Scala 2.8 collections design tutorial
Kontynuując moje beztechne zamieszanie , jakie są dobre zasoby, które wyjaśniają, w jaki sposób Nowa Scala 2.8 uporządkowano bibliotekę zbiorów. Jestem zainteresowany, aby znaleźć kilka informacji na temat tego, jak następujące pasują do siebie:
- same klasy/cechy kolekcji (np.
List,Iterable) - dlaczego istnieją podobne do klasy (np.
TraversableLike) - do czego służą metody towarzyszące (np.
List.companion) - Skąd wiem co
implicitobiekty są w zasięgu w danym punkcie
1 answers
Przedmowa
Jest 2.8 Collection walk-through autorstwa Martina Odersky ' ego, która prawdopodobnie powinna być twoją pierwszą referencją. Został on również uzupełniony o notatki architektoniczne , które będą szczególnie interesujące dla tych, którzy chcą zaprojektować własne kolekcje.
Reszta odpowiedzi została napisana na długo przed pojawieniem się czegoś takiego (w rzeczywistości, przed wydaniem samej wersji 2.8.0).
Możesz znaleźć pracę na ten temat jako Scala SID #3 . Inne prace z tej dziedziny powinny być interesujące również dla osób zainteresowanych różnicami między scalą 2.7 i 2.8.
Cytuję z gazety, wybiórczo, i uzupełniam kilka moich przemyśleń. Są też zdjęcia, wygenerowane przez Matthiasa w decodified.com, a oryginalne pliki SVG można znaleźć tutaj .
Same klasy/cechy kolekcji
Istnieją właściwie trzy hierarchie cech dla zbiorów: jeden dla zbiorów zmiennych, jeden dla zbiorów niezmiennych i jeden, który nie przyjmuje żadnych założeń na temat zbiorów.
Istnieje również rozróżnienie między kolekcjami równoległymi, szeregowymi i być może-równoległymi, które zostało wprowadzone w Scali 2.9. Opowiem o nich w następnej sekcji. Hierarchia opisana w tej sekcji odnosi się wyłącznie do zbiorów nie-równoległych .
Poniższy obrazek pokazuje niespecyficzną hierarchię wprowadzono Scala 2.8:
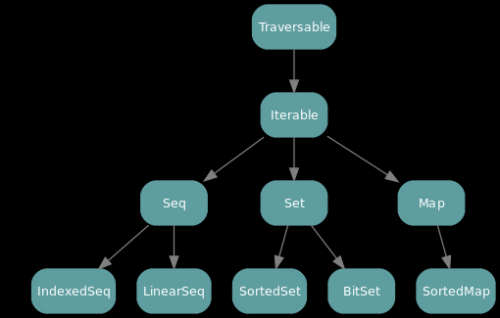
Wszystkie pokazane elementy są cechami. W pozostałych dwóch hierarchiach istnieją również klasy bezpośrednio dziedziczące cechy, jak również klasy, które mogą być postrzegane jako należące do tej hierarchii poprzez niejawną konwersję do klas wrappera. Legenda tych wykresów znajduje się po nich.
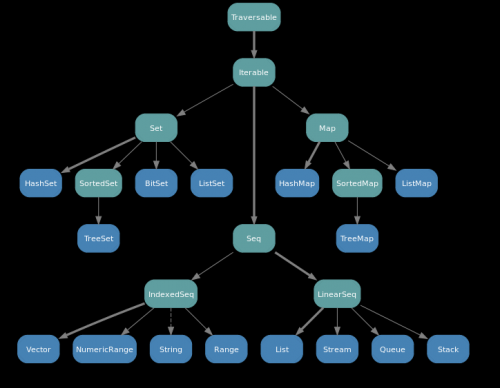
Wykres niezmiennej hierarchii:
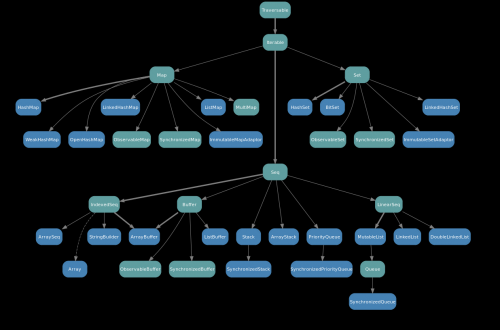
Wykres dla mutable hierarchia:
Legenda:
Oto skrócony ASCII opis hierarchii kolekcji, dla tych, którzy nie widzą obrazów.
