Jak sortować ramkę danych według wielu kolumn?
Chcę sortować dane.ramka z wieloma kolumnami. Na przykład z danymi.ramka poniżej chciałbym posortować po kolumnie z (malejąco) następnie po kolumnie b (rosnąco):
dd <- data.frame(b = factor(c("Hi", "Med", "Hi", "Low"),
levels = c("Low", "Med", "Hi"), ordered = TRUE),
x = c("A", "D", "A", "C"), y = c(8, 3, 9, 9),
z = c(1, 1, 1, 2))
dd
b x y z
1 Hi A 8 1
2 Med D 3 1
3 Hi A 9 1
4 Low C 9 2
16 answers
Możesz użyć order() funkcja bezpośrednio bez uciekania się do narzędzi dodatkowych -- zobacz tę prostszą odpowiedź, która wykorzystuje sztuczkę od góry kodu example(order):
R> dd[with(dd, order(-z, b)), ]
b x y z
4 Low C 9 2
2 Med D 3 1
1 Hi A 8 1
3 Hi A 9 1
Edytuj jakieś 2 + lata później: po prostu pytano, jak to zrobić przez indeks kolumn. Odpowiedź brzmi: po prostu przekazać żądaną kolumnę (kolumny) sortowania do funkcji order():
R> dd[order(-dd[,4], dd[,1]), ]
b x y z
4 Low C 9 2
2 Med D 3 1
1 Hi A 8 1
3 Hi A 9 1
R>
Zamiast używać nazwy kolumny (i {[5] } dla łatwiejszego / bardziej bezpośredniego dostępu).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-09-21 13:42:37
Twoje wybory]}
-
orderodbase -
arrangeoddplyr -
setorderisetordervoddata.table -
arrangeodplyr -
sortodtaRifx -
orderByoddoBy -
sortDataodDeducer
Przez większość czasu powinieneś używać rozwiązań dplyr lub data.table, chyba że posiadanie bez zależności jest ważne, w którym to przypadku użyj base::order.
Ostatnio dodałem sortowanie.data.ramka do paczki CRAN, uczynienie go zgodnym z klasą, jak omówiono tutaj: najlepszy sposób na stworzenie spójności generycznej / metody dla sortowania.data.rama?
Dlatego, biorąc pod uwagę dane.ramka dd, można sortować w następujący sposób:
dd <- data.frame(b = factor(c("Hi", "Med", "Hi", "Low"),
levels = c("Low", "Med", "Hi"), ordered = TRUE),
x = c("A", "D", "A", "C"), y = c(8, 3, 9, 9),
z = c(1, 1, 1, 2))
library(taRifx)
sort(dd, f= ~ -z + b )
Jeśli jesteś jednym z oryginalnych autorów tej funkcji, skontaktuj się ze mną. Dyskusja na temat domeny publicznej jest tutaj: http://chat.stackoverflow.com/transcript/message/1094290#1094290
Możesz również użyć funkcji arrange() Z plyr jako Hadley w powyższym wątku:
library(plyr)
arrange(dd,desc(z),b)
Benchmarki: zauważ, że załadowałem każdy pakiet w nowej sesji R, ponieważ było wiele konfliktów. W szczególności załadowanie pakietu doBy powoduje, że sort zwraca "następujące obiekty są maskowane z 'X(pozycja 17)': b, x, y, z", A załadowanie pakietu dedukcyjnego nadpisuje sort.data.frame Z Kevina Wrighta lub pakietu taRifx.
#Load each time
dd <- data.frame(b = factor(c("Hi", "Med", "Hi", "Low"),
levels = c("Low", "Med", "Hi"), ordered = TRUE),
x = c("A", "D", "A", "C"), y = c(8, 3, 9, 9),
z = c(1, 1, 1, 2))
library(microbenchmark)
# Reload R between benchmarks
microbenchmark(dd[with(dd, order(-z, b)), ] ,
dd[order(-dd$z, dd$b),],
times=1000
)
Mediana czasu:
dd[with(dd, order(-z, b)), ] 778
dd[order(-dd$z, dd$b),] 788
library(taRifx)
microbenchmark(sort(dd, f= ~-z+b ),times=1000)
Mediana czasu: 1,567
library(plyr)
microbenchmark(arrange(dd,desc(z),b),times=1000)
Mediana czasu: 862
library(doBy)
microbenchmark(orderBy(~-z+b, data=dd),times=1000)
Mediana czasu: 1,694
Zauważ, że doby zajmuje sporo czasu, aby załadować pakiet.
