Dlaczego potrzebujemy brokerów wiadomości takich jak RabbitMQ nad bazą danych taką jak PostgreSQL?
Jestem nowym brokerem komunikatów, takim jak RabbitMQ , którego możemy użyć do tworzenia zadań / kolejek komunikatów dla systemu szeregowania, takiego jak selery .
Oto pytanie:
Mogę utworzyć tabelę w PostgreSQL , która może być dołączana do nowych zadań i zużywana przez program konsumencki, taki jak seler.
Po co mi nowa technologia, taka jak RabbitMQ?
Teraz, Ja wierzymy, że skalowanie nie może być rozwiązaniem, ponieważ nasza baza danych, taka jak PostgreSQL, może działać w środowisku rozproszonym.
Wyszukałem w googlach, jakie problemy stwarza baza danych dla danego problemu i znalazłem:
- ankieta utrzymuje bazę danych zajęty i niskiej wydajności
- blokowanie tabeli - > znowu niska wydajność
- miliony wierszy zadań - > znowu sondaż jest mało wydajny
Teraz, Jak RabbitMQ lub jakikolwiek inny broker wiadomości taki rozwiązuje te problemy?
Również, dowiedziałem się, że AMQP protokół jest tym, co następuje. Co w tym dobrego?
Czy Redis może być również używany jako broker wiadomości? Uważam to za bardziej analogiczne do Memcached niż RabbitMQ.
Proszę rzucić na to trochę światła!2 answers
Kolejki królika znajdują się w pamięci i dlatego będą znacznie szybsze niż implementacja tego w bazie danych. (Dobra)dedykowana Kolejka komunikatów powinna również zapewniać istotne funkcje związane z kolejkowaniem, takie jak dławienie/kontrola przepływu i możliwość wyboru różnych algorytmów routingu, aby wymienić parę(rabbit zapewnia te i więcej). W zależności od wielkości projektu możesz również chcieć, aby komponent przekazujący wiadomości był oddzielony od bazy danych, tak aby w przypadku dużego obciążenia jednego z komponentów obciążenie, nie musi utrudniać pracy drugiej strony.
Co do problemów, o których wspomniałeś:
-
Ankiety utrzymanie bazy danych zajęty i niskiej wydajności: za pomocą Rabbitmq, producenci mogą push aktualizacje konsumentów, który jest znacznie bardziej wydajne niż ankiety. Dane są po prostu wysyłane do konsumenta, gdy jest to konieczne, eliminując potrzebę marnotrawstwa kontroli.
-
Blokowanie tabeli - > znowu niska wydajność: nie ma tabeli do blokowania : P
-
Jak wspomniano powyżej, Rabbitmq będzie działać szybciej, ponieważ znajduje się w pamięci RAM i zapewnia kontrolę przepływu. W razie potrzeby może również użyć dysku do tymczasowego przechowywania wiadomości, Jeśli zabraknie pamięci RAM. Po 2.0 Królik znacznie poprawił zużycie pamięci RAM. Dostępne są również opcje grupowania.
