Różnica między HBase a Hadoop/HDFS
To trochę naiwne pytanie, ale jestem nowy w paradygmacie NoSQL i niewiele o nim wiem. Więc jeśli ktoś może mi pomóc jasno zrozumieć różnicę między HBase i Hadoop lub jeśli podać kilka wskazówek, które mogą pomóc mi zrozumieć różnicę.
Do tej pory, zrobiłem kilka badań i acc. według mnie Hadoop dostarcza framework do pracy z surowymi fragmentami danych (plików) w HDFS i HBase jest silnikiem bazy danych powyżej Hadoop, który w zasadzie działa z danymi strukturalnymi zamiast surowy fragment danych. Hbase zapewnia warstwę logiczną nad HDFS, tak jak robi to SQL. Czy to prawda?
Pls prosimy o poprawienie mnie.
Dzięki.5 answers
Hadoop to w zasadzie 3 rzeczy, FS (Hadoop Distributed File System), Framework obliczeniowy (MapReduce) i Most zarządzania (Yet Another Resource Negotiator). HDFS pozwala przechowywać ogromne ilości danych w sposób rozproszony (zapewnia szybszy dostęp do odczytu/zapisu) i nadmiarowy (zapewnia lepszą dostępność). A MapReduce pozwala przetwarzać te ogromne dane w sposób rozproszony i równoległy. Ale MapReduce nie ogranicza się tylko do HDFS. Jako FS, HDFS nie ma losowego odczytu/zapisu możliwości. Jest to dobre dla sekwencyjnego dostępu do danych. I tu pojawia się HBase. Jest to baza danych NoSQL, która działa na Twoim klastrze Hadoop i zapewnia losowy dostęp do odczytu/zapisu danych w czasie rzeczywistym.
Możesz przechowywać zarówno dane strukturalne, jak i niestrukturalne w Hadoop, a także HBase. Oba zapewniają wiele mechanizmów dostępu do danych, takich jak powłoka i inne API. HBase przechowuje dane jako pary klucz/wartość w sposób kolumnowy, podczas gdy HDFS przechowuje dane jako płaskie akta. Niektóre z najważniejszych cech obu systemów to:
Hadoop
- zoptymalizowany do strumieniowego dostępu do dużych plików.
- podąża za ideologią zapisu-raz przeczytania-wielu.
- nie obsługuje losowego odczytu/zapisu.
HBase
- przechowuje pary klucz / wartość w sposób kolumnowy(kolumny są połączone razem jako rodziny kolumn).
- zapewnia dostęp o niskim opóźnieniu do małych ilości danych z dużych danych gotowi.
- zapewnia elastyczny model danych.
Hadoop jest najbardziej odpowiedni do przetwarzania wsadowego offline, podczas gdy HBase jest używany, gdy masz potrzeby w czasie rzeczywistym.
Analogiczne porównanie byłoby między MySQL i Ext4.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-04-19 07:10:13
Apache Hadoop projekt zawiera cztery kluczowe Moduły
- Hadoop Common : wspólne narzędzia obsługujące inne moduły Hadoop.
- Hadoop Distributed File System (HDFS™): rozproszony system plików, który zapewnia dostęp do danych aplikacji o dużej przepustowości.
- Hadoop YARN : framework do planowania zadań i zarządzania zasobami klastra.
- Hadoop MapReduce: a YARN - oparty na systemie równoległym przetwarzanie dużych zbiorów danych.
HBase {[8] } jest skalowalną, rozproszoną bazą danych, która obsługuje strukturyzowane przechowywanie danych dla dużych tabel. Podobnie jak Bigtable wykorzystuje rozproszony magazyn danych dostarczany przez system plików Google, Apache HBase zapewnia funkcje podobne do Bigtable na bazie Hadoop i HDFS.
kiedy stosować HBase:
- Jeśli aplikacja ma schemat zmiennej, gdzie każdy wiersz jest nieco inny
- Jeśli znajdziesz, że Twoje dane są przechowywane w kolekcjach, które są oznaczone tą samą wartością
- jeśli potrzebujesz losowego dostępu do odczytu/zapisu w czasie rzeczywistym do swoich dużych danych.
- jeśli potrzebujesz dostępu do danych w oparciu o klucze podczas przechowywania lub pobierania.
- Jeśli posiadasz ogromną ilość danych z istniejącym klastrem Hadoop
Ale HBase ma pewne ograniczenia
- nie może być używany do klasycznych aplikacji transakcyjnych lub nawet analityki relacyjnej.
