4,4,2).
D sublist składa się z 2 lub więcej powtórzeń pojedynczej liczby.
Moje 3 wartości nagłówka sublist będą "A", "B" I "C", więc potrzebuję sposobu na reprezentowanie sublist typu D.
Załóżmy, że mam nagłówek sublist Typu C po którym następuje 3 wpisy, np. " C[17][101][58]". To nie może być częścią poprawnej sublisty Typu C, jak opisano powyżej, ponieważ Trzeci wpis jest mniejszy niż drugi, ale większy niż pierwszy. Mogę użyć tego typu konstrukcji, aby reprezentować sublist typu D. W sensie bitowym, gdziekolwiek mam " C{00?????}{1??????}{01?????} "jest niemożliwą sublistą typu C. Użyję tego do przedstawienia sublisty składającej się z 3 lub więcej powtórzeń pojedynczej liczby. Pierwsze dwa 7-bitowe słowa kodują liczbę (bity "N" poniżej), po których następuje zero lub więcej słów {0100001}, po których następuje słowo {0100000}.
For example, 3 repetitions: "C{00NNNNN}{1NN0000}{0100000}", 4 repetitions: "C{00NNNNN}{1NN0000}{0100001}{0100000}", and so on.
To pozostawia listy, które zawierają dokładnie 2 powtórzenia pojedynczej liczby. Przedstawię te z innym niemożliwym wzorem typu C: "C{0??????}{11?????}{10?????}". Jest dużo miejsca na 7 bitów liczby w pierwszych 2 słowach, ale ten wzór jest dłuższy niż sublista, którą reprezentuje, co sprawia, że sprawy są nieco bardziej złożone. Pięć znaków zapytania na końcu może być nie jest częścią wzoru, więc mam: "C{0NNNNNN} {11N????10" jako mój wzorzec, z liczbą do powtórzenia zapisaną w "N". to o 2 bity za długie.
Będę musiał pożyczyć 2 bity i spłacić je z 4 nieużywanych bitów w tym wzorze. Podczas odczytu, po napotkaniu "C{0NNNNNN}{11N00AB}10", wypisuje 2 instancje liczby W "N"s, nadpisuje "10" na końcu bitami a i B i przewija czytany wskaźnik o 2 bity. Destrukcyjne odczyty są ok dla tego algorytmu, ponieważ każda zwarta lista jest chodzona tylko raz.Pisząc sublist 2 powtórzeń pojedynczej liczby, napisz "C {0NNNNNN}11N00" i ustaw licznik zapożyczonych bitów na 2. Przy każdym zapisie, gdzie licznik zapożyczonych bitów jest niezerowy, jest on zmniejszany dla każdego zapisanego bitu, a "10" jest zapisywane, gdy licznik uderza w zero. Tak więc następne 2 zapisane bity trafią do szczelin A i B, a następnie "10" spadnie na koniec.
Z 3 wartościami nagłówka sublist reprezentowanymi przez "00", " 01 " i "1", mogę przypisać "1" do najpopularniejszego typu sublist. Będę potrzebował małej tabeli do mapowania wartości nagłówków sublist do typów sublist i będę potrzebował licznika zdarzeń dla każdego typu sublist, aby wiedzieć, jakie jest najlepsze mapowanie nagłówków sublist.
Najgorsza minimalna reprezentacja w pełni wypełnionej listy kompaktowej występuje, gdy wszystkie typy sublist są równie popularne. W takim przypadku zapisuję 1 bit na każde 3 nagłówki sublist, więc rozmiar listy jest 2*781250 + 7*1000000 - 781250/3 = 8302083.3 bity. Zaokrąglenie do 32-bitowej granicy słowa, To 8302112 bitów lub 1037764 bajtów.
1M minus 2K dla stanu TCP / IP i buforów to 1022*1024 = 1046528 bajtów, pozostawiając mi 8764 bajtów do zabawy.
Ale co z procesem zmiany mapowania nagłówka sublist ? Na poniższej mapie pamięci, "Z" jest losowym napowietrzaniem, " = "jest wolną przestrzenią," X " jest zwartą listą.
ZZZ=====XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Zacznij czytać od lewego " X "i zacznij pisać od lewego" = " i pracuj w prawo. Kiedy to się skończy lista zwarta będzie nieco krótsza i będzie na złym końcu pamięci:
ZZZXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX=======
Więc będę musiał przetrzeć go w prawo:
ZZZ=======XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
W procesie zmiany mapowania nagłówków, do 1/3 nagłówków sublist zmieni się z 1-bitowego na 2-bitowy. W najgorszym przypadku wszystkie będą na czele listy, więc będę potrzebował co najmniej 781250/3 bitów wolnego miejsca, zanim zacznę, co zabierze mnie z powrotem do wymagań pamięci poprzedniej wersji listy kompaktowej :(
Aby to obejść, podzielę 781250 sublist na 10 sublist grup po 78125 sublist każda. Każda grupa ma swoje własne niezależne mapowanie nagłówków sublist. Użycie liter od A do J dla grup:
ZZZ=====AAAAAABBCCCCDDDDDEEEFFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
Każda grupa sublist kurczy się lub pozostaje taka sama podczas zmiany mapowania nagłówka sublist:
ZZZ=====AAAAAABBCCCCDDDDDEEEFFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAA=====BBCCCCDDDDDEEEFFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABB=====CCCCDDDDDEEEFFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCC======DDDDDEEEFFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDD======EEEFFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDDEEE======FFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDDEEEFFF======GGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDDEEEFFFGGGGGGGGGG=======HHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDDEEEFFFGGGGGGGGGGHH=======IJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDDEEEFFFGGGGGGGGGGHHI=======JJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDDEEEFFFGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ=======
ZZZ=======AAAAAABBCCCDDDDDEEEFFFGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
Najgorszy przypadek czasowego rozszerzenia grupy sublist podczas zmiany mapowania to 78125/3 = 26042 bity, poniżej 4k. jeśli pozwolę 4k plus 1037764 bajtów na pełne wypełniona zwarta lista, która pozostawia mi 8764 - 4096 = 4668 bajtów dla "Z" s na mapie pamięci.
