jaka jest różnica między Supersalingiem a pipeliningiem?
Dobrze wygląda zbyt proste pytanie, aby zadać, ale zadałem po przejściu przez kilka PPT na obu.
Obie metody zwiększają przepustowość instrukcji. A Supersaling prawie zawsze wykorzystuje również pipelining. Supersaling ma więcej niż jedną jednostkę wykonawczą i tak samo pipelining czy się mylę?
5 answers
Superscalar design polega na tym, że procesor może wydawać wiele instrukcji w jednym zegarze, z nadmiarowymi urządzeniami do wykonywania instrukcji. Mówimy o jednym rdzeniu, proszę pamiętać -- przetwarzanie wielordzeniowe jest inne.
Pipelining dzieli instrukcję na kroki, a ponieważ każdy krok jest wykonywany w innej części procesora, wiele instrukcji może być w różnych" fazach " każdego zegara.
Są prawie zawsze używane razem. Ten obraz z Wikipedii pokazuje oba pojęcia w użyciu, ponieważ pojęcia te są najlepiej wyjaśnione graficznie: {]}
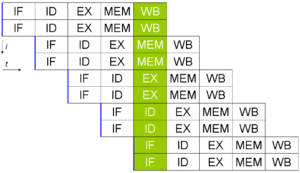
Tutaj dwie instrukcje są wykonywane jednocześnie w pięciostopniowym potoku.
Aby jeszcze bardziej to rozłożyć, biorąc pod uwagę twoją ostatnią edycję:
W powyższym przykładzie Instrukcja przechodzi przez 5 etapów do "wykonania". Są to IF (Instrukcja fetch), ID (Instrukcja decode), EX (execute), MEM (update memory), WB (writeback to cache).
W bardzo prostej konstrukcji procesora każdy zegar byłby zakończony innym etapem, więc mielibyśmy:
- IF
- ID
- EX
- MEM
- WB
Który zrobiłby jedną instrukcję na pięć zegarów. Jeśli dodamy nadmiarową jednostkę wykonawczą i wprowadzimy projekt supersalarowy, otrzymamy to, dla dwóch instrukcji A i B:
- IF(A) IF(B)
- ID (A) ID (B)
- EX (A) EX (B)
- MEM (A) MEM (B)
- WB(A) WB(B)
Dwie instrukcje w pięciu zegarach -- teoretyczny maksymalny zysk 100%.
Pipelining pozwala na jednoczesne wykonywanie części, więc kończymy na czymś takim (dla dziesięciu instrukcji od A do J):
- IF(A) IF(B)
- ID (A) ID (B) IF (C) IF (D)
- EX(A) EX(B) ID(C) ID(D) IF(E) IF (F)
- MEM(A) MEM(B) EX(C) EX(D) ID(E) ID(F) IF(G) IF (H)
- WB(A) WB(B) MEM(C) MEM(D) EX (E) EX (F) ID (G) ID(H) IF(I) IF (J)
- WB(C) WB(D) MEM(E) MEM(F) EX(G) EX(H) ID(I) ID (J)
- WB (E) WB(F) MEM(G) MEM(H) EX(I) EX (J)
- WB (G) WB (H) MEM(I) MEM(J)
- WB(I) WB (J)
W dziewięciu zegarach, wykonaliśmy dziesięć instrukcji -- można zobaczyć, gdzie pipelining naprawdę porusza rzeczy wzdłuż. I to jest wyjaśnienie przykładowej grafiki, a nie jak jest ona faktycznie zaimplementowana w polu (czyli czarna magia ).
Artykuły Wikipedii Dla Superscalar i instruction pipeline {[78] } są całkiem niezłe.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-02-08 14:16:46
Dawno temu, Procesory wykonywały tylko jedną instrukcję maszynową na raz . Dopiero po jej zakończeniu procesor pobierał następną instrukcję z pamięci (lub później z pamięci podręcznej instrukcji).
W końcu ktoś zauważył, że oznacza to, że większość procesorów nie robi nic przez większość czasu, ponieważ było kilka podjednostek wykonawczych (takich jak dekoder instrukcji, Jednostka arytmetyczna integer, Jednostka arytmetyczna FP, itp.) i wykonanie instrukcji przechowywanej tylko jeden z nich jest zajęty na raz.