library(Deducer)
microbenchmark(sortData(dd,c("z","b"),increasing= c(FALSE,TRUE)),times=1000)
esort <- function(x, sortvar, ...) {
attach(x)
x <- x[with(x,order(sortvar,...)),]
return(x)
detach(x)
}
microbenchmark(esort(dd, -z, b),times=1000)
Wydaje się, że nie jest kompatybilny z microbenchmark z powodu podłączenia/odłączenia.
m <- microbenchmark(
arrange(dd,desc(z),b),
sort(dd, f= ~-z+b ),
dd[with(dd, order(-z, b)), ] ,
dd[order(-dd$z, dd$b),],
times=1000
)
uq <- function(x) { fivenum(x)[4]}
lq <- function(x) { fivenum(x)[2]}
y_min <- 0 # min(by(m$time,m$expr,lq))
y_max <- max(by(m$time,m$expr,uq)) * 1.05
p <- ggplot(m,aes(x=expr,y=time)) + coord_cartesian(ylim = c( y_min , y_max ))
p + stat_summary(fun.y=median,fun.ymin = lq, fun.ymax = uq, aes(fill=expr))
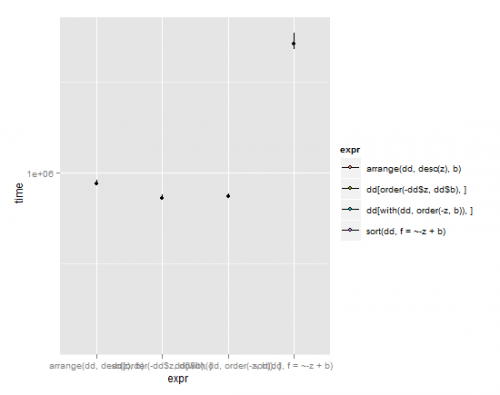
(linie rozciągają się od dolnego kwartylu do górnego kwartyl, kropka jest medianą)
Biorąc pod uwagę te wyniki i ważenie prostota vs. prędkość, musiałbym dać ukłon w stronę arrange w opakowaniu plyr . Ma prostą składnię, a jednak jest prawie tak szybki jak podstawowe polecenia R z ich zawiłymi machinacjami. Typowo genialna praca Hadleya Wickhama. Moim jedynym zmartwieniem jest to, że łamie standardową nomenklaturę R, gdzie sortowanie obiektów jest wywoływane przez sort(object), ale rozumiem, dlaczego Hadley zrobił to w ten sposób z powodu problemów omówione w powyższym pytaniu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-09-05 08:21:21
Odpowiedź Dirka jest świetna. Zwraca również uwagę na kluczową różnicę w składni używanej do indeksowania data.frame s I data.table S:
## The data.frame way
dd[with(dd, order(-z, b)), ]
## The data.table way: (7 fewer characters, but that's not the important bit)
dd[order(-z, b)]
Różnica między tymi dwoma wywołaniami jest niewielka, ale może mieć ważne konsekwencje. Zwłaszcza, jeśli piszesz kod produkcyjny i / lub martwisz się poprawnością w swoich badaniach, najlepiej unikać niepotrzebnego powtarzania nazw zmiennych. data.table
pomaga Ci to zrobić.
