NOT in vs NOT EXISTS
Które z tych zapytań jest szybsze?
NIE ISTNIEJE:
SELECT ProductID, ProductName
FROM Northwind..Products p
WHERE NOT EXISTS (
SELECT 1
FROM Northwind..[Order Details] od
WHERE p.ProductId = od.ProductId)
Lub nie w:
SELECT ProductID, ProductName
FROM Northwind..Products p
WHERE p.ProductID NOT IN (
SELECT ProductID
FROM Northwind..[Order Details])
Plan wykonywania zapytań mówi, że obie robią to samo. Jeśli tak jest, która forma jest zalecana?
Bazuje na bazie danych NorthWind.[edytuj]
Właśnie znalazłem ten pomocny artykuł: http://weblogs.sqlteam.com/mladenp/archive/2007/05/18/60210.aspx
Myślę, że zostanę przy nie istnieje.
10 answers
Zawsze domyślam się NOT EXISTS.
Plany wykonania mogą być w tej chwili takie same, ale jeśli któraś z kolumn zostanie zmieniona w przyszłości, aby umożliwić NULLS, wersja NOT IN będzie musiała wykonać więcej pracy (nawet jeśli żadne NULLs nie są faktycznie obecne w danych) i semantyka NOT IN Jeśli NULLS są obecne, jest mało prawdopodobne, aby były te, które i tak chcesz.
Gdy ani Products.ProductID ani [Order Details].ProductID nie pozwolą NULL s NOT IN będą traktowane identycznie jak zapytanie.
SELECT ProductID,
ProductName
FROM Products p
WHERE NOT EXISTS (SELECT *
FROM [Order Details] od
WHERE p.ProductId = od.ProductId)
Dokładny plan może się różnić, ale dla moich przykładowych danych dostaję następujące.
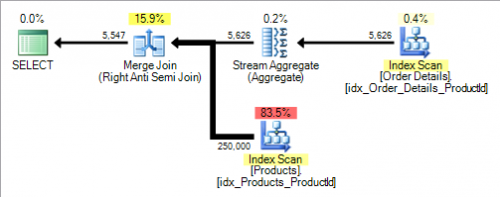
Dość powszechnym błędem wydaje się być to, że skorelowane zapytania podrzędne są zawsze "złe" w porównaniu z połączeniami. Z pewnością mogą być, gdy wymuszają Plan zagnieżdżonej pętli (sub query evaluated row by row), ale plan ten zawiera operatora logicznego anty semi join. Złącza Anti semi nie są ograniczone do zagnieżdżonych pętli, ale mogą używać łączenia hash lub merge (jak w tym przykładzie) też.
/*Not valid syntax but better reflects the plan*/
SELECT p.ProductID,
p.ProductName
FROM Products p
LEFT ANTI SEMI JOIN [Order Details] od
ON p.ProductId = od.ProductId
If [Order Details].ProductID is NULL - able the query then becomes
SELECT ProductID,
ProductName
FROM Products p
WHERE NOT EXISTS (SELECT *
FROM [Order Details] od
WHERE p.ProductId = od.ProductId)
AND NOT EXISTS (SELECT *
FROM [Order Details]
WHERE ProductId IS NULL)
Powodem tego jest to, że poprawna semantyka jeśli [Order Details] zawiera jakiekolwiek NULL ProductIds oznacza, że nie zwraca żadnych wyników. Zobacz dodatkową szpulę Anti semi join i liczbę wierszy, aby sprawdzić, czy jest ona dodana do planu.
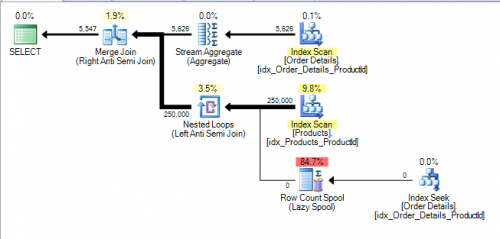
Jeśli Products.ProductID jest również zmieniona na NULL - able zapytanie staje się
SELECT ProductID,
ProductName
FROM Products p
WHERE NOT EXISTS (SELECT *
FROM [Order Details] od
WHERE p.ProductId = od.ProductId)
AND NOT EXISTS (SELECT *
FROM [Order Details]
WHERE ProductId IS NULL)
AND NOT EXISTS (SELECT *
FROM (SELECT TOP 1 *
FROM [Order Details]) S
WHERE p.ProductID IS NULL)
Powodem tego jest to, że NULL Products.ProductId nie należy zwracać w wyniki z wyjątkiem , jeśli podzapytanie NOT IN nie zwraca żadnych wyników (tzn. tabela [Order Details] jest pusta). W takim razie powinno. W planie dla moich danych przykładowych jest to realizowane przez dodanie innego anty semi join jak poniżej.