To powinno wystarczyć na 10 tabel mapowania nagłówków sublist, 30 liczeń wystąpień nagłówków sublist i kilka innych liczników, wskaźników i małych buforów, które będę potrzebował, i przestrzeni, której użyłem bez zauważenia, jak przestrzeń stosu dla adresów zwrotnych funkcji i zmiennych lokalnych.
Część 3, Jak długo potrwa bieganie?
Z pustą listą zwartą lista 1-bitowa nagłówek będzie używany do pustej sublisty, a początkowy rozmiar listy będzie wynosił 781250 bitów. W najgorszym przypadku lista rośnie 8 bitów dla każdej dodanej liczby, więc 32 + 8 = 40 bitów wolnego miejsca są potrzebne dla każdej z 32-bitowych liczb, które mają być umieszczone na górze bufora listy, a następnie posortowane I scalone. W najgorszym przypadku zmiana mapowania nagłówków sublist powoduje wykorzystanie przestrzeni 2*781250 + 7*wpisy - 781250/3 bitów.
Z Polityką zmiany mapowania nagłówka sublist po co piąte scalenie gdy na liście znajduje się co najmniej 800000 liczb, najgorszy przypadek obejmowałby łącznie około 30M czynności czytania i pisania listy zwartej.
Źródło:
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-10-11 15:05:03
Odpowiedź Gilmanova jest bardzo błędna w swoich założeniach. Zaczyna spekulować na podstawie miary miliona kolejnych liczb całkowitych. To oznacza brak luk. Te przypadkowe luki, jakkolwiek małe, naprawdę sprawiają, że jest to kiepski pomysł.
Spróbuj sam. Zdobądź milion losowych 27-bitowych liczb całkowitych, posortuj je, skompresuj 7-Zip , xz, cokolwiek chcesz. Wynik to ponad 1,5 MB. Założeniem na górze jest kompresja liczb sekwencyjnych. Even kodowanie delta z tego ponad 1,1 MB. I nieważne, że do kompresji używa się ponad 100 MB PAMIĘCI RAM. Więc nawet skompresowane liczby całkowite nie pasują do problemu i nie ma znaczenia czas pracy pamięci RAM . To smutne, jak ludzie po prostu upvote ładną grafikę i racjonalizacji.#include <stdint.h>
#include <stdlib.h>
#include <time.h>
int32_t ints[1000000]; // Random 27-bit integers
int cmpi32(const void *a, const void *b) {
return ( *(int32_t *)a - *(int32_t *)b );
}
int main() {
int32_t *pi = ints; // Pointer to input ints (REPLACE W/ read from net)
// Fill pseudo-random integers of 27 bits
srand(time(NULL));
for (int i = 0; i < 1000000; i++)
ints[i] = rand() & ((1<<27) - 1); // Random 32 bits masked to 27 bits
qsort(ints, 1000000, sizeof (ints[0]), cmpi32); // Sort 1000000 int32s
// Now delta encode, optional, store differences to previous int
for (int i = 1, prev = ints[0]; i < 1000000; i++) {
ints[i] -= prev;
prev += ints[i];
}
FILE *f = fopen("ints.bin", "w");
fwrite(ints, 4, 1000000, f);
fclose(f);
exit(0);
}
Teraz skompresuj ints.kosz z LZMA...
$ xz -f --keep ints.bin # 100 MB RAM
$ 7z a ints.bin.7z ints.bin # 130 MB RAM
$ ls -lh ints.bin*
3.8M ints.bin
1.1M ints.bin.7z
1.2M ints.bin.xz
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-10-11 15:12:58
Myślę, że jednym ze sposobów myślenia o tym jest z punktu widzenia kombinatoryki: ile jest możliwych kombinacji uporządkowanych liczb? Jeśli damy kombinację 0,0,0,...., 0 kod 0, i 0,0,0,..., 1 kod 1 i 99999999, 99999999, ... 99999999 kod N, co to jest N? Innymi słowy, jak duża jest przestrzeń wyniku?
Cóż, jednym ze sposobów myślenia o tym jest zauważenie, że jest to bijekcja problemu znalezienia liczby ścieżek monotonicznych w siatce N x M, gdzie N = 1 000 000 i M = 100 000 000. Innymi słowy, jeśli masz siatkę o szerokości 1 000 000 i wysokości 100 000 000, ile jest najkrótszych ścieżek od lewego dolnego rogu do prawego górnego rogu? Najkrótsze ścieżki oczywiście wymagają tylko poruszania się w prawo lub w górę (jeśli miałbyś poruszać się w dół lub w lewo, cofałbyś wcześniej osiągnięty postęp). Aby zobaczyć jak to jest bijekcja naszego problemu sortowania liczb, obserwuj co następuje:
Można sobie wyobrazić każdą poziomą nogę na naszej drodze jako numer w naszym zamówieniu, gdzie położenie y nogi reprezentuje wartość.
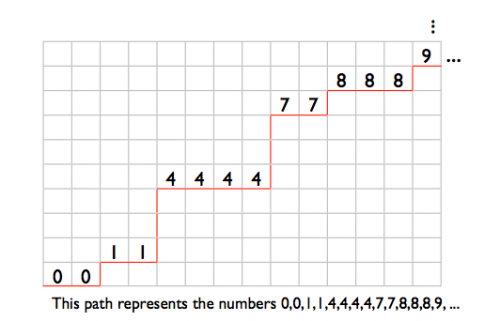
Więc jeśli ścieżka po prostu przesuwa się w prawo aż do końca, to przeskakuje całą drogę na górę, co jest równoważne 0,0,0,...,0. jeśli zamiast tego zaczyna się od przeskakiwania aż do góry, a następnie przesuwa się w prawo 1,000,000 razy, co jest równoważne 999999999999,..., 99999999. Ścieżką, gdzie porusza się raz w prawo, potem raz w górę, potem raz w prawo, potem raz w górę itd. do bardzo koniec (wtedy koniecznie przeskakuje całą drogę do góry), jest równoważne 0,1,2,3,...,999999.