Oto przykład jak powtarzanie nazw zmiennych może doprowadzić cię do problem:
Zmieńmy kontekst z odpowiedzi Dirka i powiedzmy, że jest to część większego projektu, w którym istnieje wiele nazw obiektów, które są długie i znaczące; zamiast dd nazywa się quarterlyreport. Staje się:
quarterlyreport[with(quarterlyreport,order(-z,b)),]
lastquarterlyreport w różnych miejscach i jakoś (jak u licha?) you end up with this :
quarterlyreport[with(lastquarterlyreport,order(-z,b)),]
Nie to miałeś na myśli, ale nie zauważyłeś tego, ponieważ zrobiłeś to szybko i jest umieszczony na stronie podobnego kodu. Kod się nie przewraca (bez ostrzeżenia i bez błędu), ponieważ R uważa, że o to chodziło. Miałbyś nadzieję, że ktokolwiek czyta Twój raport, zauważy go, ale może nie. jeśli dużo pracujesz z językami programowania, to ta sytuacja może być znana. To była literówka. Naprawię literówkę, którą powiesz szefowi.
W data.table martwią nas takie drobiazgi. Zrobiliśmy więc coś prostego, aby uniknąć dwukrotnego wpisywania nazw zmiennych. Coś bardzo prostego. i jest oceniana w ramce dd już automatycznie. W ogóle nie potrzebujesz.
Zamiast
dd[with(dd, order(-z, b)), ]
It ' s just
dd[order(-z, b)]
I zamiast
quarterlyreport[with(lastquarterlyreport,order(-z,b)),]
It ' s just
quarterlyreport[order(-z,b)]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-05-25 21:42:51
Jest tu wiele doskonałych odpowiedzi, ale dplyr daje jedyną składnię, którą mogę szybko i łatwo zapamiętać (a więc teraz używać bardzo często):
library(dplyr)
# sort mtcars by mpg, ascending... use desc(mpg) for descending
arrange(mtcars, mpg)
# sort mtcars first by mpg, then by cyl, then by wt)
arrange(mtcars , mpg, cyl, wt)
Dla problemu OP:
arrange(dd, desc(z), b)
b x y z
1 Low C 9 2
2 Med D 3 1
3 Hi A 8 1
4 Hi A 9 1
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-02-18 21:29:25
Pakiet R data.table zapewnia zarówno szybkie , jak i wydajne pamięci porządkowanie danych .tabele z prostą składnią(część, którą Matt ładnie wyróżnił w swojej odpowiedzi ). Od tego czasu wprowadzono sporo ulepszeń, a także nową funkcję setorder(). Od v1.9.5+, setorder() działa również z danymi .ramki .
Najpierw stworzymy zbiór danych wystarczająco duży i porównamy różne metody wymienione z innymi odpowiedzi, a następnie wymień cechy danych .tabela .
Data:
require(plyr)
require(doBy)
require(data.table)
require(dplyr)
require(taRifx)
set.seed(45L)
dat = data.frame(b = as.factor(sample(c("Hi", "Med", "Low"), 1e8, TRUE)),
x = sample(c("A", "D", "C"), 1e8, TRUE),
y = sample(100, 1e8, TRUE),
z = sample(5, 1e8, TRUE),
stringsAsFactors = FALSE)
Benchmarki:
Podane czasy pochodzą z uruchomienia system.time(...) na tych funkcjach pokazanych poniżej. Czasy są tabelaryczne poniżej (w kolejności od najwolniejszego do najszybszego).
orderBy( ~ -z + b, data = dat) ## doBy
plyr::arrange(dat, desc(z), b) ## plyr
arrange(dat, desc(z), b) ## dplyr
sort(dat, f = ~ -z + b) ## taRifx
dat[with(dat, order(-z, b)), ] ## base R
# convert to data.table, by reference
setDT(dat)
dat[order(-z, b)] ## data.table, base R like syntax
setorder(dat, -z, b) ## data.table, using setorder()
## setorder() now also works with data.frames
# R-session memory usage (BEFORE) = ~2GB (size of 'dat')
# ------------------------------------------------------------
# Package function Time (s) Peak memory Memory used
# ------------------------------------------------------------
# doBy orderBy 409.7 6.7 GB 4.7 GB
# taRifx sort 400.8 6.7 GB 4.7 GB
# plyr arrange 318.8 5.6 GB 3.6 GB
# base R order 299.0 5.6 GB 3.6 GB
# dplyr arrange 62.7 4.2 GB 2.2 GB
# ------------------------------------------------------------
# data.table order 6.2 4.2 GB 2.2 GB
# data.table setorder 4.5 2.4 GB 0.4 GB
# ------------------------------------------------------------
data.table'SDT[order(...)]składnia była ~10x szybsza niż najszybsza z innych metod (dplyr), zużywając tyle samo pamięci codplyr.data.table'Ssetorder()was ~14x szybciej niż najszybsza z innych metod (dplyr), przy jednoczesnym pobraniu tylko 0,4 GB dodatkowej pamięci .datjest teraz w wymaganej kolejności (jak to jest aktualizowane przez odniesienie).
