Dlaczego Java switch on contiguous ints wydaje się działać szybciej z dodanymi przypadkami?
Pracuję nad kodem Javy, który musi być wysoce zoptymalizowany, ponieważ będzie działał w gorących funkcjach, które są wywoływane w wielu punktach mojej Głównej Logiki programu. Część tego kodu polega na mnożeniu zmiennych double przez 10 podniesionych do arbitralnie nieujemnych int exponents. jednym szybkim sposobem (edit: ale nie najszybszym możliwym, patrz Aktualizacja 2 poniżej), aby uzyskać mnożoną wartość, jest switch na exponent:
double multiplyByPowerOfTen(final double d, final int exponent) {
switch (exponent) {
case 0:
return d;
case 1:
return d*10;
case 2:
return d*100;
// ... same pattern
case 9:
return d*1000000000;
case 10:
return d*10000000000L;
// ... same pattern with long literals
case 18:
return d*1000000000000000000L;
default:
throw new ParseException("Unhandled power of ten " + power, 0);
}
}
Skomentowane elipsy powyżej wskazują, że case int stałe nadal zwiększają się o 1, więc w powyższym fragmencie kodu jest naprawdę 19 cases. Ponieważ nie byłem pewien, czy rzeczywiście będę potrzebował wszystkich mocy 10 W case poleceniach 10 przez 18, przeprowadziłem kilka mikrobenchmarks porównując czas wykonania 10 milionów operacji z tym poleceniem switch w porównaniu z {5]} z tylko case s 0 przez 9 (z exponent ograniczonym do 9 lub mniej, aby uniknąć przerwania pared-down switch). Mam dość zaskakujące (przynajmniej dla mnie!) wynik, który dłuższe switch z większą liczbą case wypowiedzi faktycznie biegły szybciej.
Na skowronku, próbowałem dodać jeszcze więcej case s, które po prostu zwróciły wartości atrapy i okazało się, że mogę uzyskać przełącznik, aby działał jeszcze szybciej z około 22-27 zadeklarowanymi cases (nawet jeśli te atrapy nigdy nie są faktycznie trafione podczas działania kodu). (Ponownie, cases zostały dodane w sposób ciągły, zwiększając poprzednią case stałą o 1.) Te różnice w czasie realizacji nie są bardzo istotne: dla losowe exponent pomiędzy 0 A 10, oświadczenie dummy padded switch kończy 10 milionów egzekucji w ciągu 1,49 sekundy w porównaniu z 1,54 sekundy dla wersji niepodanej, co daje całkowitą oszczędność 5ns Na wykonanie. Więc nie jest to coś, co sprawia, że obsesja na punkcie wypełniania switch oświadczenia jest warta wysiłku z punktu widzenia optymalizacji. Ale nadal uważam to za ciekawe i sprzeczne z intuicją, że switch nie staje się wolniejszy (a może w najlepszym razie utrzymuje stały o(1) czas), aby wykonaj jako więcej case s są dodawane do niego.
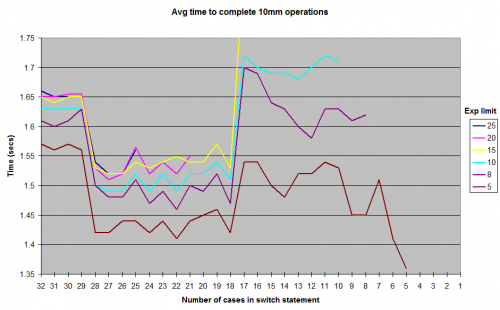
Oto wyniki, które uzyskałem z pracy z różnymi limitami losowo generowanych wartości exponent. Nie uwzględniłem wyników aż do 1 dla exponent granicy, ale ogólny kształt krzywej pozostaje taki sam, z grzbietem wokół znaku przypadku 12-17 i Doliną między 18-28. Wszystkie testy były uruchamiane w JUnitBenchmarks przy użyciu współdzielonych kontenerów dla losowych wartości, aby zapewnić identyczne testy wejścia. Przeprowadziłem również testy zarówno w kolejności od najdłuższego switch Oświadczenia do najkrótszego, i odwrotnie, aby spróbować wyeliminować możliwość zamawiania problemów związanych z testami. Umieściłem mój kod testowy na repo github, jeśli ktoś chce spróbować odtworzyć te wyniki.
switch jest naprawdę trochę szybsza do wykonania w 18 aby 28 case zakres od 11 do 17?
