HashSet a wydajność listy
Jest oczywiste, że wydajność wyszukiwania klasy generycznej HashSet<T> jest wyższa niż klasy generycznej List<T>. Wystarczy porównać klucz hashowy z podejściem liniowym klasy List<T>.
Jednak samo obliczanie klucza hashowego może zająć kilka cykli procesora, więc dla niewielkiej ilości elementów wyszukiwanie liniowe może być prawdziwą alternatywą dla HashSet<T>.
Aby uprościć scenariusz (i być uczciwym) Załóżmy, że klasa List<T> używa metoda elementu Equals() do identyfikacji elementu.
12 answers
Wiele osób mówi, że gdy osiągniesz rozmiar, w którym prędkość jest rzeczywiście problemem, który HashSet<T> zawsze będzie pokonany List<T>, ale to zależy od tego, co robisz.
Załóżmy, że masz List<T>, który będzie miał tylko średnio 5 przedmiotów w nim. Przez dużą liczbę cykli, jeśli pojedynczy element jest dodawany lub usuwany w każdym cyklu, może być lepiej używać List<T>.
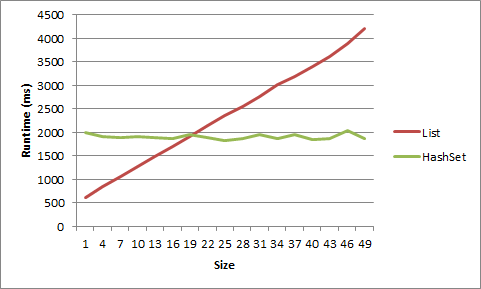
List<T>. Dla listy krótkich łańcuchów, przewaga zniknęła po rozmiarze 5, dla obiektów po rozmiarze 20.
1 item LIST strs time: 617ms
1 item HASHSET strs time: 1332ms
2 item LIST strs time: 781ms
2 item HASHSET strs time: 1354ms
3 item LIST strs time: 950ms
3 item HASHSET strs time: 1405ms
4 item LIST strs time: 1126ms
4 item HASHSET strs time: 1441ms
5 item LIST strs time: 1370ms
5 item HASHSET strs time: 1452ms
6 item LIST strs time: 1481ms
6 item HASHSET strs time: 1418ms
7 item LIST strs time: 1581ms
7 item HASHSET strs time: 1464ms
8 item LIST strs time: 1726ms
8 item HASHSET strs time: 1398ms
9 item LIST strs time: 1901ms
9 item HASHSET strs time: 1433ms
1 item LIST objs time: 614ms
1 item HASHSET objs time: 1993ms
4 item LIST objs time: 837ms
4 item HASHSET objs time: 1914ms
7 item LIST objs time: 1070ms
7 item HASHSET objs time: 1900ms
10 item LIST objs time: 1267ms
10 item HASHSET objs time: 1904ms
13 item LIST objs time: 1494ms
13 item HASHSET objs time: 1893ms
16 item LIST objs time: 1695ms
16 item HASHSET objs time: 1879ms
19 item LIST objs time: 1902ms
19 item HASHSET objs time: 1950ms
22 item LIST objs time: 2136ms
22 item HASHSET objs time: 1893ms
25 item LIST objs time: 2357ms
25 item HASHSET objs time: 1826ms
28 item LIST objs time: 2555ms
28 item HASHSET objs time: 1865ms
31 item LIST objs time: 2755ms
31 item HASHSET objs time: 1963ms
34 item LIST objs time: 3025ms
34 item HASHSET objs time: 1874ms
37 item LIST objs time: 3195ms
37 item HASHSET objs time: 1958ms
40 item LIST objs time: 3401ms
40 item HASHSET objs time: 1855ms
43 item LIST objs time: 3618ms
43 item HASHSET objs time: 1869ms
46 item LIST objs time: 3883ms
46 item HASHSET objs time: 2046ms
49 item LIST objs time: 4218ms
49 item HASHSET objs time: 1873ms
Oto Dane wyświetlane jako wykres:
Oto kod:
static void Main(string[] args)
{
int times = 10000000;
for (int listSize = 1; listSize < 10; listSize++)
{
List<string> list = new List<string>();
HashSet<string> hashset = new HashSet<string>();
for (int i = 0; i < listSize; i++)
{