Data.cechy tabeli:
Prędkość:
data.kolejność w tabeli jest niezwykle szybka, ponieważ implementuje kolejność radix .
Składnia
DT[order(...)]jest wewnętrznie zoptymalizowana pod kątem użycia danych .tabela 's fast zamawiam również. Możesz nadal używać znanej składni base R, ale przyspieszyć proces (i zużywać mniej pamięci).
Pamięć:
-
W większości przypadków nie wymagamy oryginalnych danych.ramka lub dane.tabela Po zmianie kolejności. Oznacza to, że zwykle przypisujemy wynik z powrotem do tego samego obiektu, na przykład:
DF <- DF[order(...)]Problem polega na tym, że wymaga to co najmniej dwukrotnie (2x) pamięci oryginalnego obiektu. Być wydajna pamięć, data.tabela zawiera zatem również funkcję
setorder().setorder()Zmiana kolejności danych.tabeleby reference(in-place ), bez tworzenia dodatkowych kopii. Wykorzystuje tylko dodatkową pamięć równą wielkości jednej kolumny.
Inne cechy:
-
Obsługuje
integer,logical,numeric,characteri nawetbit64::integer64typy.Zauważ, że
factor,Date,POSIXctitd.. zajęcia są wszystkieinteger/numerictypy pod spodem z dodatkowymi atrybutami i dlatego są również obsługiwane. -
W bazie R nie możemy użyć
-na wektorze znaków do sortowania według tej kolumny w porządku malejącym. Zamiast tego musimy użyć-xtfrm(.).Jednak w danych.tabela , możemy po prostu zrobić, na przykład,
dat[order(-x)]lubsetorder(dat, -x).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 10:31:37
Dzięki tej (bardzo pomocnej) funkcji autorstwa Kevina Wrighta , opublikowanej w sekcji Porady na R wiki, można to łatwo osiągnąć.
sort(dd,by = ~ -z + b)
# b x y z
# 4 Low C 9 2
# 2 Med D 3 1
# 1 Hi A 8 1
# 3 Hi A 9 1
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-08-24 14:49:59
Lub możesz użyć pakietu doby
library(doBy)
dd <- orderBy(~-z+b, data=dd)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-01-19 20:44:38
Załóżmy, że masz data.frame A i chcesz go posortować za pomocą kolumny o nazwie x malejąco. Call the posorted data.frame newdata
newdata <- A[order(-A$x),]
Jeśli chcesz porządku rosnącego, zastąp "-" niczym. Możesz mieć coś takiego
newdata <- A[order(-A$x, A$y, -A$z),]
Gdzie x i z to kolumny w data.frame A. Oznacza to sortowanie data.frame A by x malejąco, y rosnąco i z malejąco.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-05-26 15:21:27
Alternatywnie, używając dedukcji pakietu
library(Deducer)
dd<- sortData(dd,c("z","b"),increasing= c(FALSE,TRUE))
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-08-20 19:43:30
Jeśli SQL przychodzi ci naturalnie, sqldf obsługuje kolejność według przeznaczenia Codd.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-08 23:30:37
Dowiedziałem się o order z poniższym przykładem, który potem mylił mnie przez długi czas:
set.seed(1234)
ID = 1:10
Age = round(rnorm(10, 50, 1))
diag = c("Depression", "Bipolar")
Diagnosis = sample(diag, 10, replace=TRUE)
data = data.frame(ID, Age, Diagnosis)
databyAge = data[order(Age),]
databyAge
Ten przykład działa tylko dlatego, że order jest sortowane według vector Age, a nie według kolumny o nazwie Age w data frame data.