Github test repo "Switch-experiment"
UPDATE: trochę wyczyściłem bibliotekę benchmarkingu i dodałem plik tekstowy w /results z pewnym wynikiem w szerszym zakresie możliwych wartości exponent. Dodałem również opcję w kodzie testowym, aby nie rzucać Exception z default, ale wydaje się, że nie wpływa to na wyniki.
UPDATE 2: znalazłem całkiem dobrą dyskusję na ten temat z 2009 roku na forum xkcd tutaj: http://forums.xkcd.com/viewtopic.php?f=11&t=33524 . dyskusja OP na temat używania Array.binarySearch() dała mi pomysł na prostą implementację wzorca wykładniczego opartego na tablicach powyżej. Nie ma potrzeby wyszukiwania binarnego, ponieważ Wiem, jakie są wpisy w array. Wydaje się, że działa około 3 razy szybciej niż użycie switch, oczywiście kosztem niektórych przepływów sterowania, które zapewnia switch. Ten kod został również dodany do repozytorium github.
4 answers
Jak zaznaczono przez drugą odpowiedź , ponieważ wartości case są sąsiadujące ze sobą (w przeciwieństwie do sparse), wygenerowany bajt kodu dla różnych testów używa tabeli przełączników (Instrukcja bytecode tableswitch).
Jednakże, gdy JIT rozpocznie swoje zadanie i skompiluje bajt kodu do złożenia, Instrukcja tableswitch nie zawsze skutkuje tablicą wskaźników: czasami tablica przełączników jest przekształcana w coś, co wygląda jak lookupswitch (podobne do if / {7]} struktura).
Dekompilacja zestawu wygenerowanego przez JIT (hotspot JDK 1.7) pokazuje, że używa następstwa if / else if, gdy jest 17 przypadków lub mniej, tablicy wskaźników, gdy jest więcej niż 18 (bardziej wydajne).
Powód, dla którego ta magiczna liczba 18 jest używana wydaje się sprowadzać do domyślnej wartości MinJumpTableSize flaga JVM (wokół linii 352 w kodzie).
Podniosłem problem na liście kompilatorów hotspotów i wydaje się, że jest to legacy of past testing . Zauważ, że ta domyślna wartość została usunięta w JDK 8 Po więcej benchmarking został wykonany.
Wreszcie, gdy metoda staje się zbyt długa (>25 przypadków w moich testach), nie jest już inlined z domyślnymi ustawieniami JVM - to jest najbardziej prawdopodobna przyczyna spadku wydajności w tym momencie.
W 5 przypadkach dekompilowany kod wygląda tak (zwróć uwagę na instrukcje cmp / je / jg/ jmp, montaż dla if / goto):
[Verified Entry Point]
# {method} 'multiplyByPowerOfTen' '(DI)D' in 'javaapplication4/Test1'
# parm0: xmm0:xmm0 = double
# parm1: rdx = int
# [sp+0x20] (sp of caller)
0x00000000024f0160: mov DWORD PTR [rsp-0x6000],eax
; {no_reloc}
0x00000000024f0167: push rbp
0x00000000024f0168: sub rsp,0x10 ;*synchronization entry
; - javaapplication4.Test1::multiplyByPowerOfTen@-1 (line 56)
0x00000000024f016c: cmp edx,0x3
0x00000000024f016f: je 0x00000000024f01c3
0x00000000024f0171: cmp edx,0x3
0x00000000024f0174: jg 0x00000000024f01a5
0x00000000024f0176: cmp edx,0x1
0x00000000024f0179: je 0x00000000024f019b
0x00000000024f017b: cmp edx,0x1
0x00000000024f017e: jg 0x00000000024f0191
0x00000000024f0180: test edx,edx
0x00000000024f0182: je 0x00000000024f01cb
0x00000000024f0184: mov ebp,edx
0x00000000024f0186: mov edx,0x17
0x00000000024f018b: call 0x00000000024c90a0 ; OopMap{off=48}
;*new ; - javaapplication4.Test1::multiplyByPowerOfTen@72 (line 83)
; {runtime_call}
0x00000000024f0190: int3 ;*new ; - javaapplication4.Test1::multiplyByPowerOfTen@72 (line 83)
0x00000000024f0191: mulsd xmm0,QWORD PTR [rip+0xffffffffffffffa7] # 0x00000000024f0140
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@52 (line 62)
; {section_word}
0x00000000024f0199: jmp 0x00000000024f01cb
0x00000000024f019b: mulsd xmm0,QWORD PTR [rip+0xffffffffffffff8d] # 0x00000000024f0130
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@46 (line 60)
; {section_word}
0x00000000024f01a3: jmp 0x00000000024f01cb
0x00000000024f01a5: cmp edx,0x5
0x00000000024f01a8: je 0x00000000024f01b9
0x00000000024f01aa: cmp edx,0x5
0x00000000024f01ad: jg 0x00000000024f0184 ;*tableswitch
; - javaapplication4.Test1::multiplyByPowerOfTen@1 (line 56)
