Jaka jest różnica między strukturami danych Trie i radix trie?
Czy struktury danych Trie i radix trie to to samo?
Jeśli są takie same, to jakie jest znaczenie radix trie (AKA Patricia trie)?
3 answers
Drzewo radix jest skompresowaną wersją trie. W Trie na każdej krawędzi piszesz pojedynczą literę, natomiast w drzewie (lub drzewie radix) zapisujesz całe słowa.
Teraz Załóżmy, że masz słowa hello, hat i have. Aby przechowywać je w trie , wyglądałoby to następująco:
e - l - l - o
/
h - a - t
\
v - e
I potrzebujesz dziewięciu węzłów. Umieściłem litery w węzłach, ale w rzeczywistości etykietują krawędzie.
W drzewie radix będziesz miał:
*
/
(ello)
/
* - h - * -(a) - * - (t) - *
\
(ve)
\
*
I potrzebujesz tylko pięciu węzłów. Na zdjęciu powyżej węzły są gwiazdki.
Więc, ogólnie rzecz biorąc, drzewo radix zajmujemniej pamięci , ale jest trudniejsze do zaimplementowania. W przeciwnym razie przypadek użycia obu jest prawie taki sam.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-11-15 10:29:02
Krótko mówiąc, nie. Kategoria Radix Trie opisuje konkretną kategorię Trie , ale to nie znaczy, że wszystkie próby są próbami radix.Moje pytanie brzmi, czy Trie struktura danych i Radix Trie to to samo?
Jeśli są [nie] takie same, to jakie jest znaczenie Radix trie (aka Patricia Trie)?
Zakładam, że chciałeś napisać nie jesteś w twoim pytaniu, stąd moje poprawka.
Podobnie, PATRICIA oznacza określony typ Trie radix, ale nie wszystkie próby radix są próbami PATRICIA.Co to jest trie?
"Trie" opisuje strukturę drzewa danych nadającą się do użycia jako tablica asocjacyjna, gdzie gałęzie lub krawędzie odpowiadają części klucza. Definicja części jest tu dość niejasna, ponieważ różne implementacje tries używają różnych długości bitów, aby odpowiadać krawędziom. Na przykład binarny trie ma dwie krawędzie na węzeł, które odpowiadają 0 LUB 1, podczas gdy 16-drożna trie ma szesnaście krawędzi na węzeł, które odpowiadają czterem bitom (lub szesnastkowym cyfrom: 0x0 do 0XF).
Ten schemat wyodrębniony z Wikipedii wydaje się przedstawiać trójkę z (przynajmniej) wstawionymi kluczami" A", "K"," herbata"," Ted"," dziesięć "i" Hotel":
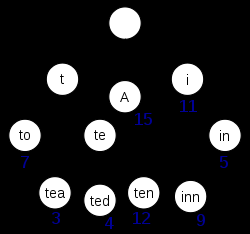
Gdyby ten trie przechowywał elementy dla kluczy "t", "te", " i " lub "in", musiałyby być dodatkowe informacje obecne w każdym węźle aby odróżnić węzły zerowe od węzłów o rzeczywistych wartościach.
Co to jest radix trie?
"Radix trie" wydaje się opisywać formę trie, która skraca wspólne przedrostki, jak opisał Ivaylo Strandjev w swojej odpowiedzi. Rozważmy 256-pasmową trójkę, która indeksuje klucze "smile"," smiled"," smiles "i" smiling", używając następujących przypisań statycznych:root['s']['m']['i']['l']['e']['\0'] = smile_item;
root['s']['m']['i']['l']['e']['d']['\0'] = smiled_item;
root['s']['m']['i']['l']['e']['s']['\0'] = smiles_item;
root['s']['m']['i']['l']['i']['n']['g']['\0'] = smiling_item;
Każdy indeks dolny uzyskuje dostęp do wewnętrznego węzła. Oznacza to, że aby odzyskać smile_item, Musisz uzyskać dostęp do siedmiu węzły. 8 węzłów odpowiada smiled_item i smiles_item, a 9 - smiling_item. Dla tych czterech elementów jest w sumie czternaście węzłów. Wszystkie mają jednak wspólne cztery pierwsze bajty (odpowiadające czterem pierwszym węzłom). Skondensowanie tych czterech bajtów w celu utworzenia root, która odpowiada ['s']['m']['i']['l'], pozwoliło zoptymalizować dostęp do czterech węzłów. Oznacza to mniej pamięci i mniej dostępu do węzłów, co jest bardzo dobrym wskaźnikiem. Optymalizację można zastosować rekurencyjnie, aby zmniejszyć potrzebę dostęp do niepotrzebnych bajtów przyrostków. W końcu dojdziesz do punktu, w którym porównujesz tylko różnice między kluczem wyszukiwania a kluczami indeksowanymi w lokalizacjach indeksowanych przez trie. To radix trie.
