Czy można porównywać jednostki SSE / AVX z rdzeniami GPU?
Mam prezentację dla osób, które nie mają (prawie) pojęcia jak działa GPU. Myślę, że powiedzenie, że GPU ma tysiąc rdzeni, gdzie procesor ma tylko cztery do ośmiu z nich, jest bez sensu. Ale chcę dać moim odbiorcom element porównania.
Po kilku miesiącach pracy z architekturami NVidia Kepler i AMD GCN, kusi mnie porównanie GPU "core" do CPU SIMD ALU (Nie wiem, czy mają na to nazwę w Intelu). Czy to sprawiedliwe ? W końcu, patrząc na poziom montażu, te modele programowania mają wiele wspólnego (przynajmniej z GCN, spójrz na p2-6 instrukcji ISA).
Ten artykuł stwierdza, że procesor Haswell może wykonać 32 operacje z pojedynczą precyzją na cykl, ale przypuszczam, że zdarza się pipelining lub inne rzeczy, aby osiągnąć tę szybkość. w języku Nvidii, ileCuda-rdzeni ma ten procesor ? powiedziałbym, że 8 na CPU-core dla 32 bitów operacji, ale to tylko zgadywanie na podstawie szerokości SIMD.
Oczywiście jest wiele innych rzeczy, które należy wziąć pod uwagę przy porównywaniu sprzętu CPU i GPU, ale nie to próbuję zrobić. Muszę tylko wyjaśnić, jak to działa.
PS: wszystkie wskaźniki do CPU dokumentacji sprzętu lub prezentacji CPU/GPU są bardzo mile widziane !
EDIT: Dzięki za odpowiedzi, niestety musiałam wybrać tylko jedną z nich. Zaznaczyłem Igora odpowiedź {[12] } ponieważ najbardziej pasuje do mojego początkowego pytania i dała mi wystarczająco dużo informacji, aby uzasadnić, dlaczego to porównanie nie powinno być posuwane za daleko, ale CaptainObvious dostarczył bardzo dobre artykuły .
4 answers
Bardzo luźno mówiąc, nie jest całkowicie nierozsądne stwierdzenie, że rdzeń Haswell ma około 16 rdzeni CUDA, ale zdecydowanie nie chcesz posuwać się za daleko tego porównania. Możesz być ostrożny w podejmowaniu tego Oświadczenia bezpośrednio w prezentacji, ale uznałem, że przydatne jest myślenie o rdzeniu CUDA jako nieco związanym z skalarną jednostką FP.
Może pomóc, jeśli wyjaśnię, dlaczego Haswell może wykonać 32 operacje z pojedynczą precyzją na cykl.
8 operacje z pojedynczą precyzją wykonywane są w każdej instrukcji AVX/AVX2. Podczas pisania kodu, który będzie działał na procesorze Haswell, możesz użyć instrukcji AVX i AVX2, które działają na 256-bitowych wektorach. Te 256-bitowe wektory mogą reprezentować 8 liczb FP z pojedynczą precyzją, 8 liczb całkowitych (32-bitowych) lub 4 liczby FP z podwójną precyzją.
2 instrukcje AVX / AVX2 mogą być wykonywane w każdym rdzeniu na cykl, chociaż istnieją pewne ograniczenia, które mogą być sparowane.
A fused Instrukcja multiply add (FMA) technicznie wykonuje 2 operacje z pojedynczą precyzją. Instrukcje FMA wykonują operacje "zespolone", takie jak A = A * B + C, więc są prawdopodobnie dwie operacje na operand skalarny: mnożenie i dodawanie.
Ten artykuł wyjaśnia powyższe punkty bardziej szczegółowo: http://www.realworldtech.com/haswell-cpu/4/
W księgowości ogólnej Rdzeń Haswella może wykonywać 8 * 2 * 2 operacje z pojedynczą precyzją na cykl. Od CUDA rdzenie obsługują również operacje FMA, nie można policzyć tego współczynnika 2 podczas porównywania rdzeni CUDA do rdzeni Haswell.
Jądro Keplera CUDA ma jedną jednostkę zmiennoprzecinkową o pojedynczej precyzji, więc może wykonywać jedną operację zmiennoprzecinkową na cykl: http://www.nvidia.com/content/PDF/kepler/NVIDIA-Kepler-GK110-Architecture-Whitepaper.pdf, http://www.realworldtech.com/kepler-brief/
Gdybym układał slajdy na ten temat, miałbym jedną sekcję wyjaśniającą ile operacji FP Haswell może wykonać na cykl: trzy punkty powyżej, plus masz wiele rdzeni i prawdopodobnie wiele procesorów. A ja bym miał inną sekcję wyjaśniającą ile operacji FP może wykonać GPU Kepler na cykl: 192 na SMX, a na GPU masz wiele jednostek SMX.
PS.: Być może stwierdzam oczywiste, ale aby uniknąć nieporozumień: Architektura Haswella zawiera również zintegrowany GPU, który ma zupełnie inną architekturę niż procesor Haswella.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-07-02 18:09:57
Byłbym bardzo ostrożny przy dokonywaniu tego rodzaju porównań. W końcu nawet w świecie GPU termin "rdzeń" w zależności od kontekstu ma naprawdę różne możliwości: nowy AMD GCN różni się od Starego VLIW4, który sam w sobie jest zupełnie inny od CUDA core.