list.Add("string" + i.ToString());
hashset.Add("string" + i.ToString());
}
Stopwatch timer = new Stopwatch();
timer.Start();
for (int i = 0; i < times; i++)
{
list.Remove("string0");
list.Add("string0");
}
timer.Stop();
Console.WriteLine(listSize.ToString() + " item LIST strs time: " + timer.ElapsedMilliseconds.ToString() + "ms");
timer = new Stopwatch();
timer.Start();
for (int i = 0; i < times; i++)
{
hashset.Remove("string0");
hashset.Add("string0");
}
timer.Stop();
Console.WriteLine(listSize.ToString() + " item HASHSET strs time: " + timer.ElapsedMilliseconds.ToString() + "ms");
Console.WriteLine();
}
for (int listSize = 1; listSize < 50; listSize+=3)
{
List<object> list = new List<object>();
HashSet<object> hashset = new HashSet<object>();
for (int i = 0; i < listSize; i++)
{
list.Add(new object());
hashset.Add(new object());
}
object objToAddRem = list[0];
Stopwatch timer = new Stopwatch();
timer.Start();
for (int i = 0; i < times; i++)
{
list.Remove(objToAddRem);
list.Add(objToAddRem);
}
timer.Stop();
Console.WriteLine(listSize.ToString() + " item LIST objs time: " + timer.ElapsedMilliseconds.ToString() + "ms");
timer = new Stopwatch();
timer.Start();
for (int i = 0; i < times; i++)
{
hashset.Remove(objToAddRem);
hashset.Add(objToAddRem);
}
timer.Stop();
Console.WriteLine(listSize.ToString() + " item HASHSET objs time: " + timer.ElapsedMilliseconds.ToString() + "ms");
Console.WriteLine();
}
Console.ReadLine();
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-11-04 22:06:30
Źle na to patrzysz. Tak, liniowe wyszukiwanie listy pobije HashSet dla niewielkiej liczby elementów. Ale różnica wydajności zwykle nie ma znaczenia dla kolekcji tak małych. Generalnie chodzi o duże zbiory, o które musisz się martwić, i tam myślisz w kategoriach Big-O. Jeśli jednak zmierzyłeś prawdziwe wąskie gardło wydajności HashSet, możesz spróbować utworzyć listę hybrydową / HashSet, ale zrobisz to, przeprowadzając wiele empirycznych wydajności testy - nie zadawanie pytań na tak.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-07-06 10:41:22
Czy używać HashSet czy List sprowadza się do Jak należy uzyskać dostęp do swojej kolekcji. Jeśli chcesz zagwarantować kolejność pozycji, Użyj listy. Jeśli nie, użyj HashSet. Niech Microsoft martwi się implementacją algorytmów i obiektów haszujących.
HashSet uzyska dostęp do elementów bez konieczności wyliczania kolekcji (złożoność O (1) lub jej pobliżu), a ponieważ lista gwarantuje kolejność, w przeciwieństwie do HashSet, niektóre elementy będą musiały być wyliczane (złożoność O (n)).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-09-29 21:44:51
Nie ma sensu porównywać dwóch struktur dlaperformance , które zachowują się inaczej. Użyj struktury, która przekazuje intencję. Nawet jeśli powiesz, że twój List<T> nie miałby duplikatów, a kolejność iteracji nie ma znaczenia, czyniąc go porównywalnym do HashSet<T>, nadal jest kiepskim wyborem do użycia List<T>, ponieważ jest stosunkowo mniej odporny na błędy.