0x00000000024f01af: mulsd xmm0,QWORD PTR [rip+0xffffffffffffff81] # 0x00000000024f0138
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@64 (line 66)
; {section_word}
0x00000000024f01b7: jmp 0x00000000024f01cb
0x00000000024f01b9: mulsd xmm0,QWORD PTR [rip+0xffffffffffffff67] # 0x00000000024f0128
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@70 (line 68)
; {section_word}
0x00000000024f01c1: jmp 0x00000000024f01cb
0x00000000024f01c3: mulsd xmm0,QWORD PTR [rip+0xffffffffffffff55] # 0x00000000024f0120
;*tableswitch
; - javaapplication4.Test1::multiplyByPowerOfTen@1 (line 56)
; {section_word}
0x00000000024f01cb: add rsp,0x10
0x00000000024f01cf: pop rbp
0x00000000024f01d0: test DWORD PTR [rip+0xfffffffffdf3fe2a],eax # 0x0000000000430000
; {poll_return}
0x00000000024f01d6: ret
W przypadku 18 przypadków Zgromadzenie wygląda tak (zwróć uwagę na tablicę wskaźników, która jest używana i tłumi potrzebę wszystkich porównań: jmp QWORD PTR [r8+r10*1] przeskakuje bezpośrednio do prawego mnożenia) - jest to prawdopodobna przyczyna poprawy wydajności:
[Verified Entry Point]
# {method} 'multiplyByPowerOfTen' '(DI)D' in 'javaapplication4/Test1'
# parm0: xmm0:xmm0 = double
# parm1: rdx = int
# [sp+0x20] (sp of caller)
0x000000000287fe20: mov DWORD PTR [rsp-0x6000],eax
; {no_reloc}
0x000000000287fe27: push rbp
0x000000000287fe28: sub rsp,0x10 ;*synchronization entry
; - javaapplication4.Test1::multiplyByPowerOfTen@-1 (line 56)
0x000000000287fe2c: cmp edx,0x13
0x000000000287fe2f: jae 0x000000000287fe46
0x000000000287fe31: movsxd r10,edx
0x000000000287fe34: shl r10,0x3
0x000000000287fe38: movabs r8,0x287fd70 ; {section_word}
0x000000000287fe42: jmp QWORD PTR [r8+r10*1] ;*tableswitch
; - javaapplication4.Test1::multiplyByPowerOfTen@1 (line 56)
0x000000000287fe46: mov ebp,edx
0x000000000287fe48: mov edx,0x31
0x000000000287fe4d: xchg ax,ax
0x000000000287fe4f: call 0x00000000028590a0 ; OopMap{off=52}
;*new ; - javaapplication4.Test1::multiplyByPowerOfTen@202 (line 96)
; {runtime_call}
0x000000000287fe54: int3 ;*new ; - javaapplication4.Test1::multiplyByPowerOfTen@202 (line 96)
0x000000000287fe55: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe8b] # 0x000000000287fce8
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@194 (line 92)
; {section_word}
0x000000000287fe5d: jmp 0x000000000287ff16
0x000000000287fe62: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe86] # 0x000000000287fcf0
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@188 (line 90)
; {section_word}
0x000000000287fe6a: jmp 0x000000000287ff16
0x000000000287fe6f: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe81] # 0x000000000287fcf8
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@182 (line 88)
; {section_word}
0x000000000287fe77: jmp 0x000000000287ff16
0x000000000287fe7c: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe7c] # 0x000000000287fd00
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@176 (line 86)
; {section_word}
0x000000000287fe84: jmp 0x000000000287ff16
0x000000000287fe89: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe77] # 0x000000000287fd08
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@170 (line 84)
; {section_word}
0x000000000287fe91: jmp 0x000000000287ff16
0x000000000287fe96: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe72] # 0x000000000287fd10
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@164 (line 82)
; {section_word}
0x000000000287fe9e: jmp 0x000000000287ff16
0x000000000287fea0: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe70] # 0x000000000287fd18
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@158 (line 80)
; {section_word}
0x000000000287fea8: jmp 0x000000000287ff16
0x000000000287feaa: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe6e] # 0x000000000287fd20
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@152 (line 78)
; {section_word}
0x000000000287feb2: jmp 0x000000000287ff16