Na szczęście dla nas ten problem został już rozwiązany, taka siatka ma (N + m) wybieramy (m) ścieżki:
(1,000,000 + 100,000,000) Wybierz (100,000,000) ~= 2.27 * 10^2436455
N zatem równa się 2.27 * 10^2436455, a więc kod 0 oznacza 0,0,0,..., 0 i Kod 2.27 * 10^2436455, a niektóre zmiany oznaczają 999999999,99999999,..., 99999999.
W celu przechowywania wszystkich numery od 0 do 2.27 * 10^2436455 potrzebujesz lg2 (2.27 * 10^2436455) = 8.0937 * 10^6 bity.
1 megabajt = 8388608 bitów > 8093700 bitów
Więc wygląda na to, że przynajmniej mamy wystarczająco dużo miejsca, aby zapisać wynik! Teraz oczywiście interesujący bit robi sortowanie jako strumień liczb. Nie jestem pewien, czy najlepsze podejście do tego jest podane, że pozostało nam 294908 bitów. Wyobrażam sobie, że ciekawą techniką byłoby założenie w każdym punkcie, że jest to całe uporządkowanie, znalezienie kodu do tego zamówienia, a następnie, gdy otrzymasz nowy numer wraca i aktualizuje poprzedni kod. Ręka wave ręka wave.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 23:06:42
Moje propozycje tutaj wiele zawdzięczają Dan ' s solution
Po pierwsze zakładam, że rozwiązanie musi obsługiwać Wszystkie możliwe listy wejściowe. Myślę, że popularne odpowiedzi nie stawiają tego założenia (co IMO jest ogromnym błędem).
Wiadomo, że żadna forma bezstratnej kompresji nie zmniejszy rozmiaru wszystkich wejść.
Wszystkie popularne odpowiedzi zakładają, że będą w stanie zastosować kompresję wystarczająco efektywną, aby zapewnić im dodatkową przestrzeń. W rzeczywistości, kawałek dodatkowej przestrzeni wystarczająco duże, aby pomieścić część ich częściowo wypełnionej listy w nieskompresowanej formie i umożliwić im wykonywanie operacji sortowania. To tylko złe założenie.
Dla takiego rozwiązania, każdy, kto zna sposób ich kompresji będzie w stanie zaprojektować pewne dane wejściowe, które nie kompresują się dobrze dla tego schematu, a "rozwiązanie" najprawdopodobniej pęknie z powodu braku miejsca.
Zamiast tego stosuję podejście matematyczne. Nasze możliwe wyjścia to wszystkie listy długości LEN składające się z elementów z zakresu 0..MAX. Tutaj len jest 1,000,000, a nasz MAX to 100,000,000.
Dla dowolnego LEN i MAX, ilość bitów potrzebnych do zakodowania tego stanu wynosi:
Log2 (MAX Multichoose LEN)
Więc dla naszych liczb, po zakończeniu otrzymywania i sortowania, będziemy potrzebować co najmniej Log2(100,000,000 MC 1,000,000) bitów do przechowywania naszego wyniku w sposób, który może jednoznacznie odróżnić wszystkie możliwe wyjścia.
To jest ~= 988kb . Więc mamy wystarczająco dużo miejsca, aby utrzymać nasz wynik. Z tego punktu widzenia jest to możliwe.
[usunięty]..]
Najlepsza odpowiedź jest tutaj .
Kolejna dobra odpowiedź jest tutaj i zasadniczo używa sortowania wstawiania jako funkcji rozszerzającej Listę o jeden element (buforuje kilka elementów i wstępnie sortuje, aby umożliwić wstawianie więcej niż jednego na raz, oszczędza trochę czasu). używa ładnego, kompaktowego stanu kodowanie też, 7 bitowych delt
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:10:10
Załóżmy, że to zadanie jest możliwe. Tuż przed wyjściem pojawi się w pamięci reprezentacja miliona posortowanych liczb. Ile jest takich reprezentacji? Ponieważ liczby mogą się powtarzać, nie możemy użyć nCr (choose), ale istnieje operacja o nazwie multichoose, która działa na multisetach.
- Istnieją 2. 2e2436455 sposoby wyboru miliona liczb z zakresu 0..99,999,999.
- to wymaga 8,093,730 bity do reprezentowania każda możliwa kombinacja, czyli 1 011 717 bajtów.
Więc teoretycznie może być to możliwe, jeśli uda się wymyślić rozsądną (wystarczającą) reprezentację posortowanej listy liczb. Na przykład, insane reprezentacja może wymagać 10MB tabeli wyszukiwania lub tysiące linii kodu.
Jeśli jednak "1M RAM" oznacza milion bajtów, to wyraźnie nie ma wystarczającej ilości miejsca. Fakt, że 5% więcej pamięci sprawia, że teoretycznie jest to możliwe, sugeruje mi, że reprezentacja będzie muszą być bardzo wydajne i prawdopodobnie nie przy zdrowych zmysłach.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-22 17:55:15
(moja oryginalna odpowiedź była błędna, przepraszam za złą matematykę, patrz poniżej przerwa.)
Co ty na to?Pierwsze 27 bitów przechowuje najniższą liczbę, jaką widziałeś, następnie różnicę do następnej widzianej liczby, zakodowaną w następujący sposób: 5 bitów do przechowywania liczby bitów używanych do przechowywania różnicy, następnie różnica. Użyj 00000, aby wskazać, że ponownie widziałeś ten numer.
To działa, ponieważ gdy więcej liczb jest wstawianych, średnia różnica między liczbami maleje, więc używasz mniej bitów do przechowywania różnicy, gdy dodajesz więcej liczb. Myślę, że to się nazywa lista delta.
