Jak zrobić vlookup i wypełnić (jak w Excelu) w R?
Mam zbiór danych około 105000 wierszy i 30 kolumn. Mam zmienną kategoryczną, którą chciałbym przypisać do liczby. W Excelu prawdopodobnie zrobiłbym coś z VLOOKUP i wypełnił.
Jak miałbym zrobić to samo w R?
Zasadniczo mam zmienną HouseType i muszę obliczyć HouseTypeNo. Oto kilka przykładowych danych:
HouseType HouseTypeNo
Semi 1
Single 2
Row 3
Single 2
Apartment 4
Apartment 4
Row 3
8 answers
Jeśli dobrze rozumiem twoje pytanie, oto cztery metody, aby zrobić odpowiednik VLOOKUP Excela i wypełnić za pomocą R:
# load sample data from Q
hous <- read.table(header = TRUE,
stringsAsFactors = FALSE,
text="HouseType HouseTypeNo
Semi 1
Single 2
Row 3
Single 2
Apartment 4
Apartment 4
Row 3")
# create a toy large table with a 'HouseType' column
# but no 'HouseTypeNo' column (yet)
largetable <- data.frame(HouseType = as.character(sample(unique(hous$HouseType), 1000, replace = TRUE)), stringsAsFactors = FALSE)
# create a lookup table to get the numbers to fill
# the large table
lookup <- unique(hous)
HouseType HouseTypeNo
1 Semi 1
2 Single 2
3 Row 3
5 Apartment 4
Oto cztery metody wypełniania HouseTypeNo w largetable przy użyciu wartości w tabeli lookup:
Pierwszy z merge w bazie:
# 1. using base
base1 <- (merge(lookup, largetable, by = 'HouseType'))
Druga metoda z nazwanymi wektorami w bazie:
# 2. using base and a named vector
housenames <- as.numeric(1:length(unique(hous$HouseType)))
names(housenames) <- unique(hous$HouseType)
base2 <- data.frame(HouseType = largetable$HouseType,
HouseTypeNo = (housenames[largetable$HouseType]))
Po Trzecie, używając pakietu plyr:
# 3. using the plyr package
library(plyr)
plyr1 <- join(largetable, lookup, by = "HouseType")
Po czwarte, za pomocą sqldf pakietu
# 4. using the sqldf package
library(sqldf)
sqldf1 <- sqldf("SELECT largetable.HouseType, lookup.HouseTypeNo
FROM largetable
INNER JOIN lookup
ON largetable.HouseType = lookup.HouseType")
Jeśli to możliwe, że niektóre typy domów w largetable nie istnieją w lookup wtedy używane byłoby połączenie lewe:
sqldf("select * from largetable left join lookup using (HouseType)")
Potrzebne byłyby również odpowiednie zmiany w innych rozwiązaniach.
