W jaki sposób rekordy procesów Hadoop są dzielone między granice bloków?
Zgodnie z Hadoop - The Definitive Guide
Logiczne rekordy definiowane przez FileInputFormats zwykle nie pasują do bloków HDFS. Na przykład, rekordy logiczne TextInputFormat są liniami, które częściej przekraczają granice HDFS. Nie ma to wpływu na funkcjonowanie programu-linie nie są pomijane lub łamane, na przykład-ale warto o tym wiedzieć, ponieważ oznacza to, że dane-mapy lokalne (czyli mapy, które są uruchomione na tym samym hoście, co ich dane wejściowe) będą wykonaj zdalne odczyty. Niewielkie koszty ogólne, które to powoduje, nie są zwykle znaczące.
Załóżmy, że linia rekordu jest podzielona na dwa bloki (b1 i b2). Maper przetwarzający pierwszy blok (b1) zauważy, że ostatni wiersz nie ma separatora EOL i pobierze pozostałą linię z następnego bloku danych (b2).
W Jaki Sposób maper przetwarzający drugi blok (b2) określa, że pierwszy rekord jest niekompletny i powinien przetwarzać od drugiego rekord w bloku (b2)?
6 answers
Ciekawe pytanie, spędziłem trochę czasu patrząc na kod dla szczegółów i oto moje przemyślenia. Podziały są obsługiwane przez klienta przez InputFormat.getSplits, więc spojrzenie na FileInputFormat daje następujące informacje:
- dla każdego pliku wejściowego, uzyskaj długość pliku, rozmiar bloku i Oblicz rozmiar podzielenia jako
max(minSize, min(maxSize, blockSize)), GdziemaxSizeodpowiadamapred.max.split.size, aminSizetomapred.min.split.size. -
Podziel plik na różne
FileSplitna podstawie wielkości podzielonej obliczonej powyżej. Co jest ważne oto każdyFileSplitjest inicjowany parametremstartodpowiadającym przesunięciu w pliku wejściowym. W tym momencie nie ma jeszcze obsługi linii. Odpowiednia część kodu wygląda tak:while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(new FileSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts())); bytesRemaining -= splitSize; }
Następnie, jeśli spojrzysz na LineRecordReader, który jest zdefiniowany przez TextInputFormat, to tam obsługiwane są linie:
- podczas inicjalizacji
LineRecordReaderpróbuje utworzyć instancjęLineReader, która jest abstrakcją, aby móc czytać wiersze overFSDataInputStream. Istnieją 2 przypadki: - jeśli jest zdefiniowany
CompressionCodec, to ten kodek jest odpowiedzialny za obsługę granic. Prawdopodobnie nie ma związku z twoim pytaniem. -
Jeśli jednak nie ma kodeka, to jest to miejsce, gdzie rzeczy są interesujące: jeśli
starttwojegoInputSplitjest inny niż 0, to backtrack 1 znak, a następnie pominąć pierwszą linię napotkasz identyfikowane przez \N lub \R\n (Windows) ! Backtrack jest ważny, ponieważ w przypadku, gdy granice linii są tak samo jak dzielenie granic, zapewnia to, że nie pominiesz poprawnej linii. Oto odpowiedni kod:if (codec != null) { in = new LineReader(codec.createInputStream(fileIn), job); end = Long.MAX_VALUE; } else { if (start != 0) { skipFirstLine = true; --start; fileIn.seek(start); } in = new LineReader(fileIn, job); } if (skipFirstLine) { // skip first line and re-establish "start". start += in.readLine(new Text(), 0, (int)Math.min((long)Integer.MAX_VALUE, end - start)); } this.pos = start;
Tak więc, ponieważ podziały są obliczane w kliencie, maperzy nie muszą uruchamiać się w kolejności, każdy maper już wie, czy musi odrzucić pierwszą linię, czy nie.
Więc zasadniczo jeśli masz 2 linie po 100MB w tym samym pliku, a dla uproszczenia powiedzmy, że rozmiar podziału wynosi 64Mb. Wtedy po obliczeniu podziałów wejściowych będziemy mieli następujące scenariusz:
- Split 1 zawierający ścieżkę i hosty do tego bloku. Zainicjowany na początku 200-200=0MB, długość 64Mb.
- Split 2 zainicjowany na początku 200-200 + 64=64MB, długość 64Mb.
- Split 3 zainicjowany na początku 200-200+128=128MB, długość 64Mb.
- Split 4 zainicjowany na początku 200-200+192=192mb, długość 8Mb.
- Mapper a przetworzy split 1, start jest 0 więc nie pomijaj pierwszej linii i przeczytaj pełną linię, która wykracza poza limit 64Mb, więc potrzebuje zdalny odczyt.
- Mapper B przetworzy split 2, start jest != 0 więc pomiń pierwszą linię po 64MB-1byte, co odpowiada końcowi linii 1 na 100MB, która jest jeszcze w Splicie 2, mamy 28MB linii w Splicie 2, więc zdalnie odczytaj Pozostałe 72Mb.
- Mapper C przetworzy split 3, start jest != 0 więc pomiń pierwszą linię po 128Mb-1byte, co odpowiada końcowi linii 2 na 200Mb, który jest końcem pliku, więc nic nie rób.