Najgorszy przypadek, jaki przychodzi mi do głowy, to równomierne rozłożenie wszystkich liczb (przez 100), np. przy założeniu, że 0 jest liczbą pierwszą:
000000000000000000000000000 00111 1100100
^^^^^^^^^^^^^
a million times
27 + 1,000,000 * (5+7) bits = ~ 427k
Reddit na ratunek! Jeśli wszystko, co musisz zrobić, to je posortować, ten problem byłby łatwy. Zapis tych liczb zajmuje 122k (1 milion bitów) (0-ty bit w przypadku, gdy widziano 0, 2300-ty bit w przypadku, gdy widziano 2300, itd.
Czytasz liczby, przechowuj je w polu bit, a następnie przesuń bity, zachowując licznik.
Ale musisz pamiętać, ile widziałeś. Zainspirowała mnie powyższa odpowiedź sublist, aby wymyślić ten schemat:Zamiast używać jednego bitu, użyj 2 lub 27 bitów:
- 00 oznacza, że nie widziałeś numeru.
- 01 oznacza, że widziałeś to raz
- 1 oznacza, że to widziałeś, a następne 26 bitów to liczba ile razy.
Myślę, że to działa: jeśli nie ma duplikatów, masz listę 244k. W najgorszym przypadku widzisz każdą liczbę dwa razy (jeśli widzisz jedną liczbę trzy razy, skraca to resztę listy), co oznacza, że widziałeś 50 000 więcej niż raz, a widziałeś 950 000 pozycji 0 LUB 1 razy.
50,000 * 27 + 950,000 * 2 = 396.7 k.
Możesz wprowadzić dalsze ulepszenia, jeśli używasz następującego kodowania:
0 oznacza, że nie widziałeś liczby 10 oznacza, że widziałeś to raz 11 to jak się liczy
Co daje średnio 280,7 tys.EDIT: moja niedzielna matematyka była zła.
Najgorszym przypadkiem jest to, że widzimy 500 000 liczb dwa razy, więc matematyka staje się:
500,000 *27 + 500,000 *2 = 1.77 M
Alternatywne kodowanie skutkuje średnim zapisem
500,000 * 27 + 500,000 = 1.70 M
: (
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 19:25:25
Istnieje jedno rozwiązanie tego problemu na wszystkich możliwych wejściach. Oszust.
- odczyt wartości m przez TCP, gdzie m jest w pobliżu max, które można sortować w pamięci, może n / 4.
- posortuj 250 000 (lub więcej) liczb i wypuść je. Powtórz przez pozostałe 3 ćwiartki.
- niech odbiorca połączy 4 listy liczb, które otrzymał podczas ich przetwarzania. (Nie jest to dużo wolniejsze niż użycie pojedynczej listy.)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 19:39:01
Spróbowałbym drzewa Radix . Jeśli można przechowywać dane w drzewie, można następnie zrobić w kolejności Trawers, aby przesłać dane.
Nie jestem pewien, czy zmieścisz to do 1MB, ale myślę, że warto spróbować.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 16:33:47
Jakiego komputera używasz? Może nie ma innej" normalnej " pamięci lokalnej, ale czy ma na przykład pamięć RAM Wideo? 1 megapiksel x 32 bity na piksel (powiedzmy) jest bardzo zbliżony do wymaganego rozmiaru wejściowego danych.
(w dużej mierze pytam w pamięci starego Acorn RISC PC , który mógłby "pożyczyć" VRAM, aby rozszerzyć dostępną pamięć systemową, jeśli wybrałeś tryb ekranu o niskiej rozdzielczości lub niskiej głębi kolorów!). Było to raczej przydatne na komputerze z zaledwie kilkoma MB normalnej pamięci RAM.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 20:22:46
Reprezentacja drzewa radix zbliżyłaby się do rozwiązania tego problemu, ponieważ drzewo radix wykorzystuje "kompresję prefiksów". Ale trudno wyobrazić sobie reprezentację drzewa radix, która mogłaby reprezentować pojedynczy węzeł w jednym bajcie.
Ale, niezależnie od tego, jak dane są reprezentowane, po ich posortowaniu mogą być przechowywane w formie skompresowanej przedrostkiem, gdzie liczby 10, 11 i 12 byłyby reprezentowane przez, powiedzmy 001b, 001B, 001B, wskazując przyrost o 1 od poprzedniej liczby. Być może zatem 10101b oznaczałoby przyrost o 5, 1101001b przyrost o 9 itd.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 13:24:11
Jest 10^6 wartości w zakresie 10^8, więc jest jedna wartość na sto punktów kodu średnio. Zapisz odległość od N-tego punktu do (N+1) th. Zduplikowane wartości mają pomijanie 0. Oznacza to, że skip potrzebuje średnio prawie 7 bitów do przechowywania, więc milion z nich szczęśliwie zmieści się w naszych 8 milionach bitów pamięci.
Te przeskoki muszą być zakodowane w strumieniu bitowym, powiedzmy przez kodowanie Huffmana. Wstawianie polega na iteracji poprzez strumień bitów i przepisywaniu po nowa wartość. Wyjście poprzez iterację i zapisanie wartości domyślnych. Dla praktyczności, to prawdopodobnie chce być zrobione jako, powiedzmy, 10^4 listy obejmujące 10^4 punktów kodowych (i średnio 100 wartości) każdy.
Dobre drzewo Huffmana dla danych losowych można zbudować a priori zakładając rozkład Poissona (średnia = wariancja=100) na długości przeskoków, ale rzeczywiste statystyki mogą być przechowywane na wejściu i wykorzystywane do generowania optymalnego drzewa do radzenia sobie z patologicznymi przypadkami.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 20:54:45
Mam komputer z 1M RAM i nie ma innej lokalnej pamięci
Inny sposób na oszukiwanie: możesz zamiast tego użyć nielokalnej (sieciowej) pamięci masowej (twoje pytanie nie wyklucza tego) i zadzwonić do sieciowej usługi, która mogłaby używać prostego mergesort opartego na dysku (lub po prostu wystarczającej ilości pamięci RAM do sortowania w pamięci, ponieważ musisz zaakceptować tylko liczby 1M), bez potrzeby (co prawda niezwykle pomysłowych) rozwiązań już podanych.