Aby to zobaczyć, Utwórz identyczną ramkę danych za pomocą read.table z nieco innymi nazwami kolumn i bez użycia żadnego z powyższych wektorów:
my.data <- read.table(text = '
id age diagnosis
1 49 Depression
2 50 Depression
3 51 Depression
4 48 Depression
5 50 Depression
6 51 Bipolar
7 49 Bipolar
8 49 Bipolar
9 49 Bipolar
10 49 Depression
', header = TRUE)
Powyższa struktura liniowa dla order już nie działa, ponieważ nie ma wektora nazwa age:
databyage = my.data[order(age),]
Poniższy wiersz działa ponieważ order sortuje na kolumnie age w my.data.
databyage = my.data[order(my.data$age),]
Pomyślałem, że warto to opublikować, biorąc pod uwagę, jak zdezorientowany byłem przez ten przykład tak długo. Jeśli ten post nie będzie odpowiedni dla wątku mogę go usunąć.
Edycja: maj 13, 2014
Poniżej przedstawiono uogólniony sposób sortowania ramki danych według każdej kolumny bez podawania nazw kolumn. Poniższy kod pokazuje jak sortować od lewej do w prawo lub od prawej do lewej. To działa, jeśli każda kolumna jest numeryczna. Nie próbowałem z dodaną kolumną znaków.
Znalazłem kod do.call miesiąc lub dwa temu w starym poście na innej stronie, ale dopiero po rozległych i trudnych poszukiwaniach. Nie jestem pewien, czy mógłbym przenieść ten post teraz. Obecny wątek jest pierwszym trafieniem do zamówienia data.frame w R. Pomyślałem więc, że moja rozszerzona wersja oryginalnego kodu do.call może się przydać.
set.seed(1234)
v1 <- c(0,0,0,0, 0,0,0,0, 1,1,1,1, 1,1,1,1)
v2 <- c(0,0,0,0, 1,1,1,1, 0,0,0,0, 1,1,1,1)
v3 <- c(0,0,1,1, 0,0,1,1, 0,0,1,1, 0,0,1,1)
v4 <- c(0,1,0,1, 0,1,0,1, 0,1,0,1, 0,1,0,1)
df.1 <- data.frame(v1, v2, v3, v4)
df.1
rdf.1 <- df.1[sample(nrow(df.1), nrow(df.1), replace = FALSE),]
rdf.1
order.rdf.1 <- rdf.1[do.call(order, as.list(rdf.1)),]
order.rdf.1
order.rdf.2 <- rdf.1[do.call(order, rev(as.list(rdf.1))),]
order.rdf.2
rdf.3 <- data.frame(rdf.1$v2, rdf.1$v4, rdf.1$v3, rdf.1$v1)
rdf.3
order.rdf.3 <- rdf.1[do.call(order, as.list(rdf.3)),]
order.rdf.3
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-05-13 22:53:25
ODPOWIEDŹ Dirka jest dobra, ale jeśli potrzebujesz sortowania do przetrwania, będziesz chciał zastosować sortowanie z powrotem do nazwy tej ramki danych. Użycie przykładowego kodu:
dd <- dd[with(dd, order(-z, b)), ]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-05-26 15:08:39
W odpowiedzi na komentarz dodany w OP za jak sortować programowo:
Za pomocą dplyr i data.table
library(dplyr)
library(data.table)
Dplyr
Wystarczy użyć arrange_, która jest standardową wersją oceny dla arrange.
df1 <- tbl_df(iris)
#using strings or formula
arrange_(df1, c('Petal.Length', 'Petal.Width'))
arrange_(df1, ~Petal.Length, ~Petal.Width)
Source: local data frame [150 x 5]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
(dbl) (dbl) (dbl) (dbl) (fctr)
1 4.6 3.6 1.0 0.2 setosa
2 4.3 3.0 1.1 0.1 setosa
3 5.8 4.0 1.2 0.2 setosa
4 5.0 3.2 1.2 0.2 setosa
5 4.7 3.2 1.3 0.2 setosa
6 5.4 3.9 1.3 0.4 setosa
7 5.5 3.5 1.3 0.2 setosa
8 4.4 3.0 1.3 0.2 setosa
9 5.0 3.5 1.3 0.3 setosa
10 4.5 2.3 1.3 0.3 setosa
.. ... ... ... ... ...