- Mapper D jest taki sam jak mapper C tyle, że szuka nowej linii po 192Mb-1byte.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-01-26 22:19:16
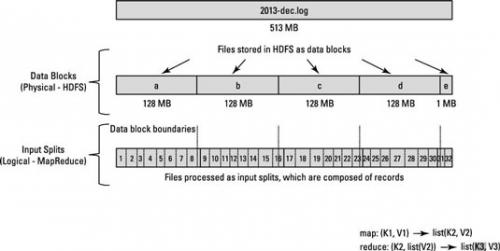
Algorytm Map Reduece nie działa na fizycznych blokach pliku. Działa na logicznych podziałach wejściowych. Podział danych wejściowych zależy od tego, gdzie zapisano rekord. Rekord może obejmować dwóch maperów.
Sposób, w jaki HDFS został skonfigurowany, rozkłada bardzo duże pliki na duże bloki (na przykład mierzące 128 MB) i przechowuje trzy kopie tych bloków na różnych węzłach w klastrze.
HDFS nie ma świadomości zawartości tych plików. Płyta mogła być rozpoczęte w Blok-a ale koniec tego zapisu może być obecny w Blok-b.
Aby rozwiązać ten problem, Hadoop używa logicznej reprezentacji danych przechowywanych w blokach plików, znanych jako podziały wejściowe. Kiedy klient zadania MapReduce oblicza Podział wejścia, określa, gdzie zaczyna się pierwszy cały rekord w bloku i gdzie kończy się ostatni rekord w bloku.
kluczowy punkt :
w przypadkach, gdy ostatni rekord w bloku jest niekompletny, podział danych wejściowych zawiera informacje o lokalizacji dla następnego bloku i przesunięcie bajtów danych potrzebnych do ukończenia rekordu.
Spójrz na poniższy diagram.
Spójrz na ten artykuł i powiązane pytanie SE : o podziale plików Hadoop / HDFS
Więcej szczegółów można przeczytać w dokumentacja
Nie jest to jednak możliwe, ponieważ nie jest to możliwe.]}- zweryfikuj dane wejściowe zadania.
- dzielenie plików wejściowych na logiczne łącza wejściowe, z których każdy jest następnie przypisywany do pojedynczego Mapera.
- każdy InputSplit jest następnie przypisany do indywidualnego Mapera do przetwarzania. Split może być krotką .
InputSplit[] getSplits(JobConf job,int numSplits) jest API do dbania o te rzeczy.
FileInputFormat , który rozszerza InputFormat zaimplementowaną metodę getSplits (). Zapraszamy do zapoznania się z wewnętrzną stroną tej metody na stronie grepcode
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:34:48
Widzę to w następujący sposób: InputFormat jest odpowiedzialny za dzielenie danych na podziały logiczne z uwzględnieniem charakteru danych.
nic nie stoi na przeszkodzie, aby to zrobić, chociaż może to dodać znaczne opóźnienie do zadania - Cała logika i odczyt wokół żądanych granic wielkości podzielonych nastąpi w jobtrackerze.
Najprostszym formatem zapisu jest TextInputFormat. Działa to w następujący sposób ( o ile zrozumiałem z kodu) - format wejściowy tworzy podziały według rozmiaru, niezależnie od linie, ale LineRecordReader zawsze:
a) pomija pierwszą linię podziału (lub jego część), jeśli nie jest to pierwszy split
b) odczyt jednej linii po granicy podziału na końcu (jeśli dane są dostępne, więc nie jest to ostatni split).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-01-12 09:49:55
Z tego co zrozumiałem, kiedy FileSplit jest inicjalizowana dla pierwszego bloku, wywoływany jest konstruktor domyślny. Dlatego wartości dla początku i długości są początkowo zerowe. Pod koniec przetwarzania bloku pięści, jeśli ostatnia linia jest niekompletna, to wartość długości będzie większa niż długość podziału i będzie również odczytywać pierwszą linię następnego bloku. W związku z tym wartość start dla pierwszego bloku będzie większa od zera i pod tym warunkiem LineRecordReader pominie linię pięści drugiego bloku. (Zobacz Źródło )
W przypadku, gdy ostatni wiersz pierwszego bloku jest kompletny, wtedy wartość długości będzie równa długości pierwszego bloku, a wartość początku dla drugiego bloku będzie równa zero. W takim przypadku LineRecordReader nie pominie pierwszego wiersza i nie odczyta drugiego bloku z początku.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-01-23 13:29:48
Z kodu źródłowego linerecordreader hadoop.java konstruktor: znalazłem kilka komentarzy:
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
Z tego uważam, że hadoop będzie czytać jeden dodatkowy wiersz dla każdego podziału(na końcu bieżącego podziału, Czytaj następny wiersz w następnym podziale), a jeśli nie pierwszy split, pierwsza linia zostanie wyrzucona. aby żaden rekord linii nie został utracony i niekompletny
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-01-27 16:18:47
Maperzy nie muszą się komunikować. Bloki plików są w formacie HDFS i czy bieżący maper (RecordReader) może odczytać blok, który ma pozostałą część linii. Dzieje się to za kulisami.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-04-06 00:01:42