To może być oszustwo, ale nie jest jasne, czy szukasz rozwiązania realnego problemu, czy zagadki, która zachęca do naginania zasad... jeśli to drugie, to prosty cheat może uzyskać lepsze wyniki niż złożone, ale "prawdziwe" rozwiązanie (które, jak zauważyli inni, może działać tylko dla skompresowalnych wejść).Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 20:10:55
Myślę, że rozwiązaniem jest połączenie technik kodowania wideo, a mianowicie dyskretnej transformacji cosinusa. W cyfrowym wideo, a raczej rejestrując zmianę jasności lub koloru wideo jako zwykłe wartości, takie jak 110 112 115 116, każda jest odejmowana od ostatniej (podobnie jak kodowanie długości przebiegu). 110 112 115 116 110 2 3 1 Wartości, 2 3 1 wymagają mniej bitów niż oryginały.
Powiedzmy więc, że tworzymy Listę wartości wejściowych, gdy pojawią się na gnieździe. Jesteśmy przechowuje w każdym elemencie nie wartość, ale przesunięcie przed nim. Sortujemy jak idziemy, więc offsety będą tylko pozytywne. Ale offset może mieć szerokość 8 cyfr dziesiętnych, co mieści się w 3 bajtach. Każdy element nie może mieć 3 bajtów, więc musimy je spakować. Możemy użyć górnego bitu każdego bajtu jako "bitu kontynuującego", wskazując, że następny bajt jest częścią liczby, a dolne 7 bitów każdego bajtu musi być połączone. zero jest ważne dla duplikatów.
Jako że lista wypełnia w górę, liczby powinny być zbliżone do siebie, co oznacza, że średnio tylko 1 bajt jest używany do określenia odległości do następnej wartości. 7 bitów wartości i 1 bit offsetu, jeśli jest to wygodne, ale może istnieć sweet spot, który wymaga mniej niż 8 bitów dla wartości "continue".
W każdym razie, zrobiłem jakiś eksperyment. Używam generatora liczb losowych i mogę zmieścić milion posortowanych 8 cyfr dziesiętnych w około 1279000 bajtów. Średnia przestrzeń między każdą liczbą wynosi konsekwentnie 99...
public class Test {
public static void main(String[] args) throws IOException {
// 1 million values
int[] values = new int[1000000];
// create random values up to 8 digits lrong
Random random = new Random();
for (int x=0;x<values.length;x++) {
values[x] = random.nextInt(100000000);
}
Arrays.sort(values);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int av = 0;
writeCompact(baos, values[0]); // first value
for (int x=1;x<values.length;x++) {
int v = values[x] - values[x-1]; // difference
av += v;
System.out.println(values[x] + " diff " + v);
writeCompact(baos, v);
}
System.out.println("Average offset " + (av/values.length));
System.out.println("Fits in " + baos.toByteArray().length);
}
public static void writeCompact(OutputStream os, long value) throws IOException {
do {
int b = (int) value & 0x7f;
value = (value & 0x7fffffffffffffffl) >> 7;
os.write(value == 0 ? b : (b | 0x80));
} while (value != 0);
}
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-24 09:23:17
Możemy pobawić się stosem sieciowym, aby wysłać liczby w uporządkowanej kolejności, zanim będziemy mieli wszystkie liczby. Jeśli wyślesz 1M danych, TCP / IP podzieli je na 1500 bajtowe pakiety i prześle je strumieniowo do celu. Każdy pakiet otrzyma numer sekwencji.
Możemy to zrobić ręcznie. Tuż przed wypełnieniem naszego RAM możemy posortować to, co mamy i wysłać listę do naszego celu, ale pozostawić dziury w naszej sekwencji wokół każdego numeru. Następnie przetwarzaj 2. 1/2 liczb w ten sam sposób używając tych dziur w sekwencji.
Stos sieciowy na drugim końcu zmontuje wynikowy strumień danych w kolejności kolejności przed przekazaniem go aplikacji.
Używa sieci do sortowania scalającego. To jest totalny hack, ale zainspirował mnie inny hack sieci wymienione wcześniej.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 21:27:17
Google 's (bad) approach, from HN thread. Sklep RLE-styl liczy.
Twoja początkowa struktura danych to '99999999:0' (wszystkie zera, nie widziałem żadnych liczb), a następnie powiedzmy, że widzisz liczbę 3,866,344 więc twoja struktura danych staje się '3866343 :0,1:1,96133654:0' jak widać liczby zawsze będą naprzemiennie między liczbą bitów zero i liczbą bitów '1', więc możesz po prostu założyć, że liczby nieparzyste reprezentują bity 0, a parzyste 1 bity. To staje się (3866343,1,96133654)
Ich problem nie obejmuje duplikatów, ale powiedzmy, że używają "0: 1" dla duplikatów.
Wielki problem # 1: wstawianie 1M liczb całkowitych zajęłoby wieki.
Wielki problem #2: Jak wszystkie rozwiązania kodowania delta, niektóre dystrybucje nie mogą być opisane w ten sposób. Na przykład 1m liczby całkowite o odległościach 0: 99 (np. + 99 każda). Teraz pomyśl tak samo, ale z odległością losową w przedziale 0: 99. (Uwaga: 99999999/1000000 = 99.99)
Podejście Google jest zarówno niegodne (powolne), jak i nieprawidłowe. Ale na ich obronę, ich problem mógł być nieco inny.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 22:34:11
Aby reprezentować posortowaną tablicę można po prostu zapisać pierwszy element i różnicę między sąsiednimi elementami. W ten sposób zajmujemy się kodowaniem elementów 10^6, które mogą sumować się maksymalnie do 10^8. Nazwijmy to D. Do kodowania elementów D można użyć kodu Huffmana . Słownik dla kodu Huffmana może być tworzony w drodze, a tablica jest aktualizowana za każdym razem, gdy nowy element zostanie wstawiony do sortowanej tablicy (sortowanie wstawiania). Zauważ, że gdy zmiany w słowniku z powodu nowej pozycji cała tablica powinna być zaktualizowana, aby pasowała do nowego kodowania.