To chciałeś zrobić? Daj znać, którą metodę lubisz, a dodam komentarz.Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-06-11 04:47:42
Myślę, że możesz również użyć match():
largetable$HouseTypeNo <- with(lookup,
HouseTypeNo[match(largetable$HouseType,
HouseType)])
lookup.Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-10-20 20:34:29
Lubię też używać qdapTools::lookup lub krótkiego operatora binarnego %l%. Działa identycznie jak Excel vlookup, ale akceptuje argumenty nazw w przeciwieństwie do liczb kolumn
## Replicate Ben's data:
hous <- structure(list(HouseType = c("Semi", "Single", "Row", "Single",
"Apartment", "Apartment", "Row"), HouseTypeNo = c(1L, 2L, 3L,
2L, 4L, 4L, 3L)), .Names = c("HouseType", "HouseTypeNo"),
class = "data.frame", row.names = c(NA, -7L))
largetable <- data.frame(HouseType = as.character(sample(unique(hous$HouseType),
1000, replace = TRUE)), stringsAsFactors = FALSE)
## It's this simple:
library(qdapTools)
largetable[, 1] %l% hous
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-11-03 20:51:29
Rozwiązanie # 2 odpowiedzi @ Ben nie jest powtarzalne w innych bardziej ogólnych przykładach. Zdarza się, że w przykładzie podano poprawne wyszukiwanie, ponieważ unikalne HouseType w houses pojawiają się w rosnącej kolejności. Spróbuj tego:
hous <- read.table(header = TRUE, stringsAsFactors = FALSE, text="HouseType HouseTypeNo
Semi 1
ECIIsHome 17
Single 2
Row 3
Single 2
Apartment 4
Apartment 4
Row 3")
largetable <- data.frame(HouseType = as.character(sample(unique(hous$HouseType), 1000, replace = TRUE)), stringsAsFactors = FALSE)
lookup <- unique(hous)
Bens solution # 2 daje
housenames <- as.numeric(1:length(unique(hous$HouseType)))
names(housenames) <- unique(hous$HouseType)
base2 <- data.frame(HouseType = largetable$HouseType,
HouseTypeNo = (housenames[largetable$HouseType]))
Które kiedy
unique(base2$HouseTypeNo[ base2$HouseType=="ECIIsHome" ])
[1] 2
Gdy poprawna odpowiedź to 17 z tabeli lookup
Poprawnym sposobem jest
hous <- read.table(header = TRUE, stringsAsFactors = FALSE, text="HouseType HouseTypeNo
Semi 1
ECIIsHome 17
Single 2
Row 3
Single 2
Apartment 4
Apartment 4
Row 3")
largetable <- data.frame(HouseType = as.character(sample(unique(hous$HouseType), 1000, replace = TRUE)), stringsAsFactors = FALSE)
housenames <- tapply(hous$HouseTypeNo, hous$HouseType, unique)
base2 <- data.frame(HouseType = largetable$HouseType,
HouseTypeNo = (housenames[largetable$HouseType]))
Teraz wyszukiwanie jest wykonywane poprawnie
unique(base2$HouseTypeNo[ base2$HouseType=="ECIIsHome" ])
ECIIsHome
17
Próbowałem edytuj Bens odpowiedz, ale zostaje odrzucona z powodów, których nie mogę zrozumieć.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-12-09 19:08:47
Zaczynając od:
houses <- read.table(text="Semi 1
Single 2
Row 3
Single 2
Apartment 4
Apartment 4
Row 3",col.names=c("HouseType","HouseTypeNo"))
... możesz użyć
as.numeric(factor(houses$HouseType))
... aby dać unikalny numer dla każdego typu domu. Możesz zobaczyć wynik tutaj:
> houses2 <- data.frame(houses,as.numeric(factor(houses$HouseType)))
> houses2
HouseType HouseTypeNo as.numeric.factor.houses.HouseType..
1 Semi 1 3
2 Single 2 4
3 Row 3 2
4 Single 2 4
5 Apartment 4 1
6 Apartment 4 1
7 Row 3 2
... więc kończy się z różnymi liczbami w wierszach (ponieważ czynniki są uporządkowane alfabetycznie), ale ten sam wzór.
(EDIT: pozostały tekst w tej odpowiedzi jest rzeczywiście zbędny. Przyszło mi do głowy, aby sprawdzić i okazało się, że read.table() już wykonane domy$HouseType w czynnik, gdy został odczytany w dataframe w pierwszej kolejności).
Jednak może być lepiej po prostu przekonwertować HouseType na czynnik, który dałby ci wszystkie te same korzyści co HouseTypeNo, ale byłoby łatwiej zinterpretować, ponieważ typy domów są nazwane, a nie numerowane, np.:
> houses3 <- houses
> houses3$HouseType <- factor(houses3$HouseType)
> houses3
HouseType HouseTypeNo
1 Semi 1
2 Single 2
3 Row 3
4 Single 2
5 Apartment 4
6 Apartment 4
7 Row 3
> levels(houses3$HouseType)
[1] "Apartment" "Row" "Semi" "Single"
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-03-08 21:38:17
Plakat nie pytał o szukanie wartości if exact=FALSE, ale dodaję to jako odpowiedź dla mojego własnego odniesienia i ewentualnie innych.
