Parsowanie ogromnych plików logów w węźle.js-odczyt w wierszu po wierszu
Muszę wykonać parsowanie dużych (5-10 Gb)plików logów w Javascript / Node.js (używam Cube).
Logline wygląda tak:
10:00:43.343423 I'm a friendly log message. There are 5 cats, and 7 dogs. We are in state "SUCCESS".
Musimy odczytać każdą linijkę, wykonać parsowanie (np. 5, 7 i SUCCESS), Następnie pompuj te dane Do Kostki ( https://github.com/square/cube ) za pomocą klienta JS.
Po pierwsze, jaki jest kanoniczny sposób w węźle do odczytu w pliku, linia po linii?
Wydaje się, że to dość powszechne pytanie online:
- http://www.quora.com/What-is-the-best-way-to-read-a-file-line-by-line-in-node-js
- odczyt pliku po jednej linii na raz w węźle.js?
Wiele odpowiedzi wydaje się wskazywać na grupę osób trzecich Moduły:
- https://github.com/nickewing/line-reader
- https://github.com/jahewson/node-byline
- https://github.com/pkrumins/node-lazy
- https://github.com/Gagle/Node-BufferedReader
Jednak wydaje się to dość podstawowym zadaniem - z pewnością istnieje prosty sposób w stdlib, aby przeczytać w pliku tekstowym, linia po linii?
Po Drugie, muszę przetworzyć każdą linię (np. przekonwertować znacznik czasu do obiektu daty i wyodrębnij użyteczne pola).
Jaki jest najlepszy sposób, aby to zrobić, maksymalizując przepustowość? Czy jest jakiś sposób, który nie blokuje ani czytania w każdej linijce, ani wysyłania jej do sześcianu?
Po Trzecie-zgaduję, że używam stringów i odpowiednika js contains (IndexOf != -1?) będzie dużo szybszy niż wyrażenia regularne? Czy ktoś miał duże doświadczenie w parsowaniu ogromnych ilości danych tekstowych w węźle.js?
Pozdrawiam, Victor9 answers
Szukałem rozwiązania do parsowania bardzo dużych plików (gbs) linia po linii za pomocą strumienia. Wszystkie biblioteki i przykłady innych firm nie odpowiadały moim potrzebom, ponieważ przetwarzały pliki nie linia po linii (jak 1 , 2 , 3 , 4 ..) lub odczytać cały plik do pamięci
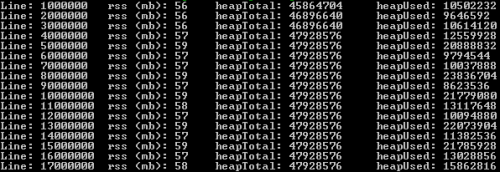
Poniższe rozwiązanie może analizować bardzo duże pliki, linia po linii za pomocą stream & pipe. Do testów użyłem pliku 2.1 gb z 17.000.000 rekordów. Zużycie pamięci Ram nie przekroczyło 60 mb.
var fs = require('fs')
, es = require('event-stream');
var lineNr = 0;
var s = fs.createReadStream('very-large-file.csv')
.pipe(es.split())
.pipe(es.mapSync(function(line){
// pause the readstream
s.pause();
lineNr += 1;
// process line here and call s.resume() when rdy
// function below was for logging memory usage
logMemoryUsage(lineNr);
// resume the readstream, possibly from a callback
s.resume();
})
.on('error', function(err){
console.log('Error while reading file.', err);
})
.on('end', function(){
console.log('Read entire file.')
})
);
Proszę pozwolić ja wiem jak to jest!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-01-19 20:49:56
Możesz użyć wbudowanego pakietu readline, Zobacz dokumenty TUTAJ . Używam stream Aby utworzyć nowy strumień wyjściowy.
var fs = require('fs'),
readline = require('readline'),
stream = require('stream');
var instream = fs.createReadStream('/path/to/file');
var outstream = new stream;
outstream.readable = true;
outstream.writable = true;
var rl = readline.createInterface({
input: instream,
output: outstream,
terminal: false
});
rl.on('line', function(line) {
console.log(line);
//Do your stuff ...