To powiedziawszy, sprawdzę niektóre inne aspekty wydajności,
+------------+--------+-------------+-----------+----------+----------+-----------+
| Collection | Random | Containment | Insertion | Addition | Removal | Memory |
| | access | | | | | |
+------------+--------+-------------+-----------+----------+----------+-----------+
| List<T> | O(1) | O(n) | O(n) | O(1)* | O(n) | Lesser |
| HashSet<T> | O(n) | O(1) | n/a | O(1) | O(1) | Greater** |
+------------+--------+-------------+-----------+----------+----------+-----------+
* Even though addition is O(1) in both cases, it will be relatively slower in HashSet<T> since it involves cost of precomputing hash code before storing it.
** The superior scalability of HashSet<T> has a memory cost. Every entry is stored as a new object along with its hash code. This article might give you an idea.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-10-07 22:30:34
Pomyślałem, że przedstawię kilka benchmarków dla różnych scenariuszy, aby zilustrować poprzednie odpowiedzi:
- kilka (12 - 20) małych łańcuchów (długość od 5 do 10 znaków)
- Wiele (~10k) małych strun
- kilka długich łańcuchów (długość od 200 do 1000 znaków)
- Wiele (~5K) długich strun
- kilka liczb całkowitych
- Wiele (~10k) liczb całkowitych
I dla każdego scenariusza, szukając wartości, które pojawiają się:
- W początek listy ("start", indeks 0)
- w pobliżu początku listy ("wczesny", indeks 1)
- w środku listy ("middle", index count/2)
- pod koniec listy ("późno", liczba indeksów-2)
- na końcu listy ("koniec", liczba indeksów-1)
Przed każdym scenariuszem generowałem losowe listy losowych łańcuchów, a następnie przekazywałem każdą listę do hashset. Każdy scenariusz przebiegał 10 000 razy, zasadniczo:
(badanie pseudocode)
stopwatch.start
for X times
exists = list.Contains(lookup);
stopwatch.stop
stopwatch.start
for X times
exists = hashset.Contains(lookup);
stopwatch.stop
Przykładowe Wyjście
testowany na Windows 7, 12GB Ram, 64 bit, Xeon 2.8 GHz
---------- Testing few small strings ------------
Sample items: (16 total)
vgnwaloqf diwfpxbv tdcdc grfch icsjwk
...
Benchmarks:
1: hashset: late -- 100.00 % -- [Elapsed: 0.0018398 sec]
2: hashset: middle -- 104.19 % -- [Elapsed: 0.0019169 sec]
3: hashset: end -- 108.21 % -- [Elapsed: 0.0019908 sec]
4: list: early -- 144.62 % -- [Elapsed: 0.0026607 sec]
5: hashset: start -- 174.32 % -- [Elapsed: 0.0032071 sec]
6: list: middle -- 187.72 % -- [Elapsed: 0.0034536 sec]
7: list: late -- 192.66 % -- [Elapsed: 0.0035446 sec]
8: list: end -- 215.42 % -- [Elapsed: 0.0039633 sec]
9: hashset: early -- 217.95 % -- [Elapsed: 0.0040098 sec]
10: list: start -- 576.55 % -- [Elapsed: 0.0106073 sec]
---------- Testing many small strings ------------
Sample items: (10346 total)
dmnowa yshtrxorj vthjk okrxegip vwpoltck
...
Benchmarks:
1: hashset: end -- 100.00 % -- [Elapsed: 0.0017443 sec]
2: hashset: late -- 102.91 % -- [Elapsed: 0.0017951 sec]
3: hashset: middle -- 106.23 % -- [Elapsed: 0.0018529 sec]
4: list: early -- 107.49 % -- [Elapsed: 0.0018749 sec]
5: list: start -- 126.23 % -- [Elapsed: 0.0022018 sec]
6: hashset: early -- 134.11 % -- [Elapsed: 0.0023393 sec]
7: hashset: start -- 372.09 % -- [Elapsed: 0.0064903 sec]
8: list: middle -- 48,593.79 % -- [Elapsed: 0.8476214 sec]
9: list: end -- 99,020.73 % -- [Elapsed: 1.7272186 sec]
10: list: late -- 99,089.36 % -- [Elapsed: 1.7284155 sec]
---------- Testing few long strings ------------
Sample items: (19 total)
hidfymjyjtffcjmlcaoivbylakmqgoiowbgxpyhnrreodxyleehkhsofjqenyrrtlphbcnvdrbqdvji...