0x000000000287feb4: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe24] # 0x000000000287fce0
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@146 (line 76)
; {section_word}
0x000000000287febc: jmp 0x000000000287ff16
0x000000000287febe: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe6a] # 0x000000000287fd30
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@140 (line 74)
; {section_word}
0x000000000287fec6: jmp 0x000000000287ff16
0x000000000287fec8: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe68] # 0x000000000287fd38
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@134 (line 72)
; {section_word}
0x000000000287fed0: jmp 0x000000000287ff16
0x000000000287fed2: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe66] # 0x000000000287fd40
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@128 (line 70)
; {section_word}
0x000000000287feda: jmp 0x000000000287ff16
0x000000000287fedc: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe64] # 0x000000000287fd48
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@122 (line 68)
; {section_word}
0x000000000287fee4: jmp 0x000000000287ff16
0x000000000287fee6: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe62] # 0x000000000287fd50
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@116 (line 66)
; {section_word}
0x000000000287feee: jmp 0x000000000287ff16
0x000000000287fef0: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe60] # 0x000000000287fd58
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@110 (line 64)
; {section_word}
0x000000000287fef8: jmp 0x000000000287ff16
0x000000000287fefa: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe5e] # 0x000000000287fd60
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@104 (line 62)
; {section_word}
0x000000000287ff02: jmp 0x000000000287ff16
0x000000000287ff04: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe5c] # 0x000000000287fd68
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@98 (line 60)
; {section_word}
0x000000000287ff0c: jmp 0x000000000287ff16
0x000000000287ff0e: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe12] # 0x000000000287fd28
;*tableswitch
; - javaapplication4.Test1::multiplyByPowerOfTen@1 (line 56)
; {section_word}
0x000000000287ff16: add rsp,0x10
0x000000000287ff1a: pop rbp
0x000000000287ff1b: test DWORD PTR [rip+0xfffffffffd9b00df],eax # 0x0000000000230000
; {poll_return}
0x000000000287ff21: ret
I wreszcie zestaw z 30 skrzynkami (poniżej) wygląda podobnie do 18 skrzynek, z wyjątkiem dodatkowego movapd xmm0,xmm1, który pojawia się w środku kodu, , jak zauważył @cHao - jednak najbardziej prawdopodobnym powodem spadku wydajności jest to, że metoda jest zbyt długa, aby można ją było połączyć z domyślnymi ustawieniami JVM:
[Verified Entry Point]
# {method} 'multiplyByPowerOfTen' '(DI)D' in 'javaapplication4/Test1'
# parm0: xmm0:xmm0 = double
# parm1: rdx = int
# [sp+0x20] (sp of caller)
0x0000000002524560: mov DWORD PTR [rsp-0x6000],eax
; {no_reloc}
0x0000000002524567: push rbp
0x0000000002524568: sub rsp,0x10 ;*synchronization entry
; - javaapplication4.Test1::multiplyByPowerOfTen@-1 (line 56)
0x000000000252456c: movapd xmm1,xmm0
0x0000000002524570: cmp edx,0x1f
0x0000000002524573: jae 0x0000000002524592 ;*tableswitch
; - javaapplication4.Test1::multiplyByPowerOfTen@1 (line 56)
0x0000000002524575: movsxd r10,edx
0x0000000002524578: shl r10,0x3
0x000000000252457c: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe3c] # 0x00000000025243c0
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@364 (line 118)
; {section_word}
0x0000000002524584: movabs r8,0x2524450 ; {section_word}
0x000000000252458e: jmp QWORD PTR [r8+r10*1] ;*tableswitch
; - javaapplication4.Test1::multiplyByPowerOfTen@1 (line 56)
0x0000000002524592: mov ebp,edx
0x0000000002524594: mov edx,0x31
0x0000000002524599: xchg ax,ax
0x000000000252459b: call 0x00000000024f90a0 ; OopMap{off=64}
;*new ; - javaapplication4.Test1::multiplyByPowerOfTen@370 (line 120)
; {runtime_call}