//Then write to outstream
rl.write(cubestuff);
});
Przetwarzanie dużych plików zajmie trochę czasu. Powiedz, czy to działa.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-04-15 10:44:50
Bardzo mi się spodobała@gerard odpowiedź, która w rzeczywistości zasługuje na poprawną odpowiedź tutaj. Zrobiłem kilka ulepszeń:
- kod jest w klasie (modułowej)
- parsowanie jest włączone
- możliwość wznowienia jest podana na zewnątrz w przypadku, gdy istnieje asynchroniczne zadanie jest przykuta do odczytu CSV jak wstawianie do DB, lub żądanie HTTP
- odczyt w kawałkach / rozmiarach batche, które użytkownik może zadeklarować. Zająłem się też kodowaniem w strumieniu, na wypadek masz pliki w inne kodowanie.
Oto kod:
'use strict'
const fs = require('fs'),
util = require('util'),
stream = require('stream'),
es = require('event-stream'),
parse = require("csv-parse"),
iconv = require('iconv-lite');
class CSVReader {
constructor(filename, batchSize, columns) {
this.reader = fs.createReadStream(filename).pipe(iconv.decodeStream('utf8'))
this.batchSize = batchSize || 1000
this.lineNumber = 0
this.data = []
this.parseOptions = {delimiter: '\t', columns: true, escape: '/', relax: true}
}
read(callback) {
this.reader
.pipe(es.split())
.pipe(es.mapSync(line => {
++this.lineNumber
parse(line, this.parseOptions, (err, d) => {
this.data.push(d[0])
})
if (this.lineNumber % this.batchSize === 0) {
callback(this.data)
}
})
.on('error', function(){
console.log('Error while reading file.')
})
.on('end', function(){
console.log('Read entirefile.')
}))
}
continue () {
this.data = []
this.reader.resume()
}
}
module.exports = CSVReader
Więc w zasadzie, oto jak będziesz go używać:
let reader = CSVReader('path_to_file.csv')
reader.read(() => reader.continue())
Przetestowałem to z plikiem CSV 35GB i zadziałało dla mnie i dlatego zdecydowałem się zbudować go na @gerard's odpowiedź, sprzężenia zwrotne są mile widziane.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:17:58
Użyłem https://www.npmjs.com/package/line-by-line do odczytu ponad 1 000 000 linii z pliku tekstowego. W tym przypadku zajmowana pojemność PAMIĘCI RAM wynosiła około 50-60 megabajtów.
const LineByLineReader = require('line-by-line'),
lr = new LineByLineReader('big_file.txt');
lr.on('error', function (err) {
// 'err' contains error object
});
lr.on('line', function (line) {
// pause emitting of lines...
lr.pause();
// ...do your asynchronous line processing..
setTimeout(function () {
// ...and continue emitting lines.
lr.resume();
}, 100);
});
lr.on('end', function () {
// All lines are read, file is closed now.
});
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-07-11 10:58:28
Oprócz odczytu dużego pliku linia po linii, można również odczytać go kawałek po kawałku. Więcej informacji można znaleźć w Ten artykuł
var offset = 0;
var chunkSize = 2048;
var chunkBuffer = new Buffer(chunkSize);
var fp = fs.openSync('filepath', 'r');
var bytesRead = 0;
while(bytesRead = fs.readSync(fp, chunkBuffer, 0, chunkSize, offset)) {
offset += bytesRead;
var str = chunkBuffer.slice(0, bytesRead).toString();
var arr = str.split('\n');
if(bytesRead = chunkSize) {
// the last item of the arr may be not a full line, leave it to the next chunk
offset -= arr.pop().length;
}
lines.push(arr);
}
console.log(lines);
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-09-28 08:42:11
Miałem jeszcze ten sam problem. Po porównaniu kilku modułów, które wydają się mieć tę funkcję, postanowiłem zrobić to sam, jest to prostsze niż myślałem.
Gist: https://gist.github.com/deemstone/8279565
var fetchBlock = lineByline(filepath, onEnd);
fetchBlock(function(lines, start){ ... }); //lines{array} start{int} lines[0] No.
Obejmuje Plik otwarty w zamkniÄ ™ ciu, ktĂłry fetchBlock() zwróci blok z pliku, end split to array (zajmie segment z ostatniego pobrania).
Ustawiłem rozmiar bloku na 1024 dla każdej operacji odczytu. To może mieć błędy, ale kod logika jest oczywista, spróbuj sam.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-01-06 08:26:22
Node-byline używa strumieni, więc wolałbym ten dla Twoich ogromnych plików.