#Or using a variable
sortBy <- c('Petal.Length', 'Petal.Width')
arrange_(df1, .dots = sortBy)
Source: local data frame [150 x 5]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
(dbl) (dbl) (dbl) (dbl) (fctr)
1 4.6 3.6 1.0 0.2 setosa
2 4.3 3.0 1.1 0.1 setosa
3 5.8 4.0 1.2 0.2 setosa
4 5.0 3.2 1.2 0.2 setosa
5 4.7 3.2 1.3 0.2 setosa
6 5.5 3.5 1.3 0.2 setosa
7 4.4 3.0 1.3 0.2 setosa
8 4.4 3.2 1.3 0.2 setosa
9 5.0 3.5 1.3 0.3 setosa
10 4.5 2.3 1.3 0.3 setosa
.. ... ... ... ... ...
#Doing the same operation except sorting Petal.Length in descending order
sortByDesc <- c('desc(Petal.Length)', 'Petal.Width')
arrange_(df1, .dots = sortByDesc)
Więcej informacji tutaj: https://cran.r-project.org/web/packages/dplyr/vignettes/nse.html
Lepiej jest użyć formuły, ponieważ rejestruje ona również środowisko do oceny wyrażenia w
Data.tabela
dt1 <- data.table(iris) #not really required, as you can work directly on your data.frame
sortBy <- c('Petal.Length', 'Petal.Width')
sortType <- c(-1, 1)
setorderv(dt1, sortBy, sortType)
dt1
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1: 7.7 2.6 6.9 2.3 virginica
2: 7.7 2.8 6.7 2.0 virginica
3: 7.7 3.8 6.7 2.2 virginica
4: 7.6 3.0 6.6 2.1 virginica
5: 7.9 3.8 6.4 2.0 virginica
---
146: 5.4 3.9 1.3 0.4 setosa
147: 5.8 4.0 1.2 0.2 setosa
148: 5.0 3.2 1.2 0.2 setosa
149: 4.3 3.0 1.1 0.1 setosa
150: 4.6 3.6 1.0 0.2 setosa
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-02-05 21:11:52
Dla kompletności: możesz również użyć funkcji sortByCol() z pakietu BBmisc:
library(BBmisc)
sortByCol(dd, c("z", "b"), asc = c(FALSE, TRUE))
b x y z
4 Low C 9 2
2 Med D 3 1
1 Hi A 8 1
3 Hi A 9 1
Porównanie wydajności:
library(microbenchmark)
microbenchmark(sortByCol(dd, c("z", "b"), asc = c(FALSE, TRUE)), times = 100000)
median 202.878
library(plyr)
microbenchmark(arrange(dd,desc(z),b),times=100000)
median 148.758
microbenchmark(dd[with(dd, order(-z, b)), ], times = 100000)
median 115.872
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-08-07 04:03:34
Podobnie jak mechaniczne sortowniki kart dawno temu, najpierw posortuj według najmniej znaczącego klucza, potem następnego najbardziej znaczącego, itp. Nie jest wymagana biblioteka, działa z dowolną liczbą klawiszy i dowolną kombinacją klawiszy rosnących i malejących.
dd <- dd[order(dd$b, decreasing = FALSE),]
Teraz jesteśmy gotowi zrobić najważniejszy klucz. Sortowanie jest stabilne, a wszelkie powiązania w najważniejszym kluczu zostały już rozwiązane.
dd <- dd[order(dd$z, decreasing = TRUE),]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-01-15 04:28:25
Inna alternatywa, używając pakietu rgr:
> library(rgr)
> gx.sort.df(dd, ~ -z+b)
b x y z
4 Low C 9 2
2 Med D 3 1
1 Hi A 8 1
3 Hi A 9 1
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-05-01 10:18:19