Poza tym przyniesiesz więcej zagadek niż zrozumienia do odbiorców, jeśli zrobisz tylko jedno małe porównanie Z CPU i to wszystko. Gdybym był na Twoim miejscu to i tak bym poszedł na bardziej szczegółowy (może być jeszcze szybki) porównanie.
na przykład ktoś kiedyś CPU i z niewielką wiedzą o GPU, może się zastanawiać, jak to możliwe, że GPU może mieć tak wiele rejestrów, choć jest tak drogie (w świecie CPU). Wyjaśnienie na to pytanie znajduje się na końcu tego post, a także kilka innych porównań GPU vs CPU.
Ten Inny Artykuł daje ładne porównanie między tymi dwoma rodzajami jednostek przetwarzania, wyjaśniając, jak działają GPU, ale także jak ewoluowały i pokazując różnice z procesorami. Dotyczy to tematów takich jak przepływ danych, hierarchia pamięci, ale także tego, jakiego rodzaju aplikacje GPU jest przydatny. W końcu moc, którą może rozwinąć GPU, jest dostępna (wydajnie) tylko w przypadku niektórych rodzajów problemów.
I osobiście, gdybym miał zrobić prezentację na temat GPU i miał możliwość zrobić tylko jedno odniesienie do CPU {[11] } byłoby to: przedstawianie problemów, które GPU może skutecznie rozwiązać, a te, z którymi procesor radzi sobie lepiej.
Jako bonus, mimo że nie jest bezpośrednio związany z Twoją prezentacją tutaj jest Artykuł , który stawia GPGPU w perspektywie, pokazując, że pewne przyspieszenie, które niektórzy twierdzą, że są przereklamowane (jest to związane z moim ostatnim punktem btw :))
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-07-02 14:33:00
W pełni zgadzam się z CaptainObvious, zwłaszcza że przedstawienie problemów, które GPU może skutecznie rozwiązać, a tych, z którymi procesor poradzi sobie lepiej byłoby dobrym pomysłem.
Jednym ze sposobów, w jaki lubię porównywać procesory i GPU, jest liczba operacji / sek. Ale oczywiście nie porównuj jednego rdzenia procesora do wielordzeniowego gpu.
Rdzeń SandyBridge może wykonywać 2 operacje AVX / cykle, czyli 8 podwójnych liczb precyzji / cykl. Stąd komputer z 16-bitowym mostkiem rdzenie taktowane na 2,6 GHz mają moc szczytową 333 Gflops.
Moduł obliczeniowy K20 GK110 ma szczyt 1170 Gflops, czyli 3,5 razy więcej. Moim zdaniem jest to uczciwe porównanie i należy podkreślić, że Szczytowa wydajność jest znacznie łatwiejsza do osiągnięcia na CPU (niektóre aplikacje osiągają 80% -90% peak) niż na GPU ( Najlepsze przypadki , jakie znam, to mniej niż 50% peak ).
Więc summerize, nie chciałbym wchodzić w szczegóły architektury, ale raczej podać jakieś ścinanie liczby z perspektywą, że szczyt jest często daleko od osiągnięcia na GPU.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-07-02 17:33:54
Bardziej sprawiedliwe jest porównywanie GPU do wektoryzowanych jednostek CPU jednak jeśli odbiorcy mają zero pojęcia o tym, jak działają GPU, wydaje się sprawiedliwe założenie, że mają podobną wiedzę o wektoryzowanych instrukcjach SSE.
Dla takich odbiorców ważne jest, aby zwrócić uwagę na duże różnice w poziomie, takie jak to, jak bloki "rdzeni" na gpu współdzielą harmonogram i rejestrują plik.
Jeśli chodzi o architekturę Keplera, to nie jest to możliwe. Wygląda Architektura Keplera. to jest również dość zrozumiałe porównanie między nimi, jeśli chcesz trzymać się idei "rdzenia gpu".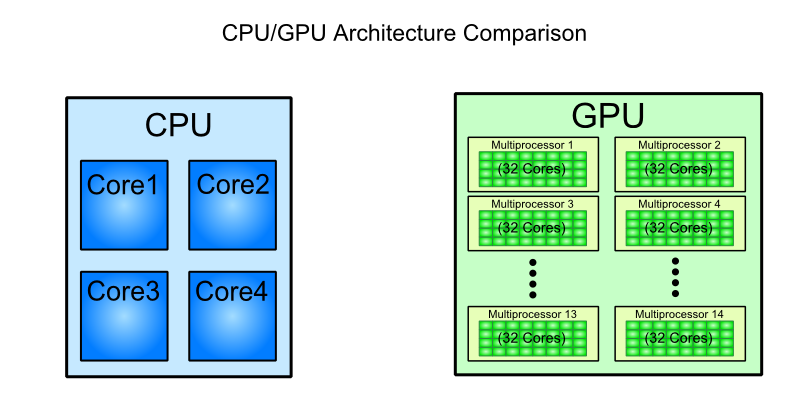{kind=link}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-07-02 18:52:34