Średnia liczba bitów dla kodowania każdego elementu D jest maksymalizowana, jeśli mamy taką samą liczbę każdego unikalnego elementu. Say elements d1, d2 ,..., dN W D każdy pojawia się F razy. W takim przypadku (w najgorszym przypadku mamy zarówno 0 jak i 10^8 w sekwencji wejściowej) mamy
Sum (1iN ) F . di = 10^8
Gdzie
Sum (1iN) F = 10^6, lub F=10^6/N i znormalizowaną częstotliwością będzie p= F/10^=1/N
Średnia liczba bitów będzie wynosić-log2(1/P ) = log2 (N ). W tych okolicznościach powinniśmy znaleźć przypadek, który maksymalizuje N . Dzieje się tak, jeśli mamy kolejne liczby dla di począwszy od 0, or, di= i-1, zatem
10^8=sum (1iN) F . di = sum (1iN) (10^6/N ) (i-1) = (10^6/N) N (N-1)/2
Tzn.
N D w ogóle nie może mieć więcej niż 201 elementów. Wynika tylko, że jeśli elementy D są równomiernie rozłożone, to nie może mieć więcej niż 201 unikalnych wartości.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-22 01:59:14
Wykorzystałbym zachowanie retransmisji TCP.
- niech komponent TCP utworzy duże okno odbioru.
- Otrzymuj pewną ilość pakietów bez wysyłania dla nich ACK.
- przetwarza te w przejściach tworząc pewną (prefiks) skompresowaną strukturę danych
- Wyślij duplikat ack dla ostatniego pakietu, który nie jest już potrzebny / poczekaj na limit czasu retransmisji
- Goto 2
- wszystkie pakiety zostały zaakceptowane
Zakłada to, że niektóre rodzaj korzyści z wiadra lub wielokrotnych przejazdów.
Prawdopodobnie sortując partie / wiadra i łącząc je. - >drzewa radix
Użyj tej techniki, aby zaakceptować i posortować pierwsze 80%, a następnie odczytać ostatnie 20%, sprawdzić, czy ostatnie 20% Nie zawiera liczb, które wylądowałyby w pierwszych 20% najniższych liczb. Następnie wyślij 20% najniższych liczb, usuń z pamięci, Zaakceptuj pozostałe 20% nowych liczb i połącz.**
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-10-11 15:14:48
Gdyby strumień wejściowy mógł być odbierany kilka razy to byłoby dużo łatwiejsze (brak informacji o tym, pomyśle i problemie z czasem).
Wtedy możemy policzyć wartości dziesiętne. Przy liczonych wartościach będzie to łatwe tworzenie strumienia wyjściowego. Kompresuj, licząc wartości. Informatyka zależy co będzie w strumieniu wejściowym.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-10-11 15:22:31
Gdyby strumień wejściowy mógł zostać odebrany kilka razy, byłoby to o wiele łatwiejsze(brak informacji o tym, idei i problemach z czasem). Następnie możemy policzyć wartości dziesiętne. Z zliczonymi wartościami łatwo byłoby utworzyć strumień wyjściowy. Kompresuj, licząc wartości. To zależy, co będzie w strumieniu wejściowym.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-20 22:33:55
Sortowanie jest tutaj drugorzędnym problemem. Jak inni mówili, samo przechowywanie liczb całkowitych jest trudne i nie może działać na wszystkich wejściach , ponieważ potrzebne byłoby 27 bitów na liczbę.
Moje podejście do tego jest następujące: przechowuj tylko różnice między kolejnymi (posortowanymi) liczbami całkowitymi, ponieważ będą one najprawdopodobniej małe. Następnie użyj schematu kompresji, np. z 2 dodatkowymi bitami na liczbę wejściową, aby zakodować, ile bitów numer jest przechowywany. Coś w stylu:
00 -> 5 bits
01 -> 11 bits
10 -> 19 bits
11 -> 27 bits
Powinno być możliwe zapisanie odpowiedniej liczby możliwych list wejściowych w ramach danego ograniczenia pamięci. Matematyka, jak wybrać schemat kompresji, aby działał na maksymalnej liczbie wejść, jest poza mną.
Mam nadzieję, że będziesz w stanie wykorzystać specyficzną dla domeny wiedzę o Twoim wkładzie, aby znaleźć wystarczająco dobry Schemat kompresji całkowitej na tej podstawie.
Oh, a następnie, robisz sortowanie wstawiania na tej posortowanej liście, gdy otrzymujesz dane.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 21:57:51
Teraz zmierzamy do rzeczywistego rozwiązania, obejmującego wszystkie możliwe przypadki wejścia w zakresie 8 cyfr z tylko 1MB pamięci RAM. Uwaga: prace w toku, jutro będą kontynuowane. Używając arytmetycznego kodowania delt sortowanych int, najgorszy przypadek dla 1m sortowanych int kosztowałby około 7 bitów na wpis (ponieważ 99999999/1000000 to 99, a log2(99) to prawie 7 bitów).
Ale musisz posortować liczby całkowite 1m, aby dostać się do 7 lub 8 bitów! Krótsze serie miałyby większe delty, dlatego więcej bitów na element.
Pracuję nad pobraniem jak największej ilości i kompresowaniem (prawie) w miejscu. Pierwsza partia blisko 250k int potrzebowałaby około 9 bitów każdy w najlepszym przypadku. Więc wynik zajęłby około 275KB. Powtórz z pozostałą wolną pamięcią kilka razy. Następnie dekompresuj-merge-in-place-Kompresuj te skompresowane kawałki. To jest dość trudne , ale możliwe. Tak myślę.