root = smil_dummy;
root['e'] = smile_item;
root['e']['d'] = smiled_item;
root['e']['s'] = smiles_item;
root['i'] = smiling_item;
Aby odzyskać elementy, każdy węzeł potrzebuje pozycji. Za pomocą klucza wyszukiwania "smiles" i root.position z 4, uzyskujemy dostęp do root["smiles"[4]], czyli root['e']. Przechowujemy to w zmiennej o nazwie current. current.position jest 5, co jest położeniem różnicy między "smiled" a "smiles", więc następny dostęp będzie root["smiles"[5]]. To prowadzi nas do smiles_item i końca naszego Sznurka. Nasze poszukiwania dobiegły końca, a obiekt został odzyskany, z zaledwie trzema węzłami dostępu zamiast ośmiu.
Co to jest PATRICIA trie?
Jest odmianą radix, dla której powinny istnieć tylko n węzły używane do przechowywania n elementów. W naszym crudely zademonstrowanym pseudokodie radix trie powyżej, jest w sumie pięć węzłów: root (który jest węzłem zerowym; to nie zawiera rzeczywistej wartości), root['e'], root['e']['d'], root['e']['s'] i root['i']. W Patrycji trie powinny być tylko cztery. Przyjrzyjmy się, jak te prefiksy mogą się różnić, patrząc na nie w binarnym, ponieważ PATRICIA jest algorytmem binarnym.
smile: 0111 0011 0110 1101 0110 1001 0110 1100 0110 0101 0000 0000 0000 0000
smiled: 0111 0011 0110 1101 0110 1001 0110 1100 0110 0101 0110 0100 0000 0000
smiles: 0111 0011 0110 1101 0110 1001 0110 1100 0110 0101 0111 0011 0000 0000
smiling: 0111 0011 0110 1101 0110 1001 0110 1100 0110 1001 0110 1110 0110 0111 ...
Rozważmy, że węzły są dodawane w kolejności, w jakiej zostały przedstawione powyżej. Jest korzeniem tego drzewa. Różnica, pogrubiona, aby ułatwić jej dostrzeżenie, znajduje się w ostatnim bajcie "smile", W bitu 36. Do tego momentu wszystkie nasze węzły mają ten sam prefiks . smiled_node należy do smile_node[0]. Różnica pomiędzy "smiled" i "smiles" występuje w bitu 43, gdzie "smiles" mA bit "1", więc smiled_node[1] jest smiles_node.
Zamiast używać NULL jako gałęzi i / lub dodatkowych informacji wewnętrznych do oznaczania zakończenia wyszukiwania, gałęzie łączą się z w górę gdzieś w drzewie, więc wyszukiwanie kończy się, gdy przesunięcie do testu zmniejsza się zamiast zwiększać. Oto prosty schemat takiego drzewa Patrycja jest bardziej cykliczną grafem niż drzewem, jak widać), która została zawarta w książce sedgewicka wymienionej poniżej: [43]}
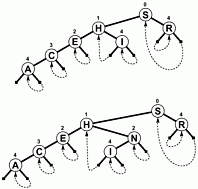
Rozgałęziając się w ten sposób, istnieje wiele korzyści: każdy węzeł zawiera wartość. To obejmuje korzeń. W rezultacie długość i złożoność kodu staje się znacznie krótsza i prawdopodobnie nieco szybsza w rzeczywistości. Co najmniej jedna gałąź i co najwyżej k gałęzie (gdzie k to liczba bitów w kluczu wyszukiwania) są śledzone w celu zlokalizowania elementu. Węzły są małe , ponieważ przechowują tylko dwie gałęzie każda, co czyni je dość odpowiednimi do optymalizacji lokalizacji cache. Te właściwości sprawiają, że Patrycja jest moim ulubionym algorytmem, więc daleko...