Tak więc " proste" pipelining narodził się: gdy jedna instrukcja została dekodowana i poszła w kierunku następnej podjednostki wykonawczej, dlaczego nie pobrać i dekodować następnej instrukcji? Jeśli masz 10 takich " etapów ", to przez posiadanie każdego etapu procesu innej instrukcji teoretycznie możesz zwiększyć przepustowość instrukcji dziesięciokrotnie bez zwiększania zegara procesora w ogóle! Oczywiście działa to tylko bezbłędnie gdy w kodzie nie ma skoków warunkowych (spowodowało to wiele dodatkowego wysiłku, aby obsłużyć skoki warunkowe specjalnie).
Później, gdy prawo Moore ' a nadal było poprawne dłużej niż oczekiwano, twórcy procesorów znaleźli się z coraz większą liczbą tranzystorów do wykorzystania i pomyśleli: "dlaczego mają tylko jedną z każdej podjednostki wykonawczej?". W ten sposób powstały superscalar procesory z wieloma podjednostkami wykonawczymi zdolnymi do wykonywania tego samego równolegle, a projekty procesorów stały się o wiele bardziej skomplikowane jest rozprowadzanie instrukcji pomiędzy tymi w pełni równoległymi jednostkami, przy jednoczesnym zapewnieniu, że wyniki będą takie same, jak gdyby instrukcje były wykonywane sekwencyjnie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-12-28 16:25:22
Analogia: Pranie Odzieży
Wyobraź sobie Sklep z pralnią chemiczną z następującymi udogodnieniami: stojak do powieszenia brudnych lub czystych ubrań, pralka i suszarka (z których każda może wyprać jedną Odzież na raz), Składany Stół i deska do prasowania.
Opiekun, który wykonuje wszystkie rzeczywiste pranie i suszenie, jest raczej tępy, więc właściciel sklepu, który przyjmuje zlecenia pralni chemicznej, dokłada szczególnej staranności, aby napisać każdą instrukcję bardzo starannie i wyraźnie.
W typowym dniu te instrukcje mogą być czymś w rodzaju:
- weź koszulę ze stojaka
- pranie koszulki
- wytrzyj koszulę
- wyprasuj koszulę
- złóż koszulę
- załóż koszulę z powrotem na stelaż
- wyjmij spodnie ze stojaka
- myj spodnie
- wytrzyj spodnie
- fold the pants
- włóż spodnie z powrotem na stelaż
- weź płaszcz z rack
- umyj płaszcz
- wysuszyć płaszcz
- iron the coat
- połóż płaszcz z powrotem na wieszaku
Obsługa postępuje zgodnie z tymi instrukcjami, będąc bardzo ostrożnym, aby nigdy nie zrobić niczego niezgodnego z porządkiem. Jak można sobie wyobrazić, zajmuje dużo czasu, aby zrobić pranie w ciągu dnia, ponieważ zajmuje dużo czasu, aby w pełni umyć, wysuszyć i złożyć każdy kawałek prania, a to wszystko musi być wykonane po jednym na raz.
Jednak pewnego dnia opiekun odchodzi i zatrudniany JEST NOWY, mądrzejszy pracownik, który zauważa, że większość sprzętu leży bezczynnie w danym momencie w ciągu dnia. Podczas suszenia spodni ani deska do prasowania, ani pralka nie były używane. Postanowił więc lepiej wykorzystać swój czas. Tak więc, zamiast powyższej serii kroków, zrobiłby to:
- weź koszulę ze stojaka
- wyprać koszulę, wyjmij spodnie ze stojaka
- wysuszyć koszulę, wyprać spodnie
- wyprasuj koszulę, wysusz spodnie
- złóż koszulę, (weź płaszcz ze stojaka)
- załóż koszulę z powrotem na stelaż, złóż spodnie, (umyć płaszcz)
- włóż spodnie z powrotem na stelaż, (wysusz płaszcz)
- (prasować płaszcz)
- (połóż płaszcz z powrotem na wieszaku)
To jest pipelining. sekwencjonowanie niepowiązane działania takie, że używają różnych komponentów w tym samym czasie. Utrzymując jednocześnie jak najwięcej różnych komponentów, maksymalizujesz wydajność i przyspieszasz czas realizacji, w tym przypadku redukując 16 "cykli" do 9, co przyspiesza o ponad 40%.