...
Benchmarks:
1: list: early -- 100.00 % -- [Elapsed: 0.0018266 sec]
2: list: start -- 115.76 % -- [Elapsed: 0.0021144 sec]
3: list: middle -- 143.44 % -- [Elapsed: 0.0026201 sec]
4: list: late -- 190.05 % -- [Elapsed: 0.0034715 sec]
5: list: end -- 193.78 % -- [Elapsed: 0.0035395 sec]
6: hashset: early -- 215.00 % -- [Elapsed: 0.0039271 sec]
7: hashset: end -- 248.47 % -- [Elapsed: 0.0045386 sec]
8: hashset: start -- 298.04 % -- [Elapsed: 0.005444 sec]
9: hashset: middle -- 325.63 % -- [Elapsed: 0.005948 sec]
10: hashset: late -- 431.62 % -- [Elapsed: 0.0078839 sec]
---------- Testing many long strings ------------
Sample items: (5000 total)
yrpjccgxjbketcpmnvyqvghhlnjblhgimybdygumtijtrwaromwrajlsjhxoselbucqualmhbmwnvnpnm
...
Benchmarks:
1: list: early -- 100.00 % -- [Elapsed: 0.0016211 sec]
2: list: start -- 132.73 % -- [Elapsed: 0.0021517 sec]
3: hashset: start -- 231.26 % -- [Elapsed: 0.003749 sec]
4: hashset: end -- 368.74 % -- [Elapsed: 0.0059776 sec]
5: hashset: middle -- 385.50 % -- [Elapsed: 0.0062493 sec]
6: hashset: late -- 406.23 % -- [Elapsed: 0.0065854 sec]
7: hashset: early -- 421.34 % -- [Elapsed: 0.0068304 sec]
8: list: middle -- 18,619.12 % -- [Elapsed: 0.3018345 sec]
9: list: end -- 40,942.82 % -- [Elapsed: 0.663724 sec]
10: list: late -- 41,188.19 % -- [Elapsed: 0.6677017 sec]
---------- Testing few ints ------------
Sample items: (16 total)
7266092 60668895 159021363 216428460 28007724
...
Benchmarks:
1: hashset: early -- 100.00 % -- [Elapsed: 0.0016211 sec]
2: hashset: end -- 100.45 % -- [Elapsed: 0.0016284 sec]
3: list: early -- 101.83 % -- [Elapsed: 0.0016507 sec]
4: hashset: late -- 108.95 % -- [Elapsed: 0.0017662 sec]
5: hashset: middle -- 112.29 % -- [Elapsed: 0.0018204 sec]
6: hashset: start -- 120.33 % -- [Elapsed: 0.0019506 sec]
7: list: late -- 134.45 % -- [Elapsed: 0.0021795 sec]
8: list: start -- 136.43 % -- [Elapsed: 0.0022117 sec]
9: list: end -- 169.77 % -- [Elapsed: 0.0027522 sec]
10: list: middle -- 237.94 % -- [Elapsed: 0.0038573 sec]
---------- Testing many ints ------------
Sample items: (10357 total)
370826556 569127161 101235820 792075135 270823009
...
Benchmarks:
1: list: early -- 100.00 % -- [Elapsed: 0.0015132 sec]
2: hashset: end -- 101.79 % -- [Elapsed: 0.0015403 sec]
3: hashset: early -- 102.08 % -- [Elapsed: 0.0015446 sec]
4: hashset: middle -- 103.21 % -- [Elapsed: 0.0015618 sec]
5: hashset: late -- 104.26 % -- [Elapsed: 0.0015776 sec]
6: list: start -- 126.78 % -- [Elapsed: 0.0019184 sec]
7: hashset: start -- 130.91 % -- [Elapsed: 0.0019809 sec]
8: list: middle -- 16,497.89 % -- [Elapsed: 0.2496461 sec]
9: list: end -- 32,715.52 % -- [Elapsed: 0.4950512 sec]
10: list: late -- 33,698.87 % -- [Elapsed: 0.5099313 sec]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-26 14:45:23
Breakeven będzie zależeć od kosztów obliczenia hash. Obliczenia hashowe mogą być trywialne lub nie... :- ) Zawsze jest System.Kolekcje.Specjalistyczne.Klasa HybridDictionary, która pomoże Ci nie martwić się o punkt breakeven.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-09-29 21:29:32
Odpowiedź jak zawsze brzmi "to zależy ". Zakładam, że z tagów mówisz o C#.