Do konwersji na randki użyłbym chwili.js .
Aby zmaksymalizować przepustowość, można pomyśleć o użyciu klastra oprogramowania. istnieje kilka ładnych modułów, które całkiem dobrze zawijają macierzysty moduł klastra. Lubię Cluster-master z isaacs. na przykład można utworzyć klaster x workerów, które obliczają plik.
Do porównywania podziałów vs wyrażenia regularne użyj benchmark.js . nie testowałem go aż do teraz. benchmark.js jest dostępny jako node-module
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-04-15 10:49:06
Zrobiłem moduł węzła do odczytu dużych plików asynchronicznie tekst lub JSON. Testowane na dużych plikach.
var fs = require('fs')
, util = require('util')
, stream = require('stream')
, es = require('event-stream');
module.exports = FileReader;
function FileReader(){
}
FileReader.prototype.read = function(pathToFile, callback){
var returnTxt = '';
var s = fs.createReadStream(pathToFile)
.pipe(es.split())
.pipe(es.mapSync(function(line){
// pause the readstream
s.pause();
//console.log('reading line: '+line);
returnTxt += line;
// resume the readstream, possibly from a callback
s.resume();
})
.on('error', function(){
console.log('Error while reading file.');
})
.on('end', function(){
console.log('Read entire file.');
callback(returnTxt);
})
);
};
FileReader.prototype.readJSON = function(pathToFile, callback){
try{
this.read(pathToFile, function(txt){callback(JSON.parse(txt));});
}
catch(err){
throw new Error('json file is not valid! '+err.stack);
}
};
Po prostu zapisz plik jako file-reader.js, i używaj go tak:
var FileReader = require('./file-reader');
var fileReader = new FileReader();
fileReader.readJSON(__dirname + '/largeFile.json', function(jsonObj){/*callback logic here*/});
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-06-25 17:11:39
Na podstawie tej odpowiedzi na pytania zaimplementowałem klasę, której możesz użyć do odczytu pliku synchronicznie linia po linii z fs.readSync(). Możesz wykonać tę "pauzę" i "wznowienie", używając Q promise (jQuery wydaje się wymagać DOM, więc nie można go uruchomić z nodejs):
var fs = require('fs');
var Q = require('q');
var lr = new LineReader(filenameToLoad);
lr.open();
var promise;
workOnLine = function () {
var line = lr.readNextLine();
promise = complexLineTransformation(line).then(
function() {console.log('ok');workOnLine();},
function() {console.log('error');}
);
}
workOnLine();
complexLineTransformation = function (line) {
var deferred = Q.defer();
// ... async call goes here, in callback: deferred.resolve('done ok'); or deferred.reject(new Error(error));
return deferred.promise;
}
function LineReader (filename) {
this.moreLinesAvailable = true;
this.fd = undefined;
this.bufferSize = 1024*1024;
this.buffer = new Buffer(this.bufferSize);
this.leftOver = '';
this.read = undefined;
this.idxStart = undefined;
this.idx = undefined;
this.lineNumber = 0;
this._bundleOfLines = [];
this.open = function() {
this.fd = fs.openSync(filename, 'r');
};
this.readNextLine = function () {
if (this._bundleOfLines.length === 0) {
this._readNextBundleOfLines();
}
this.lineNumber++;
var lineToReturn = this._bundleOfLines[0];
this._bundleOfLines.splice(0, 1); // remove first element (pos, howmany)
return lineToReturn;
};
this.getLineNumber = function() {
return this.lineNumber;
};
this._readNextBundleOfLines = function() {
var line = "";
while ((this.read = fs.readSync(this.fd, this.buffer, 0, this.bufferSize, null)) !== 0) { // read next bytes until end of file
this.leftOver += this.buffer.toString('utf8', 0, this.read); // append to leftOver
this.idxStart = 0
while ((this.idx = this.leftOver.indexOf("\n", this.idxStart)) !== -1) { // as long as there is a newline-char in leftOver
line = this.leftOver.substring(this.idxStart, this.idx);
this._bundleOfLines.push(line);
this.idxStart = this.idx + 1;
}
this.leftOver = this.leftOver.substring(this.idxStart);
if (line !== "") {
break;
}
}
};
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-03-03 12:49:16