Traversable
|
|
Iterable
|
+------------------+--------------------+
Map Set Seq
| | |
| +----+----+ +-----+------+
Sorted Map SortedSet BitSet Buffer Vector LinearSeq
Zbiory Równoległe
Kiedy Scala 2.9 wprowadziła Kolekcje równoległe, jednym z celów projektowych było jak najbardziej bezproblemowe ich wykorzystanie. Najprościej mówiąc, można zastąpić zbiór Nie-równoległy (szeregowy) na równoległy i natychmiast zebrać korzyści.
Ponieważ wszystkie zbiory do tego czasu były seryjne, wiele algorytmów wykorzystujących je zakładało i zależało od tego, żebyły seryjne. Zbiory równoległe do metod z takimi założeniami byłyby nieudane. Z tego powodu cała hierarchia opisana w poprzedniej sekcji nakazuje seryjne przetwarzanie.
Stworzono dwie nowe hierarchie wspierające zbiory równoległe.
Hierarchia zbiorów równoległych ma te same nazwy dla cech, ale poprzedzone Par: ParIterable, ParSeq, ParMap i ParSet. Zauważ, że nie ma ParTraversable, ponieważ każda kolekcja wspierająca dostęp równoległy jest w stanie wspierać mocniejszą cechę ParIterable. Nie ma też niektórych bardziej wyspecjalizowanych cech obecnych w hierarchii szeregowej. Cała ta hierarchia znajduje się w katalogu scala.collection.parallel.
Klasy implementujące zbiory równoległe również różnią się między sobą, z ParHashMap i ParHashSet zarówno dla zmiennych, jak i niezmiennych zbiory równoległe, plus ParRange i ParVector implementacja immutable.ParSeq i ParArray implementacja mutable.ParSeq.
Istnieje również inna hierarchia, która odzwierciedla cechy zbiorów szeregowych i równoległych, ale z przedrostkiem Gen: GenTraversable, GenIterable, GenSeq, GenMap i GenSet. Te cechy są rodzicami zarówno dla zbiorów równoległych, jak i szeregowych. Oznacza to, że metoda przyjmująca {[24] } nie może otrzymać zbioru równoległego, ale oczekuje się, że metoda przyjmująca GenSeq będzie działać z obydwoma szeregami i zbiorów równoległych.
Biorąc pod uwagę sposób struktury tych hierarchii, kod napisany dla Scali 2.8 był w pełni zgodny ze Scali 2.9 i wymagał zachowania szeregowego. Bez przepisania nie może korzystać ze zbiorów równoległych, ale wymagane zmiany są bardzo małe.
Używanie Zbiorów Równoległych
Dowolna kolekcja może być przekonwertowana do równoległej przez wywołanie na niej metody par. Podobnie każdy zbiór można przekształcić w szeregowy przez wywołanie na nim metody seq.
Jeśli zbiór był już typu wymaganego (równoległy lub szeregowy), nie nastąpi żadna konwersja. Jeśli wywołamy {[27] } na kolekcji równoległej lub par na kolekcji szeregowej, wygenerowana zostanie nowa kolekcja o wymaganej charakterystyce.
Nie należy mylić seq, który zamienia zbiór w zbiór Nie-równoległy, z toSeq, który zwraca Seq utworzony z elementów kolekcja. Wywołanie toSeq NA kolekcji równoległej zwróci ParSeq, a nie zbiór szeregowy.