- to również nie jest kompletny substytut HDFS podczas wykonywania dużych map wsadowych.
- nie mówi po SQL, ma optymalizator, obsługuje transakcje krzyżowe rekordów lub łączy.
- nie może być używany ze skomplikowanymi wzorcami dostępu (np. złączeniami)
Podsumowanie:
Rozważ HBase, gdy wczytywasz dane według klucza, przeszukiwasz dane według klucza (lub zakresu), obsługujesz dane według klucza, odpytywasz dane według klucza lub gdy przechowujesz dane według wiersza, który nie jest dobrze zgodny z schemat.
Zajrzyj do 'S and Don' t of HBase zcloudera blog.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-05-31 20:29:45
Hadoop używa rozproszonego systemu plików tj. HDFS do przechowywania bigdata.Istnieją jednak pewne ograniczenia HDFS i aby je przezwyciężyć,powstały bazy danych NoSQL,takie jak HBase,Cassandra i Mongodb.
Hadoop może wykonywać tylko przetwarzanie wsadowe, a dane będą dostępne tylko w sposób sekwencyjny. Oznacza to, że trzeba przeszukiwać cały zbiór danych nawet dla najprostszych zadań.Ogromny zbiór danych po przetworzeniu skutkuje kolejnym ogromnym zbiorem danych, który również powinien być przetwarzane kolejno. W tym momencie potrzebne jest nowe rozwiązanie, aby uzyskać dostęp do dowolnego punktu danych w jednej jednostce czasu (dostęp losowy).
Podobnie jak wszystkie inne systemy plików, HDFS zapewnia nam pamięć masową, ale w sposób odporny na błędy, z dużą przepustowością i mniejszym ryzykiem utraty danych (z powodu replikacji).Ale , jako System plików, HDFS nie ma losowego dostępu do odczytu i zapisu. Tutaj pojawia się HBase. Jest to rozproszony, skalowalny, duży magazyn danych, wzorowany na BigTable Google. Cassandra jest nieco podobna do hbase.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-11-23 05:08:27
Zarówno HBase jak i HDFS na jednym zdjęciu

Uwaga:
Sprawdź demony HDFS (zaznaczone na Zielono) jak DataNode(serwery regionu kolokowanego) i NameNode w klastrze z have both HBase and Hadoop HDFS
HDFS jest rozproszonym systemem plików, który doskonale nadaje się do przechowywania dużych plików. który nie zapewnia szybkiego wyszukiwania pojedynczych rekordów w plikach.
HBase , na z drugiej strony, jest zbudowany na bazie HDFS i zapewnia szybkie wyszukiwanie rekordów (i aktualizacje) dla dużych tabel. Czasami może to być punkt pojęciowego zamętu. HBase wewnętrznie umieszcza twoje dane w zindeksowanych "plikach magazynowych", które istnieją na HDFS w celu szybkiego wyszukiwania.
Jak to wygląda?Cóż, na poziomie infrastruktury, każda maszyna salve w klastrze ma następujące demony]}
- Region Server-HBase
- Węzeł Danych - HDFS
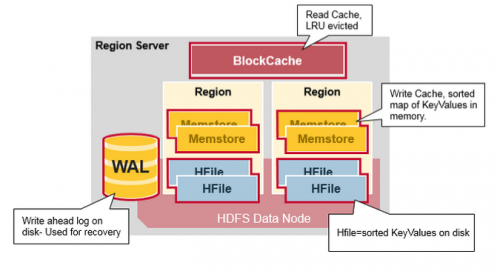
HBase umożliwia szybkie wyszukiwanie plików HDFS (czasami również innych rozproszonych systemów plików) jako podstawowej pamięci masowej, używając następującego modelu danychJak to jest szybko z lookup?
-
Tabela
- tabela HBase składa się z wielu wierszy.
-
Wiersz
- wiersz w HBase składa się z klucza wiersza i jednej lub więcej kolumn z wartościami z nimi związanymi. Wiersze są sortowane alfabetycznie według klucza wiersza. Z tego powodu konstrukcja klucza wiersza jest bardzo ważna. Celem jest przechowywanie danych w taki sposób, aby Powiązane wiersze znajdowały się blisko siebie. Wspólny wzór klucza wiersza to domena internetowa. Jeśli Twoje klucze wiersza są domenami, prawdopodobnie powinieneś przechowywać je w odwrotnej kolejności (org.Apacz.www, org.Apacz.poczta, org.Apacz.jira). W ten sposób wszystkie domeny Apache są blisko siebie w tabeli, a nie są rozłożone na podstawie pierwszej litery subdomena.