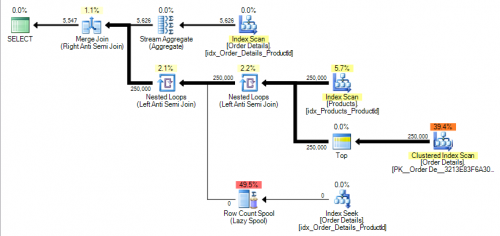
Efekt tego jest pokazany wblogu już linkowane przez Buckley . W przykładzie Liczba odczytów logicznych wzrasta z około 400 do 500 000.
Dodatkowo fakt, że pojedynczy NULL może zmniejszenie liczby wierszy do zera sprawia, że oszacowanie kardynalności jest bardzo trudne. Jeśli SQL Server zakłada, że tak się stanie, ale w rzeczywistości nie było NULL wierszy w danych, reszta planu wykonania może być katastrofalnie gorsza, jeśli jest to tylko część większego zapytania, z nieodpowiednimi zagnieżdżonymi pętlami powodującymi powtarzające się wykonywanie drogiego drzewa podrzędnego, na przykład.
Nie jest to jednak jedyny możliwy plan wykonania NOT IN na kolumnie NULL-able. to artykuł pokazuje inny dla zapytania z bazy danych AdventureWorks2008.
Dla NOT IN na kolumnie NOT NULL lub NOT EXISTS przeciwko kolumnie nullable lub non nullable daje następujący plan.
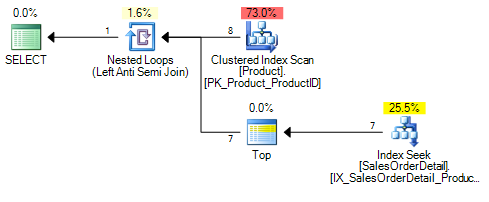
Gdy kolumna zmieni się na NULL - able NOT IN plan wygląda teraz następująco
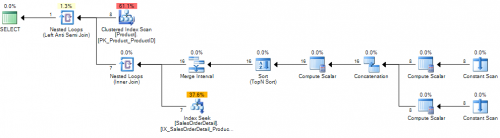
Dodaje dodatkowy operator połączenia wewnętrznego do planu. Aparat ten jest wyjaśnione tutaj . To wszystko jest po to, aby przekonwertować poprzedni jeden skorelowany indeks seek on Sales.SalesOrderDetail.ProductID = <correlated_product_id> to two seeks per outer row. Dodatkowy jest na WHERE Sales.SalesOrderDetail.ProductID IS NULL.
Ponieważ jest to pod anty semi join jeśli ten zwraca dowolne wiersze, drugie wyszukiwanie nie wystąpi. Jeśli jednak Sales.SalesOrderDetail nie zawiera żadnych NULL ProductIDs to podwoi liczbę wymaganych operacji wyszukiwania.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-04-13 12:42:36
Należy również pamiętać, że NOT IN nie jest równoznaczne z NOT EXISTS jeśli chodzi o null.
Ten post wyjaśnia to bardzo dobrze
Http://sqlinthewild.co.za/index.php/2010/02/18/not-exists-vs-not-in/
Gdy zapytanie podrzędne zwróci nawet jedno null, NOT IN nie będzie pasować do żadnego rzędy.
Przyczyny tego można znaleźć, patrząc na szczegóły tego, co Nie działa właściwie oznacza.
