Ustawienie idealnego rozmiaru puli wątków [duplikat]
To pytanie ma już odpowiedź tutaj:
Jaka jest różnica pomiędzy-
newSingleThreadExecutor vs newFixedThreadPool(20)
Pod względem systemu operacyjnego i punktu widzenia programowania.
Kiedy uruchamiam mój program używając newSingleThreadExecutor Mój program działa bardzo dobrze i kończy się aby zakończyć opóźnienie (95. percentyl) przychodzi 5ms.
Ale jak tylko zacznę uruchamiać mój program używając-
newFixedThreadPool(20)
Moja wydajność programu pogarsza się i zaczynam widzieć opóźnienie od końca do końca jako 37ms.
Więc teraz staram się zrozumieć z punktu widzenia architektury, co oznacza liczba wątków tutaj? I jak zdecydować, jaka jest optymalna liczba wątków, które powinienem wybrać?
A jeśli używam większej liczby wątków to co się stanie?
Jeśli każdy może mi wyjaśnić te proste rzeczy w języku laika, to będzie bardzo przydatne dla mnie. Dzięki za pomoc.
My machine Config spec-uruchamiam mój program z Linux machine -
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 45
model name : Intel(R) Xeon(R) CPU E5-2670 0 @ 2.60GHz
stepping : 7
cpu MHz : 2599.999
cache size : 20480 KB
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology tsc_reliable nonstop_tsc aperfmperf pni pclmulqdq ssse3 cx16 sse4_1 sse4_2 popcnt aes hypervisor lahf_lm arat pln pts
bogomips : 5199.99
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 45
model name : Intel(R) Xeon(R) CPU E5-2670 0 @ 2.60GHz
stepping : 7
cpu MHz : 2599.999
cache size : 20480 KB
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology tsc_reliable nonstop_tsc aperfmperf pni pclmulqdq ssse3 cx16 sse4_1 sse4_2 popcnt aes hypervisor lahf_lm arat pln pts
bogomips : 5199.99
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
3 answers
Ok. Najlepiej zakładając, że twoje wątki nie mają blokowania tak, że nie blokują się nawzajem (niezależnie od siebie) i można założyć, że obciążenie robocze (przetwarzanie) jest takie samo, to okazuje się, że, mają rozmiar puli Runtime.getRuntime().availableProcessors() lub availableProcessors() + 1 daje najlepsze wyniki.
Ale powiedzmy, że jeśli wątki kolidują ze sobą lub mają wbudowane we / wy, to prawo Amadhala wyjaśnia całkiem dobrze. Z wiki,
Prawo Amdahla mówi, że jeśli P jest proporcją programu, który może być (1-P) jest proporcją, która nie może być równoległa (pozostaje szeregowa), wtedy maksymalne przyspieszenie, które można osiągnąć przy użyciu N procesorów jest
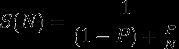
W Twoim przypadku, w oparciu o liczbę dostępnych rdzeni i jaką pracę dokładnie wykonują (czyste obliczenia? I / O? zamki? zablokowany dla jakiegoś zasobu? itd..), musisz wymyślić rozwiązanie oparte na powyższych parametrach.
Na przykład: kilka miesięcy z powrotem byłem zaangażowany w zbieranie danych z numerycznych stron internetowych. Moja maszyna była 4-rdzeniowa i miałem rozmiar puli 4. Ale ponieważ operacja była czysto I/O i moja prędkość netto była przyzwoita, zdałem sobie sprawę, że miałem najlepszą wydajność przy wielkości puli 7. A to dlatego, że wątki nie walczyły o moc obliczeniową, ale o I / O. więc mogłem wykorzystać fakt, że więcej wątków może konkurować o core pozytywnie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-04-21 06:25:43
Więc teraz staram się zrozumieć z punktu widzenia architektury, co oznacza liczba wątków tutaj?
Każdy wątek ma własną pamięć stosu, licznik programu (jak wskaźnik do instrukcji wykonywanej dalej) i inne lokalne zasoby. Zamiana ich powoduje opóźnienie na jedno zadanie. Zaletą jest to, że podczas gdy jeden wątek jest bezczynny (zwykle podczas oczekiwania na wejście/wyjście), inny wątek może wykonać pracę. Również jeśli dostępnych jest wiele procesorów, mogą działać w równoległe, jeśli nie ma zasobów i / lub blokowania sporów między zadaniami.
I jak zdecydować, jaka jest optymalna liczba wątków, które powinienem wybrać?
Kompromis między ceną wymiany a możliwością uniknięcia czasu bezczynności zależy od drobnych szczegółów na temat tego, jak wygląda twoje zadanie (ile i/O, i kiedy, z jaką ilością pracy między i/o, zużywając ile pamięci do wykonania). Eksperymentowanie jest zawsze kluczem.
I jeśli używam większej liczby wątków to co się stanie?
Zazwyczaj następuje liniowy wzrost przepustowości, następnie względna płaska część, a następnie spadek (który może być dość stromy). Każdy system jest inny.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-04-21 06:17:06
Patrząc na prawo Amdahla jest w porządku, zwłaszcza jeśli dokładnie wiesz, jak duże są P i N. Ponieważ tak się nigdy nie stanie, możesz monitorować wydajność (co i tak powinieneś zrobić) i zwiększyć / zmniejszyć rozmiar puli wątków, aby zoptymalizować wskaźniki wydajności, które są dla Ciebie ważne.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-04-21 21:48:09