Hadoop input split size vs block size
Przechodzę przez hadoop definitive guide, gdzie jasno wyjaśnia o podziałach wejściowych. It goes like
Input splits nie zawiera rzeczywistych danych, a raczej przechowuje lokalizacje danych na HDFS
I
Zazwyczaj rozmiar podziału wejściowego jest taki sam jak rozmiar bloku
1) Załóżmy, że blok 64MB znajduje się na węźle A i jest replikowany między 2 innymi węzłami (B, C), a rozmiar podziału wejściowego dla programu Map-reduce wynosi 64MB, czy to split ma tylko lokalizację węzła A? Czy będzie miał lokalizacje dla wszystkich trzech węzłów A, b,C?
2) ponieważ dane są lokalne dla wszystkich trzech węzłów, w jaki sposób framework decyduje (wybiera) maskę maptask do uruchomienia na danym węźle?
3) Jak to jest obsługiwane, jeśli rozmiar podziału wejściowego jest większy lub mniejszy niż rozmiar bloku?
7 answers
Odpowiedź od @ user1668782 jest doskonałym wyjaśnieniem pytania i postaram się podać graficzny obraz tego pytania.
-
Załóżmy, że mamy Plik 400MB z 4 rekordami(e. G : plik csv o pojemności 400MB i ma 4 wiersze po 100MB każdy)
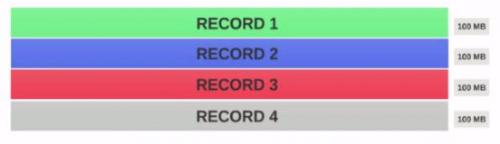
- Jeśli rozmiar bloku HDFS jest skonfigurowany jako 128MB , wtedy 4 rekordy nie będą rozdzielane między bloki równomiernie. To będzie wyglądało tak.
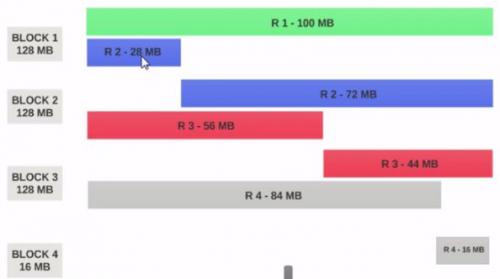
- Blok 1 zawiera cały pierwszy rekord i 28MB fragmentu drugiego rekordu.
- jeśli maper ma być uruchomiony nabloku 1 , maper nie może go przetworzyć, ponieważ nie będzie miał całego drugiego rekordu.
Jest to dokładnie problem, który input splits rozwiązuje. Input splits respektuje logiczne granice rekordów.
Przyjmijmy input split rozmiar to 200MB
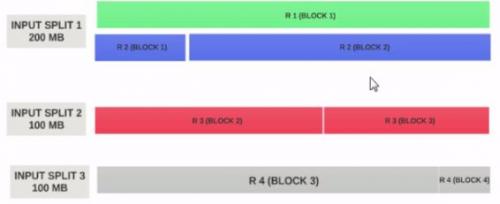
Dlatego input split 1 powinien mieć zarówno rekord 1, jak i rekord 2. I input split 2 nie rozpocznie się od rekordu 2, ponieważ rekord 2 został przypisany do Input split 1. Input split 2 rozpocznie się od rekordu 3.
Dlatego podział danych wejściowych jest tylko logicznym fragmentem danych. Wskazuje miejsca rozpoczęcia i zakończenia w blokach.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-07-11 04:50:27
Blok jest fizyczną reprezentacją danych. Split jest logiczną reprezentacją danych obecnych w bloku.
Rozmiar bloku i dzielenia można zmienić we właściwościach.
Map odczytuje dane z bloku przez podziały tzn. split działa jako broker pomiędzy blokiem a maperem.
Rozważmy dwa bloki:
Blok 1
Aa bb CC dd EE ff gg Hh ii jj
Blok 2
Ww ee yy uu oo ii oo pp Kk ll NN
Teraz Mapa czyta block 1 do aa do JJ i nie wie jak odczytac block 2 tzn. block nie wie jak przetworzyc inny blok informacji. Oto podział, który utworzy logiczne grupowanie bloku 1 i bloku 2 jako pojedynczy blok, a następnie utworzy offset (klucz) i linię (wartość) za pomocą inputformat i czytnika rekordów i wyśle mapę do dalszego przetwarzania.