0x00000000025245a0: int3 ;*new ; - javaapplication4.Test1::multiplyByPowerOfTen@370 (line 120)
0x00000000025245a1: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe27] # 0x00000000025243d0
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@358 (line 116)
; {section_word}
0x00000000025245a9: jmp 0x0000000002524744
0x00000000025245ae: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe22] # 0x00000000025243d8
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@348 (line 114)
; {section_word}
0x00000000025245b6: jmp 0x0000000002524744
0x00000000025245bb: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe1d] # 0x00000000025243e0
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@338 (line 112)
; {section_word}
0x00000000025245c3: jmp 0x0000000002524744
0x00000000025245c8: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe18] # 0x00000000025243e8
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@328 (line 110)
; {section_word}
0x00000000025245d0: jmp 0x0000000002524744
0x00000000025245d5: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe13] # 0x00000000025243f0
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@318 (line 108)
; {section_word}
0x00000000025245dd: jmp 0x0000000002524744
0x00000000025245e2: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe0e] # 0x00000000025243f8
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@308 (line 106)
; {section_word}
0x00000000025245ea: jmp 0x0000000002524744
0x00000000025245ef: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe09] # 0x0000000002524400
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@298 (line 104)
; {section_word}
0x00000000025245f7: jmp 0x0000000002524744
0x00000000025245fc: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe04] # 0x0000000002524408
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@288 (line 102)
; {section_word}
0x0000000002524604: jmp 0x0000000002524744
0x0000000002524609: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffdff] # 0x0000000002524410
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@278 (line 100)
; {section_word}
0x0000000002524611: jmp 0x0000000002524744
0x0000000002524616: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffdfa] # 0x0000000002524418
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@268 (line 98)
; {section_word}
0x000000000252461e: jmp 0x0000000002524744
0x0000000002524623: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffd9d] # 0x00000000025243c8
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@258 (line 96)
; {section_word}
0x000000000252462b: jmp 0x0000000002524744
0x0000000002524630: movapd xmm0,xmm1
0x0000000002524634: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffe0c] # 0x0000000002524448
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@242 (line 92)
; {section_word}
0x000000000252463c: jmp 0x0000000002524744
0x0000000002524641: movapd xmm0,xmm1
0x0000000002524645: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffddb] # 0x0000000002524428
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@236 (line 90)
; {section_word}
0x000000000252464d: jmp 0x0000000002524744
0x0000000002524652: movapd xmm0,xmm1
0x0000000002524656: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffdd2] # 0x0000000002524430
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@230 (line 88)
; {section_word}
0x000000000252465e: jmp 0x0000000002524744
0x0000000002524663: movapd xmm0,xmm1
0x0000000002524667: mulsd xmm0,QWORD PTR [rip+0xfffffffffffffdc9] # 0x0000000002524438
;*dmul
; - javaapplication4.Test1::multiplyByPowerOfTen@224 (line 86)
; {section_word}
[etc.]
0x0000000002524744: add rsp,0x10
0x0000000002524748: pop rbp
0x0000000002524749: test DWORD PTR [rip+0xfffffffffde1b8b1],eax # 0x0000000000340000
; {poll_return}
0x000000000252474f: ret
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:10:02
Switch-case jest szybszy, jeśli wartości case są umieszczone w wąskim zakresie np.
case 1:
case 2:
case 3:
..
