Świnia vs Ul vs Native Map Reduce
Mam podstawowe zrozumienie, czym są abstrakcje Świnia, Ul. Ale nie mam jasnego pomysłu na scenariusze, które wymagają Ula, świni lub native Map reduce.
Przejrzałem kilka artykułów, które w zasadzie wskazują, że ula jest do strukturalnego przetwarzania, a Świnia do niestrukturalnego przetwarzania. Kiedy potrzebujemy native map reduce? Czy możesz wskazać kilka scenariuszy, których nie można rozwiązać za pomocą Pig lub Hive, ale w native map reduce?
7 answers
Złożona logika rozgałęzień, która ma wiele zagnieżdżonych if .. else .. structures jest łatwiejsze i szybsze do zaimplementowania w standardowym MapReduce, do przetwarzania danych strukturalnych można użyć Pangool , upraszcza to również takie rzeczy jak JOIN. Również standardowe MapReduce daje pełną kontrolę, aby zminimalizować liczbę zadań MapReduce, że przepływ przetwarzania danych wymaga, co przekłada się na wydajność. Ale potrzeba więcej czasu na kodowanie i wprowadzanie zmian.
Apache Pig is good for struktura danych też, ale jego zaletą jest możliwość pracy z workami danych( wszystkie wiersze, które są pogrupowane na kluczu), łatwiej jest zaimplementować takie rzeczy jak:
- Get top N elementów dla każdej grupy;
- Oblicz sumę dla każdej grupy i umieść tę sumę dla każdego wiersza w grupie;
- Użyj filtrów Bloom do optymalizacji połączeń;
- wsparcie Multiquery (jest to, gdy PIG próbuje zminimalizować liczbę zadań MapReduce, wykonując więcej rzeczy w jednym Job)
Hive lepiej nadaje się do zapytań ad-hoc, ale jego główną zaletą jest to, że ma silnik, który przechowuje i partycjonuje dane. Ale jego tabele można odczytać z Pig lub Standard MapReduce.
Jeszcze jedno, Hive i Pig nie nadają się do pracy z danymi hierarchicznymi.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-02-19 16:35:38
Krótka odpowiedź - potrzebujemy MapReduce, gdy potrzebujemy bardzo głębokiego poziomu i drobnoziarnistej kontroli w sposób, w jaki chcemy przetwarzać nasze dane. Czasami nie jest bardzo wygodne, aby wyrazić to, czego potrzebujemy dokładnie w kategoriach zapytań świnia i Ula.
Nie powinno być całkowicie niemożliwe, aby zrobić, co można za pomocą MapReduce, przez świnię lub UL. Z poziomem elastyczności zapewnianym przez Pig and Hive można jakoś osiągnąć swój cel, ale może to nie być tak gładkie. Możesz napisać UDFs lub zrób coś i to osiągnij.
Nie ma wyraźnego rozróżnienia pomiędzy używaniem tych narzędzi. To całkowicie zależy od konkretnego przypadku użycia. Na podstawie Twoich danych i rodzaju przetwarzania musisz zdecydować, które narzędzie lepiej pasuje do Twoich wymagań.
Edit:
Jakiś czas temu miałem przypadek użycia, w którym musiałem zebrać dane sejsmiczne i przeprowadzić na nim analizę. Format plików przechowujących te dane był nieco dziwny. Część danych była EBCDIC zakodowane, podczas gdy reszta danych była w formacie binarnym. Był to w zasadzie płaski plik binarny bez ograniczników typu\n czy coś. Ciężko mi było znaleźć sposób na przetworzenie tych plików za pomocą Pig lub Hive. W rezultacie musiałem ustatkować się z panem. początkowo zajęło to trochę czasu, ale stopniowo stało się gładsze, ponieważ Pan jest naprawdę szybki, gdy masz gotowy podstawowy szablon.
Więc, jak mówiłem wcześniej, to w zasadzie zależy od Twojego przypadku użycia. Na przykład, iteracja nad każdy zapis Twojego zbioru danych jest naprawdę łatwy w Pig (tylko foreach), ale co jeśli potrzebujesz foreach n?? Tak więc, gdy potrzebujesz "tego" poziomu kontroli nad sposobem przetwarzania danych, MR jest bardziej odpowiedni.
Inną sytuacją może być sytuacja, gdy dane są hierarchiczne, a nie oparte na wierszach lub gdy dane są wysoce nieustrukturyzowane.
Problem Metapatternów polegający na łańcuchowaniu zadań i łączeniu zadań jest łatwiejszy do rozwiązania za pomocą MR bezpośrednio niż za pomocą Pig / Hive.
I czasami bardzo wygodne jest wykonanie konkretnego zadania za pomocą jakiegoś narzędzia xyz w porównaniu do zrobienia tego za pomocą Pig / hive. IMHO, PAN okazuje się lepszy również w takich sytuacjach. Na przykład, jeśli potrzebujesz wykonać pewne analizy statystyczne na BigData, R używany z Hadoop streaming jest prawdopodobnie najlepszym rozwiązaniem.