Główne Cechy
Podczas gdy istnieje wiele klas implementujących i podkategorii, istnieją pewne podstawowe cechy w hierarchii, z których każda dostarcza więcej metod lub bardziej szczegółowych gwarancji, ale zmniejsza liczbę klas, które mogłyby je zaimplementować.
W poniższych podrozdziałach podam Krótki opis głównych cech i idei stojącej za oni.
Trait TraversableOnce
Ta cecha jest bardzo podobna do opisanej poniżej cechy, ale z tym ograniczeniem, że można jej użyć tylko raz . Czyli wszelkie metody wywoływane na TraversableOnce może sprawić, że stanie się bezużyteczny.
To ograniczenie umożliwia współdzielenie tych samych metod pomiędzy zbiorami i Iterator. Dzięki temu możliwe jest, aby metoda, która działa z Iterator, ale nie używa metod specyficznych dla Iterator być w stanie pracować z dowolną kolekcją, plus iteratorami, jeśli zostanie przepisany na accept TraversableOnce.
Ponieważ TraversableOnce unifikuje zbiory i Iteratory, nie pojawia się na poprzednich wykresach, które dotyczą tylko zbiorów.
Trait Traversable
Na górzezbioru hierarchia jest cecha Traversable. Jej jedynym abstrakcyjnym działaniem jest
def foreach[U](f: Elem => U)
Operacja ma na celu przemieszczenie wszystkich elementów zbioru i zastosowanie dana operacja f do każdego element. Aplikacja jest wykonywana tylko dla jej efektu ubocznego; w rzeczywistości każdy wynik funkcji f jest odrzucany przez foreach.
Obiekty mogą być skończone lub nieskończone. Przykładem obiektu nieskończonego jest strumień
liczb naturalnych Stream.from(0). Metoda hasDefiniteSize wskazuje, czy zbiór jest możliwy
nieskończona. Jeśli hasDefiniteSize zwróci true, zbiór jest z pewnością skończony. Jeśli zwróci false,
kolekcja nie została jeszcze w pełni opracowana, więc może być nieskończona lub skończona.
Ta klasa definiuje metody, które mogą być efektywnie zaimplementowane w kategoriach foreach (ponad 40 z nich).
Cecha Iterable
Ta cecha deklaruje abstrakcyjną metodę iterator, która zwraca iterator, który daje wszystkie elementy zbioru jeden po drugim. Metoda foreach w Iterable jest zaimplementowana w kategoriach iterator. Podklasy Iterable często zastępują foreach za pomocą bezpośredniej implementacji dla wydajności.
Klasa Iterable dodaje również kilka rzadziej używanych metod do Traversable, które mogą być efektywnie zaimplementowane tylko wtedy, gdy dostępna jest iterator. Są one podsumowane poniżej.
xs.iterator An iterator that yields every element in xs, in the same order as foreach traverses elements.
xs takeRight n A collection consisting of the last n elements of xs (or, some arbitrary n elements, if no order is defined).
xs dropRight n The rest of the collection except xs takeRight n.
xs sameElements ys A test whether xs and ys contain the same elements in the same order
Inne Cechy
Po Iterable pojawiają się trzy podstawowe cechy, które dziedziczą po nim: Seq, Set, i Map. Wszystkie trzy mają metodę apply i wszystkie trzy implementują cechę PartialFunction, ale znaczenie apply jest różne w każdym przypadku.
Ufam znaczeniu Seq, Set i Map jest intuicyjne. Po nich klasy rozpadają się w konkretne implementacje, które oferują szczególne gwarancje pod względem wydajności i metod, które w wyniku tego udostępniają. Dostępne są również niektóre cechy z dalszymi udoskonaleniami, takie jak LinearSeq, IndexedSeq i SortedSet.
Poniższy wykaz może zostać poprawiony. Zostaw komentarz z sugestiami, a ja to naprawię.