-
Kolumna
- kolumna w HBase składa się z rodziny kolumn i kwalifikatora kolumn, które są oddzielone znakiem : (dwukropek).
-
Rodzina Kolumn
- rodziny kolumn fizycznie kolokują zestaw kolumn i ich wartości, często ze względów wydajnościowych. Każda rodzina kolumn ma zestaw właściwości przechowywania, takich jak to, czy jej wartości powinny być buforowane w pamięci, jak jej dane są kompresowane lub wiersz klucze są zakodowane, i inne. Każdy wiersz w tabeli ma te same rodziny kolumn, chociaż dany wiersz może nie przechowywać niczego w danej rodzinie kolumn.
-
Kwalifikator Kolumn
- kwalifikator kolumn jest dodawany do rodziny kolumn, aby zapewnić indeks dla danego fragmentu danych. Biorąc pod uwagę zawartość rodziny kolumn, kwalifikatorem kolumn może być content: html, a innym może być content: pdf. Chociaż rodziny kolumn są stałe przy tworzeniu tabeli, kwalifikatory kolumn są zmienny i może się znacznie różnić między rzędami.
-
Komórka
- komórka jest kombinacją wierszy, rodziny kolumn i kwalifikatora kolumn i zawiera wartość oraz znacznik czasu, który reprezentuje wersję wartości.
-
Timestamp
- znacznik czasu jest zapisywany obok każdej wartości i jest identyfikatorem dla danej wersji wartości. Domyślnie znacznik czasu reprezentuje czas na serwerze regionu, kiedy dane zostały zapisane, możesz jednak określić inną wartość znacznika czasu podczas umieszczania danych w komórce.
Client read request flow:
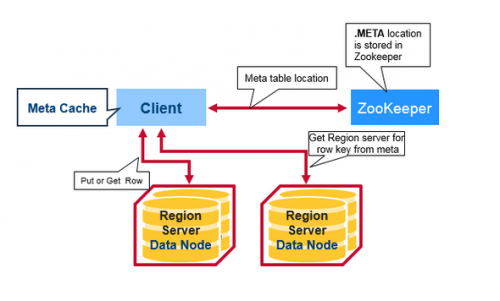
Czym jest tabela meta na powyższym obrazku?
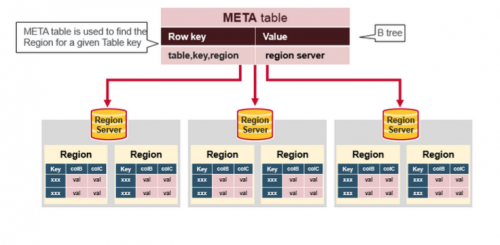
Po wszystkich informacji, HBase read flow jest dla lookup dotyka tych encji
- najpierw skaner szuka komórek wiersza w Block cache - pamięci podręcznej odczytu. Ostatnio Odczytany Klucz Wartości są tu buforowane, a ostatnio używane są usuwane, gdy potrzebna jest pamięć.
- następnie skaner zagląda do MemStore , pamięci podręcznej zapisu w pamięci zawierającej najnowsze zapisy.
- jeśli skaner nie znajdzie wszystkich komórek wiersza w MemStore i Block Cache, to HBase użyje indeksów Block Cache i filtrów bloom do załadowania plików HFiles do pamięci, która może zawierać docelowe komórki wiersza.
Źródła i więcej informacji:
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-09-14 07:24:13
Odniesienie: http://www.quora.com/What-is-the-difference-between-HBASE-and-HDFS-in-Hadoop
Hadoop to ogólna nazwa kilku podsystemów: 1) HDFS. Rozproszony system plików, który dystrybuuje dane w klastrze maszyn dbających o redundancję itp 2) Zmniejszenie Mapy. System zarządzania zadaniami na HDFS-do zarządzania mapami-redukuje (i inne typy) zadania przetwarzające dane przechowywane na HDFS.
Zasadniczo oznacza to system offline-przechowujesz dane na HDFS i możesz go przetworzyć, uruchamiając zadania.
HBase z drugiej strony w bazie danych opartej na kolumnach. Używa HDFS jako pamięci masowej-która zajmuje się backup\redundency\etc, ale jest to "sklep internetowy" - co oznacza, że możesz odpytywać go o konkretny wiersz \ rows itp i uzyskać natychmiastową wartość.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-02-01 00:27:22