Jeśli chodzi o AMQP, powiedziałbym, że naprawdę fajną funkcją jest "wymiana", A możliwość do innych giełd. Daje to większą elastyczność i umożliwia tworzenie szerokiej gamy skomplikowanych typologii routingu, które mogą być bardzo przydatne podczas skalowania. Dobry przykład:

(źródło: springsource.com)
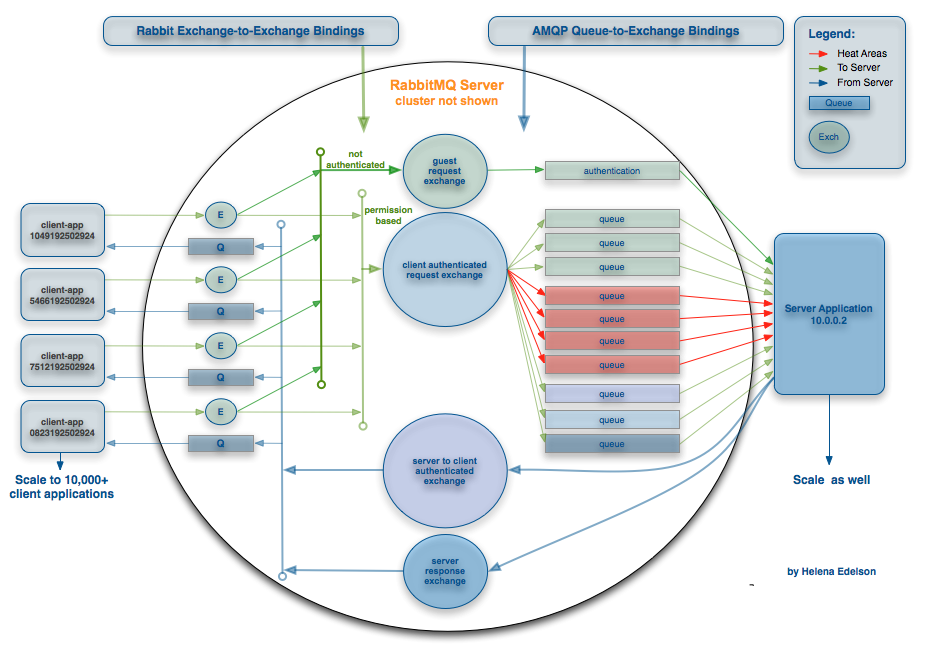{kind=link}
Wreszcie, w odniesieniu do Redis, tak, może być używany jako wiadomość broker, i może zrobić dobrze. Jednak Rabbitmq ma więcej funkcji kolejkowania wiadomości niż Redis, ponieważ rabbitmq został zbudowany od podstaw, aby być w pełni funkcjonalną kolejką dedykowaną na poziomie korporacyjnym. Redis z drugiej strony został stworzony przede wszystkim jako przechowalnia kluczy w pamięci(choć robi znacznie więcej niż teraz; jego nawet określany jako szwajcarski nóż wojskowy). Mimo to czytałem / słyszałem wiele osób osiągających dobre wyniki dzięki Redis dla mniejszych projektów, ale nie słyszałem o tym zbyt wiele w większych aplikacje.
Oto przykład użycia Redis w implementacji czatu długo-sondażowego: http://eflorenzano.com/blog/2011/02/16/technology-behind-convore/
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-12-24 18:56:34
PostgreSQL 9.5
PostgreSQL 9.5 zawiera SELECT ... FOR UPDATE ... SKIP LOCKED. To sprawia, że implementacja pracujących systemów kolejkowych staje się prostsza i łatwiejsza. Możesz już nie wymagać zewnętrznego systemu kolejkowania, ponieważ teraz łatwo jest pobrać " n " wierszy, których żadna inna sesja nie zablokowała, i zachować je zablokowane, dopóki nie zatwierdzisz potwierdzenia, że praca została wykonana. Działa nawet z transakcjami dwufazowymi, gdy wymagana jest koordynacja zewnętrzna.
Zewnętrzne systemy kolejkowe pozostają użyteczne, zapewnienie funkcjonalności, sprawdzonej wydajności, integracja z innymi systemami, opcje skalowania poziomego i Federacji itp. Niemniej jednak w prostych przypadkach już ich nie potrzebujesz.
Starsze Wersje
Nie potrzebujesz takich narzędzi, ale korzystanie z nich może ułatwić życie. Wykonywanie kolejkowania w bazie danych wygląda na łatwe, ale w praktyce odkryjesz, że wydajne i niezawodne równoczesne kolejkowanie jest naprawdę trudne , aby zrobić to dobrze w relacyjnym baza danych.
Dlatego istnieją narzędzia takie jak PGQ.
Możesz pozbyć się pollingu w PostgreSQL używając LISTEN i NOTIFY, ale to nie rozwiąże problemu niezawodnego rozdawania wpisów z góry kolejki dokładnie jednemu konsumentowi, zachowując jednocześnie wysoce współbieżne działanie i nie blokując wstawek. Wszystkie proste i oczywiste rozwiązania, które myślisz, że rozwiążą ten problem, w rzeczywistości nie są w prawdziwym świecie i mają tendencję do degenerowania się do mniej wydajnych wersji pobieranie kolejek dla jednego pracownika.
Jeśli nie potrzebujesz wysoce równoczesnych, wielozadaniowych kolejek, użycie pojedynczej tabeli kolejek w PostgreSQL jest całkowicie rozsądne.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-08-23 08:21:14