Podstawowe klasy i cechy
-
Traversable-- podstawowa klasa kolekcji. Może być zaimplementowane tylko za pomocąforeach.-
TraversableProxy-- Proxy dlaTraversable. Po prostu wskażselfna prawdziwy zbiór. -
TraversableView-- przemierzanie za pomocą pewnych nieostrych metod. -
TraversableForwarder-- przekazuje większość metod dounderlying, z wyjątkiemtoString,hashCode,equals,stringPrefix,newBuilder,viewi wszystkie wywołania tworzące nowy iterowalny obiekt tego samego rodzaju. -
mutable.Traversableiimmutable.Traversable-- to samo coTraversable, ale ograniczenie typu zbioru. - inne przypadki specjalne
Iterableklasy, takie jakMetaData, istnieją. -
Iterable-- zbiór, dla którego można utworzyćIterator(poprzeziterator).-
IterableProxy,IterableView,mutableiimmutable.Iterable.
-
-
-
Iterator-- cecha, która nie jest potomkiemTraversable. ZdefiniujnextihasNext.-
CountedIterator-- anIteratordefiniowaniecount, które zwraca elementy widoczne do tej pory. -
BufferedIterator-- definiujehead, który zwraca następny element bez konsumowania to. - istnieją inne klasy specjalne
Iterator, takie jakSource.
-
Mapy
-
Map-- AnIterableofTuple2, który dostarcza również metod pobierania wartości (drugiego elementu krotki) podanego klucza (pierwszego elementu krotki). RozszerzaPartialFunctionrównież.-
MapProxy-- AProxydla aMap. -
DefaultMap-- cecha implementująca niektóre abstrakcyjne metodyMap. -
SortedMap-- AMapktórego klucze są posortowane.-
immutable.SortMap-
immutable.TreeMap-- Klasa implementującaimmutable.SortedMap.
-
-
-
immutable.Mapimmutable.MapProxy-
immutable.HashMap-- Klasa implementującaimmutable.Mappoprzez hashowanie kluczy. -
immutable.IntMap-- Klasa implementującaimmutable.Mapwyspecjalizowana dlaIntkluczy. Używa drzewa opartego na binarnych cyfrach kluczy. -
immutable.ListMap-- Klasa implementującaimmutable.Mappoprzez listy. -
immutable.LongMap-- Klasa implementującaimmutable.Mapwyspecjalizowana dlaLongkluczy. ZobaczIntMap. - istnieją dodatkowe klasy zoptymalizowane dla określonej liczby elementów.
-
mutable.Map-
mutable.HashMap-- Klasa implementującamutable.Mappoprzez hashowanie kluczy. -
mutable.ImmutableMapAdaptor-- Klasa implementująca amutable.Mapz istniejącegoimmutable.Map. -
mutable.LinkedHashMap-- ? -
mutable.ListMap-- Klasa implementującamutable.Mappoprzez listy. -
mutable.MultiMap-- Klasa akceptowanie więcej niż jednej odrębnej wartości dla każdego klucza. -
mutable.ObservableMap-- a mixin , który po zmieszaniu zMap, publikuje zdarzenia dla obserwatorów poprzez interfejsPublisher. -
mutable.OpenHashMap-- Klasa oparta na otwartym algorytmie hashującym. -
mutable.SynchronizedMap-- a mixin który powinien być zmieszany zMap, aby zapewnić jego wersję z metodami zsynchronizowanymi. -
mutable.MapProxy.
-
-
The Sekwencje
-
Seq-- Sekwencja elementów. Zakłada się dobrze zdefiniowaną wielkość i powtarzalność elementów. RozszerzaPartialFunctionrównież.-
IndexedSeq-- sekwencje obsługujące dostęp do elementu O(1) i obliczanie długości o(1).IndexedSeqView-
immutable.PagedSeq-- implementacjaIndexedSeqgdzie elementy są wytwarzane na żądanie przez funkcję przekazywaną przez konstruktor. -
immutable.IndexedSeq-
immutable.Range-- rozgraniczony ciąg liczb całkowitych, zamknięte na dolnym końcu, otwarte na górnym końcu i z krokiem.-
immutable.Range.Inclusive-- ARangerównież zamknięte na high Endzie. -
immutable.Range.ByOne-- aRangektórego stopień wynosi 1.