Teraz mała Pralnia zaczęła zarabiać więcej pieniędzy, ponieważ mogły pracować o wiele szybciej, więc właściciel kupił dodatkową pralkę, suszarkę, deskę do prasowania, składaną stację, a nawet zatrudnił innego pracownika. Teraz wszystko jest jeszcze szybsze, zamiast powyższego masz:
- wyjmij koszulę ze stojaka, wyjmij spodnie ze stojaka
- wyprać koszulę, wyprać spodnie, (weź płaszcz ze stojaka)
- wysuszyć koszulę, wysuszyć spodnie, (umyć płaszcz)
- wyprasuj koszulę, złóż spodnie, (wysusz płaszcz)
- złóż koszulę, włóż spodnie z powrotem na stelaż, (iron the płaszcz)
- włóż koszulę z powrotem na stelaż, (włóż płaszcz z powrotem na stelaż)
To jest supersalarowy projekt. wiele podzespołów zdolnych do wykonywania tego samego zadania jednocześnie, ale z procesorem decydującym o tym, jak to zrobić. W tym przypadku spowodowało to zwiększenie prędkości o prawie 50% (W 18 "cyklach" nowa architektura mogła przebiegać przez 3 iteracje tego "programu", podczas gdy poprzednia Architektura mogła przebiegać tylko przez 2).
Starsze procesory, takie jak 386 lub 486, są prostymi procesorami skalarnymi, wykonują jedną instrukcję na raz w dokładnie takiej kolejności, w jakiej została otrzymana. Nowoczesne procesory konsumenckie od PowerPC / Pentium są pipelined i superscalar. Procesor Core2 jest w stanie uruchomić ten sam kod, który został skompilowany dla 486, jednocześnie korzystając z równoległości na poziomie instrukcji, ponieważ zawiera własną wewnętrzną logikę, która analizuje kod maszynowy i określa, jak zmienić kolejność i uruchomić go (co może być Uruchom równolegle, co nie może, itp.) To jest istota supersalar design i dlaczego jest tak praktyczny.
W przeciwieństwie do wektorowego procesora równoległego wykonuje operacje na kilku fragmentach danych naraz (wektor). Tak więc, zamiast tylko dodawać x i y, procesor wektorowy dodałby, powiedzmy, x0,x1, x2 do y0,y1, y2 (co daje z0,z1,z2). Problem z tą konstrukcją polega na tym, że jest ona ściśle powiązana z określonym stopniem równoległości procesora. Jeśli uruchomisz kod skalarny na wektorze procesor (zakładając, że możesz) nie zauważysz żadnej korzyści z równoległości wektorowej, ponieważ musi być ona wyraźnie używana, podobnie jeśli chcesz skorzystać z nowszego procesora wektorowego z większą liczbą jednostek przetwarzania równoległego (np. zdolnego do dodawania wektorów o 12 liczbach zamiast tylko 3), musisz przekompilować swój kod. Projekty procesorów wektorowych były popularne w najstarszej generacji super komputerów, ponieważ były łatwe w projektowaniu i istnieją duże klasy problemów w Nauka i inżynieria z dużą ilością naturalnego paralelizmu.
Procesory Supersalarne mogą również mieć możliwość wykonywania zleceń spekulacyjnych. Zamiast pozostawiać jednostki Przetwarzające bezczynne i czekać na ścieżkę kodu, która zakończy wykonywanie przed rozgałęzieniem procesora, może najlepiej odgadnąć i rozpocząć wykonywanie kodu poza gałęzią, zanim poprzedni kod zakończy przetwarzanie. Gdy wykonanie wcześniejszego kodu dociera do punktu rozgałęzienia, procesor może następnie porównać rzeczywistą gałąź z odgadnięciem gałęzi i albo Kontynuuj, czy odgadnięcie było poprawne (już wcześniej, gdzie byłoby po prostu czekając), albo może unieważnić wyniki spekulatywnego wykonania i uruchomić kod dla poprawnej gałęzi.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-12-11 10:07:42
Pipelining jest tym, co firma samochodowa robi w produkcji swoich samochodów. Rozkładają proces układania samochodu w etapy i wykonują różne etapy w różnych punktach wzdłuż linii montażowej wykonanej przez różnych ludzi. Wynik netto jest taki, że samochód jest produkowany dokładnie z prędkością najwolniejszego etapu.
W procesorach proces pipelining jest dokładnie taki sam. "Instrukcja" dzieli się na różne etapy wykonania, zwykle coś jak 1. instrukcja pobierania, 2. pobiera operandy (odczytywane rejestry lub wartości pamięci), 2. wykonywanie obliczeń, 3. zapis wyników (do pamięci lub rejestrów). Najwolniejszą z nich może być część obliczeniowa, w którym to przypadku ogólna prędkość przepustowości instrukcji w tym potoku jest tylko prędkością części obliczeniowej (tak jakby pozostałe części były "wolne".)