Jeśli szukasz wartości kategorycznych, użyj innych odpowiedzi.
Excel ' s vlookup pozwala również dopasować dopasowanie w przybliżeniu wartości liczbowych za pomocą czwartego argumentu (1) match=TRUE. Myślę o match=TRUE Jak o sprawdzaniu wartości na termometrze. Wartością domyślną jest FALSE, która jest idealna dla wartości kategorycznych.
Jeśli chcesz dopasuj w przybliżeniu (wykonaj wyszukiwanie), R ma funkcję o nazwie findInterval, która (jak sama nazwa wskazuje) znajdzie interwał / bin zawierający twoją ciągłą wartość liczbową.
Powiedzmy jednak, że chcesz findInterval dla kilku wartości. Możesz napisać pętlę lub użyć funkcji zastosuj. Jednak uważam, że bardziej skuteczne jest podejście DIY wektoryzowane.
Załóżmy, że masz siatkę wartości indeksowanych przez x i y:
grid <- list(x = c(-87.727, -87.723, -87.719, -87.715, -87.711),
y = c(41.836, 41.839, 41.843, 41.847, 41.851),
z = (matrix(data = c(-3.428, -3.722, -3.061, -2.554, -2.362,
-3.034, -3.925, -3.639, -3.357, -3.283,
-0.152, -1.688, -2.765, -3.084, -2.742,
1.973, 1.193, -0.354, -1.682, -1.803,
0.998, 2.863, 3.224, 1.541, -0.044),
nrow = 5, ncol = 5)))
I masz jakieś wartości ty chcesz szukać w górę Przez x i y:
df <- data.frame(x = c(-87.723, -87.712, -87.726, -87.719, -87.722, -87.722),
y = c(41.84, 41.842, 41.844, 41.849, 41.838, 41.842),
id = c("a", "b", "c", "d", "e", "f")
Oto przykład:
contour(grid)
points(df$x, df$y, pch=df$id, col="blue", cex=1.2)

Można znaleźć przedziały x i Y O tego typu wzorze:
xrng <- range(grid$x)
xbins <- length(grid$x) -1
yrng <- range(grid$y)
ybins <- length(grid$y) -1
df$ix <- trunc( (df$x - min(xrng)) / diff(xrng) * (xbins)) + 1
df$iy <- trunc( (df$y - min(yrng)) / diff(yrng) * (ybins)) + 1
Możesz pójść o krok dalej i wykonać (uproszczoną) interpolację na wartościach z w grid w następujący sposób:
df$z <- with(df, (grid$z[cbind(ix, iy)] +
grid$z[cbind(ix + 1, iy)] +
grid$z[cbind(ix, iy + 1)] +
grid$z[cbind(ix + 1, iy + 1)]) / 4)
Który daje Ci te wartości:
contour(grid, xlim = range(c(grid$x, df$x)), ylim = range(c(grid$y, df$y)))
points(df$x, df$y, pch=df$id, col="blue", cex=1.2)
text(df$x + .001, df$y, lab=round(df$z, 2), col="blue", cex=1)
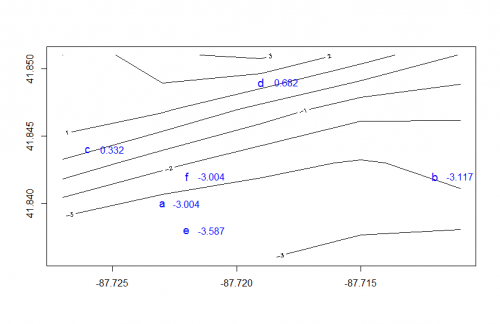
df
# x y id ix iy z
# 1 -87.723 41.840 a 2 2 -3.00425
# 2 -87.712 41.842 b 4 2 -3.11650
# 3 -87.726 41.844 c 1 3 0.33150
# 4 -87.719 41.849 d 3 4 0.68225
# 6 -87.722 41.838 e 2 1 -3.58675
# 7 -87.722 41.842 f 2 2 -3.00425
Zauważ, że ix i iy mogły być również Znalezione z pętla za pomocą findInterval, np. oto jeden przykład dla drugiego wiersza
findInterval(df$x[2], grid$x)
# 4
findInterval(df$y[2], grid$y)
# 2
Które pasują ix i iy W df[2]
Przypisy: (1) czwarty argument vlookup był wcześniej nazywany "match", ale po wprowadzeniu wstążki został przemianowany na "[range_lookup]".