Zamierzam skrócić ten opis tutaj, w celu zmniejszenia nasilenia mojego zbliżającego się zapalenia stawów, ale jeśli chcesz dowiedzieć się więcej o Patricii, możesz przeczytać książki, takie jak "sztuka programowania komputerowego, tom 3" Donalda Knutha, lub którykolwiek z "algorytmów w {your-favorite-language}, Części 1-4" Sedgewick.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-07-20 11:21:43
TRIE:
Możemy mieć schemat wyszukiwania, w którym zamiast porównywać cały klucz wyszukiwania ze wszystkimi istniejącymi kluczami (takimi jak schemat hash), możemy również porównać każdy znak klucza wyszukiwania. Podążając za tym pomysłem, możemy zbudować strukturę (jak pokazano poniżej), która ma trzy istniejące klucze – " tato", "dab " i " cab".
[root]
...// | \\...
| \
c d
| \
[*] [*]
...//|\. ./|\\... Fig-I
a a
/ /
[*] [*]
...//|\.. ../|\\...
/ / \
B b d
/ / \
[] [] []
(cab) (dab) (dad)
Jest to zasadniczo drzewo M-ary z węzłem wewnętrznym reprezentowanym jako [ * ] i węzłem liściowym reprezentowanym jako []. To struktura nazywa się trie. Decyzja rozgałęzienia w każdym węźle może być zachowana w liczbie unikalnych symboli alfabetu, powiedzmy R. dla małych liter alfabetów angielskich a-z, R=26; dla rozszerzonych alfabetów ASCII, R=256 i dla cyfr binarnych / ciągów R = 2.
Zwarte TRIE:
Zazwyczaj węzeł w trie używa tablicy z size = R i w ten sposób powoduje marnowanie pamięci, gdy każdy węzeł ma mniej krawędzi. Aby obejść problem pamięci, różne przedstawiono propozycje. Na podstawie tych zmian trie są również nazwane jako "compact trie" i "compressed trie". Choć spójna nomenklatura jest rzadka, najczęściej spotykana wersja zwartej trie tworzy się przez grupowanie wszystkich krawędzi, gdy węzły mają pojedynczą krawędź. Używając tego pojęcia, powyższe (rys. I) trie z klawiszami "Tata", " dab " i " cab " może przyjąć poniższy formularz.
[root]
...// | \\...
| \
cab da
| \
[ ] [*] Fig-II
./|\\...
| \
b d
| \
[] []
Zauważ, że każdy z "c", " a " i " b " jest jedynym brzegiem dla odpowiadającego mu węzła macierzystego i dlatego są one połączone w pojedynczą krawędź "cab". Podobnie, " d " I " a "są połączone w jedną krawędź oznaczoną jako "da".
Radix Trie:
Termin radix w matematyce oznacza bazę systemu liczbowego i zasadniczo oznacza liczbę unikalnych symboli potrzebnych do reprezentowania dowolnej liczby w tym systemie. Na przykład, system dziesiętny to radix dziesięć, a system binarny to radix dwa. Używając podobnego pojęcia, gdy jesteśmy zainteresowani scharakteryzowaniem struktury danych lub algorytmu przez liczbę unikalnych symboli bazowego systemu reprezentacyjnego, oznaczamy pojęcie terminem "radix". Na przykład "radix sort" dla pewnego algorytmu sortowania. W tej samej linii logiki, wszystkie warianty trie których cech (takich jak głębia, potrzeba pamięci, wyszukiwanie miss/hit runtime, itp.) w zależności od radix podstawowych alfabetów, możemy je nazwać radix "trie ' s". Na przykład, nie-zagęszczony jako jak zagęszczony trie gdy używa się alfabetów od a do z, możemy nazwać go radixem 26 trie. Każdy trie, który używa tylko dwóch symboli (tradycyjnie "0" i "1"), można nazwać radix 2 trie. Jednak jakoś wiele Literatur ograniczyło użycie terminu "Radix Trie" tylko dla zwartych trie.
Prelude to PATRICIA Tree/Trie:
Warto zauważyć, że nawet ciągi jako klucze mogą być reprezentowane za pomocą binarnych alfabetów. Jeśli przyjmiemy kodowanie ASCII, to klucz "dad" można zapisać w postaci binarnej pisząc binarną reprezentację każdego znaku w sekwencji, powiedzmy jako "011001000110000101100100" zapisując kolejno formy binarne "d", " a " I "d".