Super-Skalar w mikroprocesorach odnosi się do możliwości uruchamiania kilku instrukcji z jednego strumienia wykonawczego na raz równolegle. Więc jeśli firma samochodowa prowadziła dwie linie montażowe, to oczywiście mogłaby wyprodukować dwa razy więcej samochodów. Ale jeśli proces umieszczania numeru seryjnego na samochodzie był na ostatnim etapie i musiał być wykonany przez jedną osobę, to musieliby oni na przemian między dwoma rurociągami i zagwarantować, że będą mogli zrobić każdy z nich w połowie czasu najwolniejszego etapu, aby uniknąć stawania się najwolniejszym etapem.
Super-Skalar w mikroprocesorach jest podobny, ale zwykle ma znacznie więcej ograniczeń. Tak więc etap pobierania Instrukcji zazwyczaj wytwarza więcej niż jedną instrukcję podczas swojego etapu-to sprawia, że super-Skalar w mikroprocesorach jest możliwy. Następnie będą dwa etapy pobierania, dwa etapy wykonywania i dwa etapy odpisywania. To oczywiście uogólnia się na więcej niż tylko dwa rurociągi.
To wszystko jest w porządku i elegancko, ale z perspektywy dźwięku wykonanie obu technik może prowadzić do problemów, jeśli zrobi się to na ślepo. Dla poprawnego wykonanie programu, zakłada się, że instrukcje są wykonywane w całości jeden po drugim w kolejności. Jeśli dwie sekwencyjne instrukcje mają wzajemnie zależne obliczenia lub używają tych samych rejestrów, to może wystąpić problem, późniejsza instrukcja musi poczekać na odpis poprzedniej instrukcji, zanim będzie mogła wykonać etap pobierania operandu. Dlatego musisz przeciągnąć drugą instrukcję o dwa etapy, zanim zostanie wykonana, co podważa cel tego, co było / align = "left" /
Istnieje wiele technik stosowanych w celu zmniejszenia problemu konieczności przeciągania, które są nieco skomplikowane do opisania, ale wymienię je: 1. register forwarding, (również przechowywać, aby załadować forwarding) 2. register renaming, 3. punktacja-4. wykonanie poza zleceniem. 5. Spekulatywne wykonywanie z wycofaniem (i wycofaniem) wszystkie nowoczesne procesory używają prawie wszystkich tych technik, aby zaimplementować super-Skalar i pipelining. Jednak techniki te mają tendencję aby mieć malejące zyski w odniesieniu do liczby potoków w procesorze, zanim stragany staną się nieuniknione. W praktyce żaden producent procesora nie wykonuje więcej niż 4 potoki w jednym rdzeniu.
Multi-core nie ma nic wspólnego z żadną z tych technik. Jest to w zasadzie taranowanie dwóch mikroprocesorów w celu zaimplementowania symetrycznego wieloprocesora na jednym chipie i dzielenie się tylko tymi komponentami, które mają sens współdzielenie (zazwyczaj L3 cache i I/O). Jednak technika, która Intel nazywa "hyperthreading" jest metodą prób Wirtualnego zaimplementowania semantyki wielordzeniowej w ramach superskalarnej struktury pojedynczego rdzenia. Tak więc pojedyncza mikroarchitektura zawiera rejestry dwóch (lub więcej) wirtualnych rdzeni i pobiera instrukcje z dwóch (lub więcej) różnych strumieni wykonawczych, ale wykonujących ze wspólnego systemu superskalarnego. Chodzi o to, że ponieważ rejestry nie mogą się ze sobą kolidować, będzie mieć tendencję do większej równoległości, co doprowadzi do mniejszej liczby straganów. Tak więc zamiast po prostu wykonywać dwa wirtualne strumienie wykonawcze z prędkością o połowę mniejszą, jest to lepsze ze względu na ogólną redukcję straganów. Wydaje się to sugerować, że Intel może zwiększyć liczbę rurociągów. Jednak okazało się, że technika ta jest nieco brakuje w praktycznych implementacjach. Ponieważ jest integralną częścią technik superskalarnych, i tak o tym wspomniałem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-11-01 09:22:37
Pipelining to jednoczesne wykonywanie różnych etapów wielu instrukcji w tym samym cyklu. Opiera się na podziale przetwarzania instrukcji na etapy i posiadaniu wyspecjalizowanych jednostek dla każdego etapu oraz rejestrów do przechowywania wyników pośrednich.
Supersaling jest wysyłaniem wielu instrukcji (lub mikroinstrukcji) do wielu jednostek wykonawczych istniejących w CPU. Opiera się więc na redundantnych jednostkach w CPU.
Oczywiście podejście to może uzupełniać każdą inne.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-11-01 07:44:02