Scalone listy zbliżają się coraz bliżej do 7-bitowego celu na liczbę całkowitą. Ale nie wiem ile iteracji to zrobiłby pętlę scalania. Może trzy.
Ale nieprecyzyjność implementacji kodowania arytmetycznego może to uniemożliwić. Jeśli ten problem jest w ogóle możliwy, byłby bardzo ciasny.
Jacyś ochotnicy?
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 23:12:29
Musisz tylko zapisać różnice między liczbami w sekwencji i użyć kodowania, aby skompresować te liczby sekwencyjne. Mamy 2^23 bity. Dzielimy ją na 6-bitowe kawałki, a ostatni bit wskazuje, czy liczba rozszerza się na kolejne 6 bitów (5-bitowe Plus rozszerzający się fragment).
Zatem 000010 to 1, A 000100 to 2. 000001100000 jest 128. Teraz rozważamy najgorszą obsadę w reprezentowaniu różnic w sekwencji liczb do 10 000 000. Może być 10 000 000/2^5 różnice większe niż 2^5, 10 000 000/2^10 Różnice większe niż 2^10 i 10 000 000/2^15 różnice większe niż 2^15 itp.
Dodajemy więc, ile bitów zajmie przedstawienie naszej sekwencji. Mamy 1,000,000*6 + roundup(10,000,000/2^5)*6+roundup(10,000,000/2^10)*6+roundup(10,000,000/2^15)*6+roundup(10,000,000/2^20)*4=7935479.
2^24 = 8388608. Ponieważ 8388608 > 7935479, powinniśmy mieć wystarczająco dużo pamięci. Prawdopodobnie będziemy potrzebować jeszcze trochę pamięci, aby Zapisz sumę gdzie są, gdy wstawiamy nowe liczby. Następnie przechodzimy przez sekwencję i znajdujemy, gdzie wstawić nasz nowy numer, zmniejszamy następną różnicę w razie potrzeby i przesuwamy wszystko po niej w prawo.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-22 04:50:37
Jeśli nie wiemy nic o tych liczbach, jesteśmy ograniczeni następującymi ograniczeniami:
- musimy załadować wszystkie liczby, zanim będziemy mogli je posortować,
- zbiór liczb nie jest kompresowalny.
Jeśli te założenia się utrzymają, nie ma możliwości wykonania zadania, ponieważ będziesz potrzebował co najmniej 26 575 425 bitów pamięci (3 321 929 bajtów).
Co możesz nam powiedzieć o swoich danych ?
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-22 09:30:31
Sztuką jest reprezentowanie stanu algorytmów, który jest liczbą całkowitą, jako skompresowanego strumienia "licznik przyrostu" ="+ "i"licznik wyjścia"="!"postacie. Na przykład zbiór {0,3,3,4} będzie reprezentowany jako"!+++!!+!", po której następuje dowolna liczba znaków"+". Aby zmodyfikować zestaw multi, przesyłaj strumieniowo znaki, zachowując tylko stałą ilość dekompresji na raz, i dokonuj zmian w miejscu przed streamowaniem ich z powrotem w skompresowanym forma.
Szczegóły
Wiemy, że w ostatecznym zestawie jest dokładnie 10^6 liczb, więc jest ich co najwyżej 10^6 "!"postacie. Wiemy również, że nasz asortyment ma rozmiar 10^8, co oznacza, że są co najwyżej 10^8 znaków"+". Liczba sposobów możemy zorganizować 10^6"!"S wśród 10^8 "+ " S jest (10^8 + 10^6) choose 10^6, a więc określenie jakiegoś konkretnego układu zajmuje ~0,965 MiB` danych. Będzie ciasno.
Możemy traktować każdy znak jako niezależny bez przekraczania naszego limitu. Jest dokładnie 100 razy więcej znaków "+" niż "!"znaki, co upraszcza do 100: 1 szanse każdej postaci jest"+", jeśli zapomnimy, że są one zależne. Kurs 100:101 odpowiada ~0.08 bitów na znak , dla prawie identycznej sumy ~0.965 MiB (ignorowanie zależności ma koszt tylko ~12 bitów w tym przypadku!).
Najprostszą techniką zapisu znaków niezależnych o znanym prawdopodobieństwie wcześniejszym jestkodowanie Huffmana . Zauważ, że potrzebujemy niepraktycznie dużego drzewa (drzewo Huffmana dla bloków 10 znaków ma średni koszt na blok około 2,4 bitów, w sumie ~2,9 Mib. Drzewo Huffmana dla bloków 20 znaków ma średni koszt na blok około 3 bitów, co w sumie wynosi ~1,8 MiB. Prawdopodobnie będziemy potrzebować bloku wielkości rzędu stu, co oznacza więcej węzłów w naszym drzewie, niż cały sprzęt komputerowy, który kiedykolwiek istniał, może przechowywać.). Jednak ROM jest technicznie " wolny" według problemu i praktycznych rozwiązań, które wykorzystują regularność w drzewie będzie wyglądać zasadniczo tak samo.
Pseudo-kod
- W pamięci ROM zapisywane są odpowiednio duże drzewa Huffmana (lub podobne dane kompresji blok po bloku).]}
- zacznij od skompresowanego ciągu znaków 10^8"+".
- aby wstawić liczbę N, przeciągnij skompresowany łańcuch, aż N " + "przeminie, a następnie wstaw"!". Stream the recompressed ciągnij z powrotem do poprzedniego, zachowując stałą ilość buforowanych bloków, aby uniknąć over/under-runów.
- powtórz milion razy: [input, stream decompress>insert>compress], następnie dekompresuj do wyjścia
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-24 04:43:33
Mamy 1 MB - 3 KB RAM = 2^23 - 3*2^13 bity = 8388608-24576 = 8364032 dostępne bity.