Jeśli Twój zasób jest ograniczony i chcesz ograniczyć liczbę map, możesz zwiększyć rozmiar podziału. Na przykład: Jeśli mamy 640 MB z 10 bloki tzn. każdy blok 64 MB i zasób jest ograniczony wtedy można wymienić rozmiar podziału jako 128 MB następnie powstaje logiczne grupowanie 128 MB i tylko 5 map zostanie wykonanych o rozmiarze 128 MB.
Jeśli określimy rozmiar split false, to cały plik utworzy jeden podział wejściowy i będzie przetwarzany przez jedną mapę, co zajmuje więcej czasu, gdy plik jest duży.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-08-20 19:58:45
Podziały wejściowe są logicznym podziałem Twoich rekordów, podczas gdy bloki HDFS są fizycznym podziałem danych wejściowych. Jest niezwykle wydajny, gdy są takie same, ale w praktyce nigdy nie jest idealnie dopasowany. Zapisy mogą przekraczać granice bloków. Hadoop gwarantuje przetwarzanie wszystkich rekordów . Maszyna przetwarzająca dany split może pobrać fragment rekordu z bloku innego niż jego" główny " blok i który może znajdować się zdalnie. Koszt komunikacji przy pobieraniu rekordu fragment jest nieistotny, ponieważ zdarza się stosunkowo rzadko.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-01-08 05:51:24
Do 1) i 2): nie jestem pewien w 100%, ale jeśli zadanie nie może zostać ukończone-z jakiegokolwiek powodu, w tym jeśli coś jest nie tak z podziałem wejściowym - wtedy jest ono zakończone, a inny uruchomiony w jego miejscu: więc każda maptask dostaje dokładnie jeden podział z informacją o pliku (możesz szybko stwierdzić, czy tak jest, debugując w lokalnym klastrze, aby zobaczyć, jakie informacje są przechowywane w obiekcie input split: wydaje mi się, że pamiętam, że to tylko jedna lokalizacja).
Do 3): Jeśli format pliku jest splittable, a następnie Hadoop spróbuje wyciąć plik do rozmiaru" inputSplit"; jeśli nie, to jest to jedno zadanie na plik, niezależnie od rozmiaru pliku. Jeśli zmienisz wartość minimum-input-split, możesz zapobiec powstawaniu zbyt wielu zadań mappera, jeśli każdy z Twoich plików wejściowych jest podzielony na rozmiar bloku, ale możesz tylko połączyć wejścia, jeśli zrobisz coś magicznego z klasą combiner (myślę, że tak się nazywa).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-07-18 15:28:11
Siła szkieletu Hadoop to jego dane locality.So ilekroć klient żąda danych hdfs, framework zawsze sprawdza lokalizację, w której szuka Niewielkiego wykorzystania we / wy.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-05-30 13:56:48
Input splits są logicznymi jednostkami danych przekazywanymi do każdego mapera. Dane są dzielone na ważne rekordy. Podziały wejściowe zawierają adresy bloków i przesunięć bajtów.
Załóżmy, że masz plik tekstowy, który obejmuje 4 bloki.
Plik:
a b c D
e f g h
i j k L
m n O P
Bloki:
Block1: a b c D e
block2: f g H i j
block3: k L m n o
block4: p
Podział:
Split1: a b c d e F H
Split2: i j k l m N O P
Obserwuj podziały są w linii z granicami (rekordami) z pliku. Teraz każdy podział jest podawany maperowi.
Jeśli rozmiar podziału wejściowego jest mniejszy niż rozmiar bloku, w końcu użyjesz więcej no.mapperów na odwrót.
Mam nadzieję, że to pomoże.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-09-09 07:55:26
Rozmiar bloku HDFS jest dokładną liczbą, ale Rozmiar podziału wejściowego jest oparty na naszym logika danych, która może być nieco inna z ustawionym numerem
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-02-12 05:43:57