..
case n:
Ponieważ w tym przypadku kompilator może uniknąć porównywania dla każdego elementu case w instrukcji switch. Kompilator tworzy tabelę skoków, która zawiera adresy działań, które mają być podjęte na różnych nogach. Wartość, na której wykonywany jest przełącznik, jest manipulowana, aby przekształcić ją w Indeks w jump table. W tej implementacji czas potrzebny na zmianę instrukcja jest znacznie krótsza niż czas potrzebny w równoważnej kaskadzie instrukcji if-else-if. Również czas potrzebny w instrukcji switch jest niezależny od liczby przypadków w instrukcji switch.
Jak podano w Wikipedii o switch statement w sekcji Kompilacja.
Jeśli zakres wartości wejściowych jest identyfikowalny jako "mały" i ma tylko kilka luk, niektóre Kompilatory zawierające optymalizator mogą faktycznie zaimplementuj instrukcję switch jako tabela gałęzi lub tablica indeksowane Wskaźniki funkcji zamiast długiej serii warunkowych instrukcje. Umożliwia to natychmiastowe określenie instrukcji switch jaką gałąź wykonać bez konieczności przechodzenia przez Listę porównania.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-03-25 17:47:31
Odpowiedź leży w bajtowym kodzie:
SwitchTest10java
public class SwitchTest10 {
public static void main(String[] args) {
int n = 0;
switcher(n);
}
public static void switcher(int n) {
switch(n) {
case 0: System.out.println(0);
break;
case 1: System.out.println(1);
break;
case 2: System.out.println(2);
break;
case 3: System.out.println(3);
break;
case 4: System.out.println(4);
break;
case 5: System.out.println(5);
break;
case 6: System.out.println(6);
break;
case 7: System.out.println(7);
break;
case 8: System.out.println(8);
break;
case 9: System.out.println(9);
break;
case 10: System.out.println(10);
break;
default: System.out.println("test");
}
}
}
Odpowiadający bajt kod; wyświetlane są tylko odpowiednie części:
public static void switcher(int);
Code:
0: iload_0
1: tableswitch{ //0 to 10
0: 60;
1: 70;
2: 80;
3: 90;
4: 100;
5: 110;
6: 120;
7: 131;
8: 142;
9: 153;
10: 164;
default: 175 }
SwitchTest22java:
public class SwitchTest22 {
public static void main(String[] args) {
int n = 0;
switcher(n);
}
public static void switcher(int n) {
switch(n) {
case 0: System.out.println(0);
break;
case 1: System.out.println(1);
break;
case 2: System.out.println(2);
break;
case 3: System.out.println(3);
break;
case 4: System.out.println(4);
break;
case 5: System.out.println(5);
break;
case 6: System.out.println(6);
break;
case 7: System.out.println(7);
break;
case 8: System.out.println(8);
break;
case 9: System.out.println(9);
break;
case 100: System.out.println(10);
break;
case 110: System.out.println(10);
break;
case 120: System.out.println(10);
break;
case 130: System.out.println(10);
break;
case 140: System.out.println(10);
break;
case 150: System.out.println(10);
break;
case 160: System.out.println(10);
break;
case 170: System.out.println(10);
break;
case 180: System.out.println(10);
break;
case 190: System.out.println(10);
break;
case 200: System.out.println(10);
break;
case 210: System.out.println(10);
break;
case 220: System.out.println(10);
break;
default: System.out.println("test");
}
}
}
Odpowiadający bajt kod; ponownie pokazano tylko odpowiednie części:
public static void switcher(int);
Code:
0: iload_0
1: lookupswitch{ //23
0: 196;
1: 206;
2: 216;
3: 226;
4: 236;
5: 246;
6: 256;
7: 267;
8: 278;
9: 289;
100: 300;
110: 311;
120: 322;
130: 333;
140: 344;
150: 355;
160: 366;
170: 377;
180: 388;
190: 399;
200: 410;
210: 421;
220: 432;
default: 443 }
W pierwszym przypadku, z wąskimi zakresami, skompilowany bajt używa tableswitch. W drugim przypadku, skompilowany bajt używa lookupswitch.
W tableswitch, liczba całkowita wartość na górze stosu jest używana do indeksowania do tabeli, aby znaleźć gałąź / cel skoku. Ten skok / gałąź jest następnie wykonywany natychmiast. Jest to więc operacja O(1).
