Idiomatyczna Wycena opcji i ryzyko przy użyciu równoległych tablic Repa
Załóżmy, że chcę wycenić opcję call za pomocą metody różnicy skończonej i repa wtedy wykonuję następujące zadanie:
import Data.Array.Repa as Repa
r, sigma, k, t, xMax, deltaX, deltaT :: Double
m, n, p :: Int
r = 0.05
sigma = 0.2
k = 50.0
t = 3.0
m = 3
p = 1
xMax = 150
deltaX = xMax / (fromIntegral m)
n = 800
deltaT = t / (fromIntegral n)
singleUpdater a = traverse a id f
where
Z :. m = extent a
f _get (Z :. ix) | ix == 0 = 0.0
f _get (Z :. ix) | ix == m-1 = xMax - k
f get (Z :. ix) = a * get (Z :. ix-1) +
b * get (Z :. ix) +
c * get (Z :. ix+1)
where
a = deltaT * (sigma^2 * (fromIntegral ix)^2 - r * (fromIntegral ix)) / 2
b = 1 - deltaT * (r + sigma^2 * (fromIntegral ix)^2)
c = deltaT * (sigma^2 * (fromIntegral ix)^2 + r * (fromIntegral ix)) / 2
priceAtT :: Array U DIM1 Double
priceAtT = fromListUnboxed (Z :. m+1) [max 0 (deltaX * (fromIntegral j) - k) | j <- [0..m]]
testSingle :: IO (Array U DIM1 Double)
testSingle = computeP $ singleUpdater priceAtT
Ale teraz Załóżmy, że chcę wycenić opcje równolegle (powiedzmy, aby zrobić spot Drabinka) wtedy mogę to zrobić:
multiUpdater a = fromFunction (extent a) f
where
f :: DIM2 -> Double
f (Z :. ix :. jx) = (singleUpdater x)!(Z :. ix)
where
x :: Array D DIM1 Double
x = slice a (Any :. jx)
priceAtTMulti :: Array U DIM2 Double
priceAtTMulti = fromListUnboxed (Z :. m+1 :. p+1)
[max 0 (deltaX * (fromIntegral j) - k) | j <- [0..m], _l <- [0..p]]
testMulti :: IO (Array U DIM2 Double)
testMulti = computeP $ multiUpdater priceAtTMulti
Pytania:
- czy istnieje bardziej idiomatyczny sposób na zrobienie tego w repa?
- czy powyższa metoda rzeczywiście będzie wyceniona równolegle?
- Jak mogę stwierdzić, czy mój kod naprawdę generuje coś to będzie stracony równolegle?
Próbowałem tego przez 3 ale niestety napotkałem błąd w ghc:
bash-3.2$ ghc -fext-core --make Test.hs
[1 of 1] Compiling Main ( Test.hs, Test.o )
ghc: panic! (the 'impossible' happened)
(GHC version 7.4.1 for x86_64-apple-darwin):
MkExternalCore died: make_lit
1 answers
Twój błąd nie jest związany z Twoim kodem -- to twoje użycie -fext-core do drukowania wyjścia kompilacji w zewnętrznym formacie rdzenia. Po prostu nie rób tego (aby zobaczyć rdzeń, używam ghc-core ).
Kompiluj z -O2 i -threaded:
$ ghc -O2 -rtsopts --make A.hs -threaded
[1 of 1] Compiling Main ( A.hs, A.o )
Linking A ...
Następnie uruchom z +RTS -N4, na przykład, aby użyć 4 wątków:
$ time ./A +RTS -N4
[0.0,0.0,8.4375e-3,8.4375e-3,50.009375,50.009375,100.0,100.0]
./A 0.00s user 0.00s system 85% cpu 0.008 total
Więc kończy się zbyt szybko, aby zobaczyć wynik. Zwiększę twoje parametry m i {[15] } do 1k i 3k
$ time ./A +RTS -N2
./A +RTS -N2 3.03s user 1.33s system 159% cpu 2.735 total
Więc mieliśmy 3 wątki działające równolegle (2 przypuszczalnie dla algo, jeden dla menedżera IO).
Można skrócić czas pracy przez dostosowanie ustawień GC. Np. za pomocą -A możemy zmniejszyć narzut GC i uzyskać rzeczywistą równoległość przyspieszenie.
$ time ./A +RTS -N1 -A100M
./A +RTS -N1 -A100M 1.99s user 0.29s system 99% cpu 2.287 total
$ time ./A +RTS -N2 -A100M
./A +RTS -N2 -A100M 2.30s user 0.86s system 147% cpu 2.145 total
Możesz czasami poprawić wydajność numeryczną używając backendu LLVM. Wydaje się, że tak jest również w tym przypadku: {]}
$ ghc -O2 -rtsopts --make A.hs -threaded -fforce-recomp -fllvm
[1 of 1] Compiling Main ( A.hs, A.o )
Linking A ...