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-12-11 18:04:34
Możesz użyć mapvalues() z pakietu plyr.
Dane początkowe:
dat <- data.frame(HouseType = c("Semi", "Single", "Row", "Single", "Apartment", "Apartment", "Row"))
> dat
HouseType
1 Semi
2 Single
3 Row
4 Single
5 Apartment
6 Apartment
7 Row
Lookup / crosswalk table:
lookup <- data.frame(type_text = c("Semi", "Single", "Row", "Apartment"), type_num = c(1, 2, 3, 4))
> lookup
type_text type_num
1 Semi 1
2 Single 2
3 Row 3
4 Apartment 4
Utwórz nową zmienną:
dat$house_type_num <- plyr::mapvalues(dat$HouseType, from = lookup$type_text, to = lookup$type_num)
Lub w przypadku prostych zamienników możesz pominąć tworzenie długiej tabeli wyszukiwania i zrobić to bezpośrednio w jednym kroku:
dat$house_type_num <- plyr::mapvalues(dat$HouseType,
from = c("Semi", "Single", "Row", "Apartment"),
to = c(1, 2, 3, 4))
Wynik:
> dat
HouseType house_type_num
1 Semi 1
2 Single 2
3 Row 3
4 Single 2
5 Apartment 4
6 Apartment 4
7 Row 3
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-10-20 20:37:18
Użycie merge różni się od wyszukiwania w programie Excel, ponieważ może powielać (mnożyć) dane, jeśli podstawowe ograniczenie klucza nie jest wymuszone w tabeli wyszukiwania lub zmniejszyć liczbę rekordów, jeśli nie używasz all.x = T.
Aby upewnić się, że nie wpadniesz w kłopoty z tym i wyszukiwanie bezpiecznie, proponuję dwie strategie.
Pierwszym z nich jest sprawdzenie liczby zduplikowanych wierszy w kluczu lookup:
safeLookup <- function(data, lookup, by, select = setdiff(colnames(lookup), by)) {
# Merges data to lookup making sure that the number of rows does not change.
stopifnot(sum(duplicated(lookup[, by])) == 0)
res <- merge(data, lookup[, c(by, select)], by = by, all.x = T)
return (res)
}
To zmusi cię do usunięcia dupe lookup dataset przed użyciem it:
baseSafe <- safeLookup(largetable, house.ids, by = "HouseType")
# Error: sum(duplicated(lookup[, by])) == 0 is not TRUE
baseSafe<- safeLookup(largetable, unique(house.ids), by = "HouseType")
head(baseSafe)
# HouseType HouseTypeNo
# 1 Apartment 4
# 2 Apartment 4
# ...
Drugą opcją jest odtworzenie zachowania programu Excel poprzez pobranie pierwszej pasującej wartości z zbioru danych lookup:
firstLookup <- function(data, lookup, by, select = setdiff(colnames(lookup), by)) {
# Merges data to lookup using first row per unique combination in by.
unique.lookup <- lookup[!duplicated(lookup[, by]), ]
res <- merge(data, unique.lookup[, c(by, select)], by = by, all.x = T)
return (res)
}
baseFirst <- firstLookup(largetable, house.ids, by = "HouseType")
Te funkcje różnią się nieco od lookup, ponieważ dodają wiele kolumn.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-05-21 23:03:54