A lookupswitch jest bardziej skomplikowana. W tym przypadku wartość całkowita musi być porównana ze wszystkimi kluczami w tabeli, dopóki nie zostanie znaleziony prawidłowy klucz. Po znalezieniu klucza, gałąź / cel skoku (do którego ten klucz jest mapowany) jest używany do skoku. Tabela używana w lookupswitch jest sortowana i wyszukiwanie binarne algorytm może być użyty do znalezienia właściwego klucza. Wydajność dla wyszukiwania binarnego wynosi O(log n), a cały proces jest również O(log n), ponieważ skok jest nadal O(1). Tak więc powodem, dla którego wydajność jest niższa w przypadku rzadkich zakresów, jest to, że należy najpierw sprawdzić poprawny klucz, ponieważ nie można bezpośrednio indeksować tabeli.
Jeśli są nieliczne wartości i masz tylko {[5] } do użycia, tabela będzie zasadniczo zawierać atrapy wpisów, które wskazują na opcję default. Na przykład, zakładając, że ostatni wpis w SwitchTest10.java był 21 zamiast 10, otrzymujesz:
public static void switcher(int);
Code:
0: iload_0
1: tableswitch{ //0 to 21
0: 104;
1: 114;
2: 124;
3: 134;
4: 144;
5: 154;
6: 164;
7: 175;
8: 186;
9: 197;
10: 219;
11: 219;
12: 219;
13: 219;
14: 219;
15: 219;
16: 219;
17: 219;
18: 219;
19: 219;
20: 219;
21: 208;
default: 219 }
Tak więc kompilator zasadniczo tworzy ogromną tabelę zawierającą atrapy wpisów pomiędzy lukami, wskazując na gałąź docelową instrukcji default. Nawet jeśli nie ma default, będzie on zawierał wpisy wskazujące na instrukcję Po bloku przełącznika. Zrobiłem kilka podstawowych testów i stwierdziłem, że jeśli różnica między ostatnim indeksem a poprzednim (9) jest większa niż 35, to używa lookupswitch zamiast tableswitch.
Zachowanie instrukcji switch jest zdefiniowane w specyfikacji maszyny wirtualnej Java (§3.10):
Gdy przypadki przełącznika są rzadkie, reprezentacja tabeli instrukcji tableswitch staje się nieefektywna pod względem przestrzeni. Zamiast tego można użyć instrukcji lookupswitch. Instrukcja lookupswitch łączy klucze int (wartości etykiet liter) z docelowymi przesunięciami w tabeli. When a lookupswitch zostanie wykonana Instrukcja, wartość wyrażenia przełącznika zostanie porównana z kluczami w tabeli. Jeśli jeden z kluczy pasuje do wartości wyrażenia, wykonanie jest kontynuowane przy powiązanym przesunięciu celu. Jeśli klucz nie pasuje, wykonanie jest kontynuowane przy domyślnym celu. [...]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-03-26 23:04:59
Ponieważ pytanie jest już odpowiedział (mniej więcej), Oto pewna wskazówka. Użycie
private static final double[] mul={1d, 10d...};
static double multiplyByPowerOfTen(final double d, final int exponent) {
if (exponent<0 || exponent>=mul.length) throw new ParseException();//or just leave the IOOBE be
return mul[exponent]*d;
}
Ten kod używa znacznie mniej IC (pamięci podręcznej instrukcji) i będzie zawsze inlined. Tablica będzie w pamięci podręcznej danych L1, jeśli kod jest gorący. Tabela wyszukiwania jest prawie zawsze Wygrana. (esp. na microbenchmarks :D)
Edit: jeśli chcesz, aby metoda była hot-inlined, rozważ nieszybkie ścieżki, takie jak throw new ParseException(), aby były tak krótkie jak minimum lub przenieś je do oddzielnej statycznej metody (w ten sposób je krótkie jak minimum). Oznacza to, że {[2] } jest słabym pomysłem b / c pochłania dużo budżetu inliningowego dla kodu, który można po prostu zinterpretować - string concatenation jest dość gadatliwy w bytecode . Więcej informacji i prawdziwy przypadek w / ArrayList
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-03-30 20:57:08