-
-
immutable.NumericRange-- bardziej ogólna wersjaRange, która działa z dowolnymIntegral.-
immutable.NumericRange.Inclusive,immutable.NumericRange.Exclusive. -
immutable.WrappedString,immutable.RichString-- Wrappery, które umożliwiają postrzeganieStringjakoSeq[Char], przy jednoczesnym zachowaniu metodString. Nie wiem, co za różnica. między nimi jest.
-
-
-
mutable.IndexedSeq-
mutable.GenericArray-- struktura podobna do tablicy. Zauważ, że "class"ArrayjestArrayJavy, która jest bardziej metodą przechowywania pamięci niż klasą. -
mutable.ResizableArray-- Klasa wewnętrzna używana przez klasy bazujące na tablicach z możliwością zmiany rozmiaru. -
mutable.PriorityQueue,mutable.SynchronizedPriorityQueue-- klasy implementujące kolejki priorytetowe -- kolejki, w których elementy są usuwane zgodnie zOrderingpierwszy, i kolejność kolejkowania ostatni. -
mutable.PriorityQueueProxy-- streszczenieProxydlaPriorityQueue.
-
-
LinearSeq-- cecha dla sekwencji liniowych, z efektywnym czasem dlaisEmpty,headitail.-
immutable.LinearSeq-
immutable.List-- niezmienna, jednoliniowa implementacja listy. -
immutable.Stream-- leniwa lista. Jego elementy są obliczane tylko na żądanie, ale później zapisywane w pamięci. Może to być teoretycznie nieskończona.
-
-
mutable.LinearSeq-
mutable.DoublyLinkedList-- lista z możliwością zmianyprev,head(elem) oraztail(next). -
mutable.LinkedList-- lista z możliwością zmianyhead(elem) oraztail(next). -
mutable.MutableList-- Klasa używana wewnętrznie do implementacji klas opartych na zmiennych listach.-
mutable.Queue,mutable.QueueProxy-- struktura danych zoptymalizowana pod kątem operacji FIFO (Pierwsze wejście, Pierwsze Wyjście). -
mutable.QueueProxy-- AProxydlamutable.Queue.
-
-
-
-
SeqProxy,SeqView,SeqForwarder -
immutable.Seq-
immutable.Queue-- Klasa implementująca strukturę danych zoptymalizowaną pod kątem FIFO (Pierwsze wejście, Pierwsze Wyjście). Nie ma wspólnej superklasy zarównomutable, jak iimmutablekolejek. -
immutable.Stack-- Klasa implementująca strukturę danych zoptymalizowaną pod kątem LIFO. Nie ma wspólnej superklasy obumutableimmutablestosy. -
immutable.Vector-- ? -
scala.xml.NodeSeq-- wyspecjalizowana Klasa XML, która rozszerzaimmutable.Seq. -
immutable.IndexedSeq-- jak widać powyżej. -
immutable.LinearSeq-- jak widać powyżej.