Powiedzmy, dla celów ilustracyjnych, że są 4 rzędy w w tabeli o nazwie t znajduje się kolumna o nazwie ID o wartości 1..4
WHERE SomeValue NOT IN (SELECT AVal FROM t)Jest równoważne
WHERE SomeValue != (SELECT AVal FROM t WHERE ID=1) AND SomeValue != (SELECT AVal FROM t WHERE ID=2) AND SomeValue != (SELECT AVal FROM t WHERE ID=3) AND SomeValue != (SELECT AVal FROM t WHERE ID=4)Powiedzmy, że AVal jest NULL, gdzie ID = 4. Stąd != porównanie zwraca nieznany. Tabela prawdy logicznej dla i stanowi to nieznane i prawdziwe jest nieznane, nieznane i fałszywe jest fałszywe. Jest nie ma wartości, która może być I ' d z UNKNOWN, aby uzyskać wynik TRUE
Stąd, Jeśli jakikolwiek wiersz tego zapytania podrzędnego zwróci NULL, Cała NIE W operator będzie oceniał na FALSE lub NULL i żadne rekordy nie będą Return
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-06-12 12:39:48
Jeśli planer egzekucji mówi, że są takie same, to są takie same. Użyj tego, który sprawi, że Twój zamiar będzie bardziej oczywisty-w tym przypadku, drugi.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-10-06 02:21:46
Faktycznie, to chyba najszybsze:
SELECT ProductID, ProductName
FROM Northwind..Products p
outer join Northwind..[Order Details] od on p.ProductId = od.ProductId)
WHERE od.ProductId is null
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-10-06 02:40:33
Mam tabelę, która ma około 120 000 rekordów i muszę wybrać tylko te, które nie istnieją (dopasowane do kolumny varchar) w czterech innych tabelach z liczbą wierszy około 1500, 4000, 40000, 200. Wszystkie tabele mają unikalny indeks w danej kolumnie Varchar.
NOT IN zajęło około 10 minut, NOT EXISTS zajęło 4 sekundy.
Mam rekursywne zapytanie, które może mieć jakiś untuned sekcja, która może przyczynić się do 10 min, ale druga opcja zajmuje 4 sek wyjaśnia, przynajmniej dla mnie, że NOT EXISTS jest o wiele lepszy, a przynajmniej to, że IN i EXISTS nie są dokładnie takie same i zawsze warto sprawdzić, zanim przejdziesz do przodu z kodem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-02-12 08:41:02
W twoim konkretnym przykładzie są one takie same, ponieważ optymalizator zorientował się, że to, co próbujesz zrobić, jest takie samo w obu przykładach. Ale jest możliwe, że w nietrywialnych przykładach optymalizator może tego nie robić, a w takim przypadku istnieją powody, aby czasami preferować jeden od drugiego.
NOT IN powinno być preferowane, jeśli testujesz wiele wierszy w zewnętrznym select. Zapytanie podrzędne wewnątrz NOT IN może być oceniane na początku wykonania, a tymczasowe tabela może być sprawdzana pod kątem każdej wartości w zewnętrznym select, zamiast każdorazowo ponownie uruchamiać zaznaczenie podrzędne, tak jak byłoby to wymagane za pomocą instrukcji NOT EXISTS.
Jeśli zapytanie podrzędne musi być skorelowane z zewnętrznym select, to NOT EXISTS może być preferowane, ponieważ optymalizator może odkryć uproszczenie, które uniemożliwia tworzenie tymczasowych tabel do wykonywania tej samej funkcji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-10-02 11:48:09
Używałem
SELECT * from TABLE1 WHERE Col1 NOT IN (SELECT Col1 FROM TABLE2)
I okazało się, że daje złe wyniki(przez złe mam na myśli żadnych wyników). Jak było NULL w tabeli 2./ Colspan = 1 /
Podczas Zmiany zapytania na
SELECT * from TABLE1 T1 WHERE NOT EXISTS (SELECT Col1 FROM TABLE2 T2 WHERE T1.Col1 = T2.Col2)
Dał mi prawidłowe wyniki.
Od tego czasu zacząłem używać NOT EXISTS every where.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-06-13 15:02:31
Są bardzo podobne, ale nie do końca takie same.
Jeśli chodzi o wydajność, odkryłem, że Left join jest null twierdzenie bardziej efektywne (gdy ma być zaznaczona liczba wierszy, czyli)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-03-19 08:27:30
Jeśli optymalizator mówi, że są takie same, rozważ czynnik ludzki. Wolę zobaczyć, że nie istnieje:)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-10-06 07:57:08
To zależy..
SELECT x.col
FROM big_table x
WHERE x.key IN( SELECT key FROM really_big_table );
Nie byłoby stosunkowo powolne, nie ma zbyt wiele, aby ograniczyć rozmiar tego, co sprawdza zapytanie, aby sprawdzić, czy klucz jest w. Istnieje byłoby korzystne w tym przypadku.
Ale, w zależności od optymalizatora DBMS, nie może być inaczej.
Jako przykład kiedy istnieje jest lepiej
SELECT x.col
FROM big_table x
WHERE EXISTS( SELECT key FROM really_big_table WHERE key = x.key);
AND id = very_limiting_criteria
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-10-06 02:32:34