Najlepiej określić
- zbiór danych
- Wymagania użytkowania
I napisać kilka spraw testowych.
Zależy również od tego, jak posortujesz listę( jeśli w ogóle jest posortowana), jakiego rodzaju porównania należy dokonać, jak długo operacja "Porównaj" zajmuje konkretnemu obiektowi na liście, a nawet jak zamierzasz użyć kolekcja.
Ogólnie rzecz biorąc, najlepszy wybór nie zależy tak bardzo od rozmiaru danych, z którymi pracujesz, ale raczej od tego, jak zamierzasz uzyskać do nich dostęp. Czy każdy fragment danych jest powiązany z określonym ciągiem znaków lub innymi danymi? Kolekcja oparta na haszu byłaby prawdopodobnie najlepsza. Czy kolejność przechowywanych danych jest ważna, czy też będziesz musiał uzyskać dostęp do wszystkich danych w tym samym czasie? Regularna lista może być wtedy lepsza.
Dodatkowy:
Oczywiście, mój powyższe komentarze zakładają, że "wydajność" oznacza dostęp do danych. Coś jeszcze do rozważenia: czego szukasz, mówiąc "wydajność"? Czy wydajność jest wartością indywidualną? Czy zarządzanie dużymi (10000, 100000 lub więcej) zestawami wartości? Czy jest to wydajność wypełniania struktury danych danymi? Usuwanie danych? Dostęp do poszczególnych bitów danych? Zastępowanie wartości? Iterowanie wartości? Zużycie pamięci? Prędkość kopiowania danych? Na przykład, jeśli uzyskujesz dostęp do danych za pomocą wartości łańcuchowej, ale Twoim głównym wymogiem wydajności jest Minimalne zużycie pamięci, możesz mieć sprzeczne problemy z projektem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-10-29 10:50:55
Możesz użyć HybridDictionary, który automatycznie wykrywa punkt załamania i akceptuje wartości null, co czyni go zasadniczo takim samym jak HashSet.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-10-23 16:55:51
To zależy. Jeśli dokładna odpowiedź naprawdę ma znaczenie, wykonaj profilowanie i dowiedz się. Jeśli jesteś pewien, że nigdy nie będziesz mieć więcej niż określoną liczbę elementów w zestawie, wybierz listę. Jeśli liczba jest nieograniczona, użyj HashSet.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-09-29 21:28:37
Zależy od tego, co mieszasz. Jeśli Twoje klucze są liczbami całkowitymi, prawdopodobnie nie potrzebujesz zbyt wielu elementów, zanim HashSet będzie szybszy. Jeśli kluczujesz go na łańcuchu, będzie on wolniejszy i zależy od łańcucha wejściowego.
Na pewno można stworzyć benchmark dość łatwo?
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-09-29 21:31:29
Jednym z czynników, których nie bierzesz pod uwagę, jest solidność funkcji GetHashcode (). Dzięki doskonałej funkcji HashSet będzie wyraźnie miał lepszą wydajność wyszukiwania. Ale jak funkcja hash maleje, tak będzie czas wyszukiwania HashSet.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-09-29 22:56:17
Zależy od wielu czynników... Implementacja List, Architektura CPU, JVM, semantyka pętli, złożoność metody equals, itd... Zanim lista stanie się wystarczająco duża, aby skutecznie porównywać (ponad 1000 elementów), binarne wyszukiwanie oparte na Hash pokonało wyszukiwanie liniowe hands-down, a różnica skaluje się od tego momentu.
Mam nadzieję, że to pomoże!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-09-29 21:29:49