HTH
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-07-31 09:09:05
Mapreduce:
Strengths:
works both on structured and unstructured data.
good for writing complex business logic.
Weakness:
long development type
hard to achieve join functionality
Hive:
Strengths:
less development time.
suitable for adhoc analysis.
easy for joins
Weakness :
not easy for complex business logic.
deals only structured data.
Świnia
Strengths :
Structured and unstructured data.
joins are easily written.
Weakness:
new language to learn.
converted into mapreduce.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-12-28 18:15:43
Ul
Plusy:
SQL like Faceci z bazy danych to uwielbiają. Dobre wsparcie dla danych strukturalnych. Obecnie obsługuje schemat bazy danych i widoki, takie jak struktura Obsługa jednoczesnych wielu użytkowników, scenariuszy wielu sesji. Większe wsparcie społeczności. Hive, hiver server, Hiver Server2 ,Impala, Centry already
Cons: Wydajność pogarsza się, gdy dane rosną, nie ma wiele do zrobienia, problemy z pamięcią nad przepływem. nie mogę wiele z tym zrobić. Hierarchiczne dane to wyzwanie. Dane niezorganizowane wymagają komponent podobny do udf Połączenie wielu technik może być koszmarem dynamicznych porcji z UTDF w przypadku dużych danych itp
Świnia: Plusy: Świetny język przepływu danych oparty na skryptach.
Wady:
Un-structured data requires UDF like component Nie duże wsparcie społeczności
MapReudce: Plusy: Nie zgadzaj się z "trudną do osiągnięcia funkcją join", jeśli rozumiesz, jakiego rodzaju join chcesz zaimplementować, możesz zaimplementować za pomocą kilku linijek kodu. Najczęściej PAN zapewnia lepszą wydajność. Wsparcie MR dla danych hierarchicznych jest świetne zwłaszcza implementować struktury podobne do drzewa. Lepsza kontrola przy partycjonowaniu / indeksowaniu danych. Praca łańcuchy.
Cons: Trzeba bardzo dobrze znać api, aby uzyskać lepszą wydajność itp Code / debug / maintain
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-08-21 19:02:42
scenariusze gdzie Hadoop Map Reduce jest preferowany do ula lub świni
-
Kiedy potrzebujesz sterownika Program control
-
Gdy zadanie wymaga implementacji niestandardowego Partycjonera
-
Jeśli istnieje już predefiniowana biblioteka maperów lub reduktorów Javy dla zadania
- Jeśli potrzebujesz dużej ilości testowalności podczas łączenia wielu dużych zbiorów danych
- Jeśli aplikacja wymaga kodu starszego wymagania, które dowodzą struktury fizycznej
- Jeśli zadanie wymaga optymalizacji na danym etapie przetwarzania poprzez jak najlepsze wykorzystanie sztuczek, takich jak łączenie w maperze
- Jeśli zadanie ma trudne użycie rozproszonej pamięci podręcznej (replikowane połączenie), produktów krzyżowych, grup lub łączy
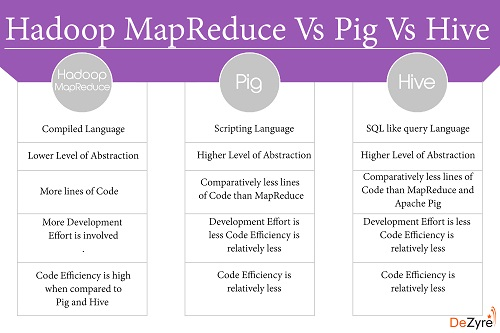
plusy świni/Ula :
- Hadoop MapReduce wymaga większego wysiłku programistycznego niż Pig i Hive.
- świnia i UL metody kodowania są wolniejsze niż w pełni dostrojony program Hadoop MapReduce.
- używając Pig i Hive do wykonywania zadań, Programiści Hadoop nie muszą się martwić o jakiekolwiek niedopasowanie wersji.
- istnieje bardzo ograniczona możliwość pisania błędów na poziomie java podczas kodowania w Pig lub Hive.
Spójrz na ten post dla Pig Vs Hive porównanie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-09-04 11:12:08
Wszystkie rzeczy, które możemy zrobić za pomocą PIG i HIVE można osiągnąć za pomocą MR (czasami Będzie to jednak czasochłonne). PIG and HIVE używa MR / SPARK/TEZ pod spodem. Więc wszystkie rzeczy, które pan może zrobić, mogą lub nie mogą być możliwe w ulu i świni.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-12-15 18:28:15
Tutaj jest wielkie porównanie. Określa wszystkie scenariusze przypadków użycia.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-10-19 12:13:50