Otrzymujemy liczby 10^6 w zakresie 10^8. Daje to średnią lukę ~100
Najpierw rozważmy prostszy problem dość równomiernie rozmieszczonych liczb, gdy wszystkie luki są
(27 bitów) + 10^6 cyfr 7-bitowych = wymagane 7000027 bitów
Uwaga powtarzające się liczby mają luki 0.
Ale co jeśli mamy luki większe niż 127?
Ok, powiedzmy, że rozmiar odstępu
10xxxxxx xxxxxxxx = 127 .. 16,383
110xxxxx xxxxxxxx xxxxxxxx = 16384 .. 2,097,151
Itd.
Zauważ, że ta reprezentacja liczb opisuje własną długość, więc wiemy, kiedy zaczyna się następna liczba odstępów.
Z małymi przerwami
Może być do (10^8)/(2^7) = 781250 23-liczba szczelin bitowych, Wymaganie dodatkowego 16 * 781,250 = 12,500,000 bitów, co jest za dużo. Potrzebujemy bardziej zwartej i powoli rosnącej reprezentacji luk.
Średnia wielkość luki wynosi 100, więc jeśli zmienimy ich kolejność jako [100, 99, 101, 98, 102, ..., 2, 198, 1, 199, 0, 200, 201, 202, ...] i indeksować to gęstą binarną bazą Fibonacciego bez par zer (np., 11011=8+5+2+1=16) z liczbami oddzielonymi przez '00' to myślę, że możemy utrzymać reprezentację luki wystarczająco krótko, ale potrzebuje więcej analiza.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-10-11 15:20:45
Podczas odbierania strumienia wykonaj następujące kroki.
1st set some reasonable chunk size
Idea Pseudo kodu:
- pierwszym krokiem byłoby znalezienie wszystkich duplikatów i umieszczenie ich w słowniku z licznikiem i usunięcie ich.
- trzecim krokiem byłoby umieszczenie liczby, które istnieją w sekwencji ich kroków algorytmicznych i umieszczenie ich w licznikach specjalnych słowników z liczbą pierwszą i ich krokiem N, n + 1 ... ,n+2, 2n, 2n+1, 2N+2...
- Zacznij kompresować w kawałkach kilka rozsądnych zakresów liczb, takich jak co 1000 lub kiedykolwiek 10000, pozostałe liczby, które pojawiają się rzadziej do powtórzenia.
- Rozpakuj ten zakres, jeśli liczba zostanie znaleziona, i dodaj go do zakresu i pozostaw na dłużej nieskompresowany.
- w przeciwnym razie wystarczy dodać tę liczbę do bajtu [chunkSize]
Kontynuuj pierwsze 4 kroki podczas odbierania strumienia. Ostatnim krokiem byłoby niepowodzenie w przypadku przekroczenia pamięci lub rozpoczęcia wysyłania wynik po zebraniu wszystkich danych, zaczynając sortować zakresy i wypluwać wyniki w kolejności i dekompresować te w kolejności, które należy rozpakować i sortować je, gdy do nich dotrzesz.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-12-02 21:31:17
To jest przy założeniu bazy 10 i jako przykład, twoja pamięć używa słów 8-bitowych: Pamięć mapuje cały zakres liczb przy użyciu 3-bitowych przyrostów. Pierwsze 3 bity odpowiadałyby liczbie 0. Drugi zestaw 3 bitów oznaczałby numer 1. Trzysta tysięczny zestaw 3-bitowych map do liczby 300k. powtórz to, dopóki nie zmapujesz wszystkich 8 cyfr. Gdyby zakres pamięci był ciągły, uzyskałoby to łącznie 375k bajtów.
Pierwszy bit z 3 oznaczałby obecność numeru. Kolejne 2 bity wskazywałyby ilość duplikatów, które mogłyby być reprezentowane w bajtach (1..3) Jeśli nie, Pole duplikaty będzie 00. Pojawi się druga lista, która używa licznika, który zwiększa się za każdym razem, gdy pole 3 bitowe jest oznaczone jako posiadające duplikat. Jeśli jest oznaczony 1, będzie miał pojedynczy zakres bitów, aby policzyć ilość duplikatów, które ma. 8 bitów może reprezentować zakres 255.
Ponieważ tracę poczucie myśli. Druga lista będzie śledzić, jak wiele duplikatów dla każdej liczby. jeśli 255. liczba ma duplikat i jest pierwszą liczbą, która ma duplikat, indeks na liście będzie wynosił 0. Jeśli 23543 jest drugą liczbą, która ma duplikat, jej indeks będzie równy 1. Umyć, wstać i powtórzyć.
Najgorszy scenariusz to 500 tysięcy liczb z duplikatami. Może to być reprezentowane przez pojedynczy bajt (ponieważ 1 pasuje w easy). Czyli 375kb (najlepiej) + 500KB bajtów jest blisko .875MB. W zależności od procesora powinno to pozostawić wystarczająco dużo miejsca do wskaźników, indeksowania i innych fajnych rzeczy.
Jeśli masz pojedynczy numer, który ma 1m duplikatów. wszystko, czego potrzebujesz, to 3 bajty, ponieważ twoje numery ograniczone do 1M, to wszystko, o co musisz się martwić. Więc na drugiej liście będzie to po prostu 3 byes z całkowitą kwotą.
Teraz dla Zabawy. Druga lista będzie musiała być posortowana dla każdego nowego numeru, który się pojawi. W polu 3 bit ostatnie 2 to liczba bajtów, która zawiera liczbę duplikatów. Ponieważ oczekuje się, że druga lista będzie w kolejności, w jakiej będzie musiała zostać posortowana. Ponieważ ilość bajtów może się różnić. Pomyśl o tym!
To utrzyma ilość wskaźników i rzeczy, które musisz zwiększyć do minimum, więc powinieneś mieć trochę elastyczności z może 250k bajtów lewo.
GoodLuck! To brzmi o wiele bardziej elegancko w moim umyśle...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-22 05:14:38