$ time ./A +RTS -N2 -A100M
./A +RTS -N2 -A100M 2.09s user 0.95s system 147% cpu 2.065 total
Nic spektakularnego, ale poprawiasz czas pracy nad wersją jednowątkową, a ja w żaden sposób nie zmodyfikowałem twojego oryginalnego kodu. Aby naprawdę poprawić rzeczy, musisz profilować i optymalizować.
Wracając do FLAG-A, możemy jeszcze bardziej obniżyć czas za pomocą dokręcania związanego na początkowym wątku obszar przydziału.
$ ghc -Odph -rtsopts --make A.hs -threaded -fforce-recomp -fllvm
$ time ./A +RTS -N2 -A60M -s
./A +RTS -N2 -A60M 1.99s user 0.73s system 144% cpu 1.880 total
Więc zmniejszyliśmy go do 1.8 s z 2.7 (poprawa o 30%), używając równoległego środowiska wykonawczego, backendu LLVM i uważając na flagi GC. Można spojrzeć na powierzchnię flagi GC, aby znaleźć optymalne:
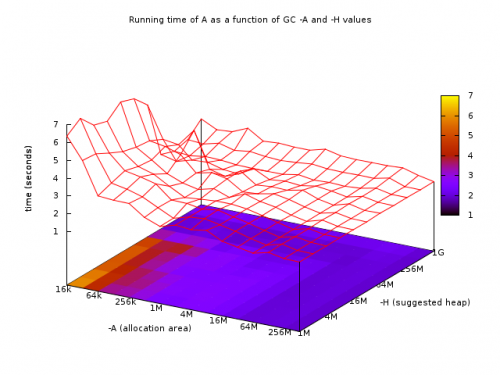
Z korytem wokół -A64 -N2 jest idealny dla wielkości zbioru danych.
Rozważyłbym również użycie ręcznej wspólnej eliminacji subekspresji w twoim wewnętrznym jądrze, aby uniknąć przekomputowywania rzeczy nadmiernie.
Aby zobaczyć zachowanie programu w trybie runtime, skompiluj threadscope (z Hackage) i uruchom w następujący sposób:]}$ ghc -O2 -fllvm -rtsopts -threaded -eventlog --make A.hs
$ ./A +RTS -ls -N2 -A60M
I dostajesz ślad zdarzeń dla swoich dwóch rdzeni w ten sposób:
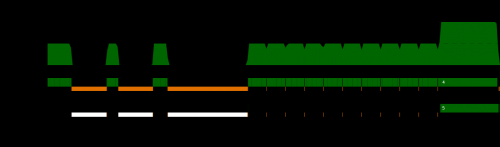
Więc podczas gdy Twój rzeczywisty algorytm może być ładnie równoległy, wszystkie otaczające ustawienia testu w zasadzie bagatelizują wynik. Jeśli serializujemy Twój zbiór danych , a następnie załadujemy go z powrotem z dysku, możemy uzyskać lepsze zachowanie:
$ time ./A +RTS -N2 -A60M
./A +RTS -N2 -A60M 1.76s user 0.25s system 186% cpu 1.073 total
A teraz Twój profil wygląda zdrowiej:
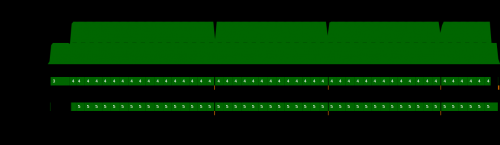
W końcu widzimy, że dostajesz dobrą paralelizm:
Z 1 rdzeniem, 1.855 s
$ time ./A +RTS -N1 -A25M
./A +RTS -N1 -A25M 1.75s user 0.11s system 100% cpu 1.855 total
I z 2 rdzeniami, 1.014 s
$ time ./A +RTS -N2 -A25M
./A +RTS -N2 -A25M 1.78s user 0.13s system 188% cpu 1.014 total
Teraz konkretnie odpowiedz na twoje pytania:
- czy istnieje bardziej idiomatyczny sposób na zrobienie tego w repa?
Ogólnie rzecz biorąc, kod repa powinien składać się z równoległych przejść, konsumentów i produkcji oraz wbudowanych funkcji jądra. Tak długo, jak to robisz, to kod jest prawdopodobnie idiomatyczne. Jeśli masz wątpliwości, spójrz na tutorial. Ogólnie oznaczałbym twoje jądra pracownika (jak f) jako inlined.
- czy powyższa metoda rzeczywiście Cena równolegle?
Kod będzie wykonywany równolegle, jeśli użyjesz kombinatorów równoległych, takich jak computeP lub różnych map i fałd. Więc tak, powinno i działa równolegle.
- jak Mogę określić, czy moje kod naprawdę generuje coś, co zostanie wykonane w równolegle?
Ogólnie, będziesz wiedział a priori ponieważ używasz operacji równoległych. W razie wątpliwości Uruchom kod i obserwuj przyspieszenie. Następnie może być konieczne zoptymalizowanie kodu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-12-29 18:25:12