Korzystając z tej koncepcji, a trie (z Radix dwa) mogą być utworzone. Poniżej przedstawiamy tę koncepcję używając uproszczonego założenia, że litery 'A', 'b', 'c' I' d ' pochodzą od mniejszego alfabet zamiast ASCII.
Uwaga do Fig-III: Jak wspomniano, aby ułatwić przedstawienie, Załóżmy, że alfabet zawierający tylko 4 litery {A,b,c, d} i odpowiadające im reprezentacje binarne są "00", "01", "10" i odpowiednio "11". Dzięki temu nasze klucze "dad", " dab " i " cab "stają się odpowiednio" 110011"," 110001 "i" 100001". Trie dla tego będzie jak pokazano poniżej na Rys. III (bity są odczytywane od lewej do prawej, podobnie jak łańcuchy są odczytywane od lewej do racja).
[root]
\1
\
[*]
0/ \1
/ \
[*] [*]
0/ /
/ /0
[*] [*]
0/ /
/ /0
[*] [*]
0/ 0/ \1 Fig-III
/ / \
[*] [*] [*]
\1 \1 \1
\ \ \
[] [] []
(cab) (dab) (dad)
Patrycja Trie / drzewo:
Jeśli skompaktujemy powyższe binarne trie (Fig-III) używając zagęszczania pojedynczej krawędzi, miałby znacznie mniej węzłów niż pokazano powyżej, a jednak węzły nadal byłyby większe niż 3, Liczba klawiszy, które zawiera. Donald R. Morrison znaleziono (w 1968) nowatorski sposób wykorzystania binarnych trie aby przedstawić N kluczy za pomocą tylko N węzłów i nazwał tę strukturę danych Patrycja. Jego struktura trie zasadniczo pozbyła się pojedynczych krawędzi (jednokierunkowe rozgałęzienia); i w ten sposób pozbył się również pojęcia dwóch rodzajów węzłów – węzłów wewnętrznych (które nie przedstawiają żadnego klucza) i węzłów liściowych (które przedstawiają klucze). W przeciwieństwie do logiki zagęszczania wyjaśnionej powyżej, jego trie używa innej koncepcji, w której każdy węzeł zawiera wskazanie, ile bitów klucza należy pominąć w celu podjęcia decyzji o rozgałęzieniu. Jeszcze inną cechą jego Patrycji trie jest to, że nie przechowuje kluczy – co oznacza, że taka struktura danych nie będzie odpowiednia do odpowiadania na pytania typu Lista wszystkich kluczy, które pasują do danego prefiksu , ale jest dobra do znalezienia czy klucz istnieje lub nie w trie. Niemniej jednak, termin Patricia Tree lub Patricia Trie był od tego czasu używany w wielu różnych, ale podobnych zmysłach, takich jak, aby wskazać kompaktowe trie [NIST], lub aby wskazać trie radix z radix dwa [jak wskazano w subtelny sposób w WIKI] i tak dalej.
Trie, które może nie być Radix Trie:
Ternary Search Trie (aka Ternary search Tree) często skracane jako TST jest strukturą danych (zaproponowaną przez J. Bentleya i R. Sedgewicka), która wygląda bardzo podobnie do trie z trójstronnym rozgałęzieniem. Dla takiego drzewa każdy węzeł ma charakterystyczny alfabet "x", tak że decyzja o rozgałęzieniu zależy od tego, czy znak klucza jest mniejszy, równy lub większy od "x". Ze względu na to stałe Funkcja 3-way rozgałęziania, zapewnia wydajną pamięć alternatywę dla trie, zwłaszcza gdy R (radix) jest bardzo duży, jak dla alfabetów Unicode. Co ciekawe, TST, w przeciwieństwie do (R-way) trie, na przykład, search miss for TST to ln(N) w przeciwieństwie do logR(N) Dla r-way Trie. Wymagania pamięci TST, w przeciwieństwie do R-way trie jestnie również funkcją R. Więc powinniśmy bądź ostrożny, aby nazwać TST radix-trie. Osobiście uważam, że nie powinniśmy nazywać tego radix-trie, ponieważ Żadna (O ile mi wiadomo) jego charakterystyka nie ma wpływu na radix,R, jego podstawowych alfabetów.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-11-13 09:03:41