-
-
mutable.ArrayStack-- Klasa implementująca strukturę danych zoptymalizowaną LIFO przy użyciu tablic. Podobno znacznie szybciej niż normalny stos. -
mutable.Stack,mutable.SynchronizedStack-- klasy implementujące strukturę danych zoptymalizowaną pod kątem LIFO. -
mutable.StackProxy-- AProxydlamutable.Stack.. -
mutable.Seq-
mutable.Buffer-- Sekwencja elementów, które mogą być zmieniane przez dodawanie, dodawanie lub wstawianie nowych członków.-
mutable.ArrayBuffer-- Implementacja klasymutable.Buffer, ze stałym czasem amortyzacji dla operacji dodawania, aktualizacji i dostępu losowego. Posiada kilka wyspecjalizowanych podklas, takich jakNodeBuffer. -
mutable.BufferProxy,mutable.SynchronizedBuffer. -
mutable.ListBuffer-- bufor wspierany listą. Zapewnia stały czas dodawania i poprzedzania, przy czym większość pozostałe operacje są liniowe. -
mutable.ObservableBuffer-- a Mixin cecha, która po zmieszaniu zBuffer, dostarcza zdarzenia powiadomień poprzezPublisherinterfejsy. -
mutable.IndexedSeq-- jak widać powyżej. -
mutable.LinearSeq-- jak widać powyżej.
-
-
-
Zestawy
-
Set-- zbiór jest zbiorem, który zawiera co najwyżej jeden z dowolnego obiektu.-
BitSet-- zbiór liczb całkowitych przechowywanych jako bitset.immutable.BitSetmutable.BitSet
-
SortedSet-- zbiór, którego elementy są uporządkowane.-
immutable.SortedSet-
immutable.TreeSet-- implementacjaSortedSetoparta na drzewie.
-
-
-
SetProxy-- AProxydla aSet. -
immutable.Set-
immutable.HashSet-- implementacjaSetoparta na hashowaniu elementów. -
immutable.ListSet-- implementacjaSetoparta na listy. - istnieją dodatkowe klasy set, które zapewniają zoptymalizowane implementacje dla zestawów od 0 do 4 elementów.
-
immutable.SetProxy-- AProxydla niezmiennegoSet.
-
-
mutable.Set-
mutable.HashSet-- implementacjaSetoparta na hashowaniu elementów. -
mutable.ImmutableSetAdaptor-- Klasa implementująca zmiennySetZ niezmiennegoSet. -
LinkedHashSet-- implementacjaSetna podstawie list. -
ObservableSet-- A Mixin cecha, która po zmieszaniu zSet, dostarcza zdarzenia powiadomień poprzez interfejsPublisher. -
SetProxy-- AProxydla aSet. -
SynchronizedSet-- a Mixin cecha, która po zmieszaniu zSet, dostarcza zdarzenia powiadomień poprzez interfejsPublisher.
-
-
- dlaczego podobne klasy istnieją (np. TraversableLike)
Zostało to zrobione w celu osiągnięcia maksymalnego ponownego użycia kodu. Konkretna implementacja generic dla klas o określonej strukturze (możliwość przejścia, Mapa itp.) jest wykonywana w podobnych klasach. Klasy przeznaczone do ogólnego użytku zastępują wybrane metody, które mogą być optmizowane.
- do czego służą metody towarzyszące (np. List.towarzysz)
Konstruktor klas, czyli obiekt, który wie, jak tworzyć instancje tej klasy w sposób, który może być używany przez metody takie jak map, jest utworzony metodą w obiekcie towarzyszącym. Tak więc, aby zbudować obiekt typu X, muszę pobrać ten konstruktor z obiektu towarzyszącego X. niestety, w Scali nie ma sposobu, aby dostać się z klasy X do obiektu X. Z tego powodu w każdej instancji X jest zdefiniowana metoda companion, która zwraca obiekt towarzyszący klasy X.
Chociaż może być zastosowanie takiej metody w normalnych programach, jej celem jest umożliwienie ponownego użycia kodu w kolekcji biblioteka.
- Skąd wiem, jakie obiekty ukryte są w zasięgu w danym punkcie
Te niejawne wartości istnieją, aby umożliwić definiowanie metod na kolekcjach na klasach nadrzędnych, ale nadal zwracają kolekcję tego samego typu. Na przykład, metoda map jest zdefiniowana na TraversableLike, ale jeśli użyłeś na List otrzymasz List z powrotem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-12-02 18:08:40