Różnica między funkcjami MPI Allgather i MPI Alltoall?
Jaka jest główna różnica między funkcjami MPI_Allgather i mpi_alltoall w MPI?
Chodzi mi o to czy ktos moze mi podac przyklady gdzie mpi_allgather bedzie pomocny a MPI_Alltoall nie? i vice versa.
Nie jestem w stanie zrozumieć głównej różnicy? Wygląda na to, że w obu przypadkach wszystkie procesy wysyłają elementy send_cnt do każdego innego procesu uczestniczącego w komunikatorze i otrzymują je?
Thank You
3 answers
Obraz mówi więcej niż tysiąc słów, więc oto kilka obrazów sztuki ASCII:
rank send buf recv buf
---- -------- --------
0 a,b,c MPI_Allgather a,b,c,A,B,C,#,@,%
1 A,B,C ----------------> a,b,c,A,B,C,#,@,%
2 #,@,% a,b,c,A,B,C,#,@,%
Jest to zwykły MPI_Gather, tylko w tym przypadku wszystkie procesy otrzymują kawałki danych, tzn. operacja jest bez roota.
rank send buf recv buf
---- -------- --------
0 a,b,c MPI_Alltoall a,A,#
1 A,B,C ----------------> b,B,@
2 #,@,% c,C,%
(a more elaborate case with two elements per process)
rank send buf recv buf
---- -------- --------
0 a,b,c,d,e,f MPI_Alltoall a,b,A,B,#,@
1 A,B,C,D,E,F ----------------> c,d,C,D,%,$
2 #,@,%,$,&,* e,f,E,F,&,*
(wygląda lepiej, jeśli każdy element jest kolorowany przez rangę, która go wysyła, ale...)
MPI_Alltoall działa jak połączone MPI_Scatter i MPI_Gather - bufor wysyłania w każdym procesie jest dzielony jak w MPI_Scatter, a następnie każda kolumna fragmentów jest gromadzona przez odpowiedni proces, którego ranga odpowiada numerowi kolumny fragmentu. MPI_Alltoall może być również postrzegana jako globalna operacja transpozycji, działająca na fragmentach danych.
Czy jest przypadek, gdy obie operacje są wymienne? Aby poprawnie odpowiedzieć na to pytanie, należy po prostu przeanalizować rozmiary danych w buforze wysyłania i danych w buforze odbioru:
operation send buf size recv buf size
--------- ------------- -------------
MPI_Allgather sendcnt n_procs * sendcnt
MPI_Alltoall n_procs * sendcnt n_procs * sendcnt
Rozmiar bufora odbierającego jest w rzeczywistości n_procs * recvcnt, ale MPI nakazuje, aby liczba wysłanych podstawowych elementów jest równa liczbie odebranych podstawowych elementów, stąd Jeśli ten sam typ danych MPI jest używany zarówno w części wysyłania, jak i odbierania MPI_All..., to recvcnt musi być równy sendcnt.
Jest od razu oczywiste, że dla tej samej wielkości odebranych danych, ilość danych wysyłanych przez każdy proces jest inna. Aby obie operacje były równe, jednym koniecznym warunkiem jest to, że rozmiary wysyłanych buforów w obu przypadkach są równe, tzn. n_procs * sendcnt == sendcnt, co jest możliwe tylko wtedy, gdy n_procs == 1, tzn. gdy istnieje tylko jeden proces, lub jeśli sendcnt == 0, tzn. żadne dane nie są wysyłane w ogóle. W związku z tym nie ma praktycznie realnego przypadku, w którym obie operacje są naprawdę wymienne. Ale można symulować MPI_Allgather z MPI_Alltoall powtarzając n_procs razy te same dane w buforze wysyłania (jak już zauważył Tyler Gill). Oto działanie MPI_Allgather z jednoelementowymi buforami wysyłania:
rank send buf recv buf
---- -------- --------
0 a MPI_Allgather a,A,#
1 A ----------------> a,A,#
2 # a,A,#
I tu to samo zaimplementowane z MPI_Alltoall:
rank send buf recv buf
---- -------- --------
0 a,a,a MPI_Alltoall a,A,#
1 A,A,A ----------------> a,A,#
2 #,#,# a,A,#
Odwrotność nie jest możliwa - nie można symulować działania MPI_Alltoall z MPI_Allgather w ogólnym przypadku.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-02-24 15:40:02
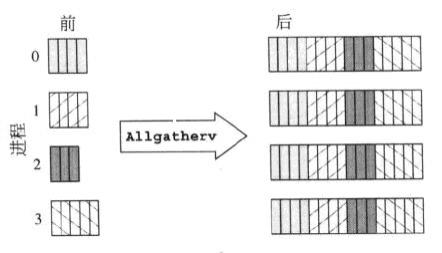
Te dwa screeny mają szybkie wyjaśnienie:
MPI_Allgatherv
MPI_Alltoallv
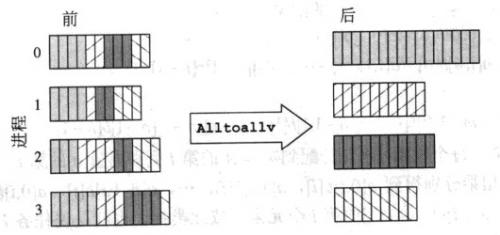
Chociaż jest to porównanie między MPI_Allgatherv i MPI_Alltoallv, ale wyjaśnia również, czym mpi_allgather różni się od MPI_Alltoall.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-12-06 02:49:02
Chociaż te dwie metody są rzeczywiście bardzo podobne, wydaje się, że istnieje jedna zasadnicza różnica między nimi.
Mpi_allgather kończy się tym, że każdy proces ma dokładnie te same dane w swoim buforze odbiorczym, a każdy proces wnosi jedną wartość do ogólnej tablicy. Na przykład, jeśli każdy z zestawów procesów potrzebował udostępnić jakąś pojedynczą wartość o swoim stanie wszystkim innym, każdy z nich dostarczyłby swoją pojedynczą wartość. Wartości te będą następnie wysyłane do wszystkich, więc każdy miał kopię tej samej struktury.
MPI_Alltoall nie wysyła do siebie tych samych wartości. Zamiast dostarczania jednej wartości, która powinna być współdzielona z innym procesem, każdy proces określa jedną wartość, która ma zostać przekazana innemu procesowi. Innymi słowy, w przypadku n procesów każdy musi określić n wartości, które mają być współdzielone. Następnie, dla każdego procesora J, jego wartość k 'TH zostanie wysłana do indeksu J' TH procesu k w buforze odbioru. Jest to przydatne, jeśli każdy proces ma jeden, unikalny wiadomość dla siebie procesu.
Na koniec, wyniki uruchomienia allgather i alltoall byłyby takie same w przypadku, gdy każdy proces wypełnił swój bufor wysyłania tą samą wartością. Jedyną różnicą byłoby to, że allgather prawdopodobnie byłby znacznie bardziej wydajny.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-02-24 07:34:47