Mapa hadoop zmniejsz sortowanie wtórne
Czy ktoś może mi wyjaśnić, jak działa sortowanie wtórne w hadoop ?
Dlaczego trzeba używać GroupingComparator i jak to działa w hadoop ?
Przechodziłem przez link podany poniżej i mam wątpliwości, jak działa groupcomapator.
Czy ktos moze mi wyjasnic jak dziala komparator grupowania?
Http://www.bigdataspeak.com/2013/02/hadoop-how-to-do-secondary-sort-on_25.html
5 answers
Komparator Grupujący
Gdy dane dotrą do reduktora, wszystkie dane są pogrupowane według klucza. Ponieważ mamy klucz złożony, musimy upewnić się, że rekordy są pogrupowane wyłącznie według klucza naturalnego. Osiąga się to poprzez napisanie niestandardowej Grupypartitioner. Mamy obiekt porównawczy, który uwzględnia tylko pole yearMonth klasy TemperaturePair do celów grupowania rekordów razem.
public class YearMonthGroupingComparator extends WritableComparator {
public YearMonthGroupingComparator() {
super(TemperaturePair.class, true);
}
@Override
public int compare(WritableComparable tp1, WritableComparable tp2) {
TemperaturePair temperaturePair = (TemperaturePair) tp1;
TemperaturePair temperaturePair2 = (TemperaturePair) tp2;
return temperaturePair.getYearMonth().compareTo(temperaturePair2.getYearMonth());
}
}
Oto wyniki naszego drugorzędnego sortowania zadanie:
new-host-2:sbin bbejeck$ hdfs dfs -cat secondary-sort/part-r-00000
190101 -206
190102 -333
190103 -272
190104 -61
190105 -33
190106 44
190107 72
190108 44
190109 17
190110 -33
190111 -217
190112 -300
Chociaż sortowanie danych według wartości może nie być częstą potrzebą, jest to miłe narzędzie, które można mieć w tylnej kieszeni, gdy jest to potrzebne. Ponadto udało nam się głębiej przyjrzeć się wewnętrznemu działaniu Hadoop przez praca z partycjonerami niestandardowymi i partycjonerami grupowymi. Zobacz też ten link..Jakie jest zastosowanie komparatora grupującego w hadoop map reduce
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:10:30
Łatwo zrozumieć pewne pojęcia za pomocą diagramów i to z pewnością jest jednym z nich.
Załóżmy, że nasze sortowanie wtórne odbywa się na kluczu złożonym złożonym z nazwiska i Imienia.
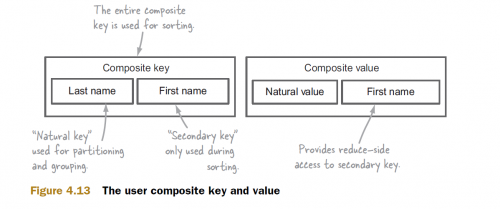
Z wyjętym z drogi kluczem kompozytowym, przyjrzyjmy się mechanizmowi sortowania wtórnego
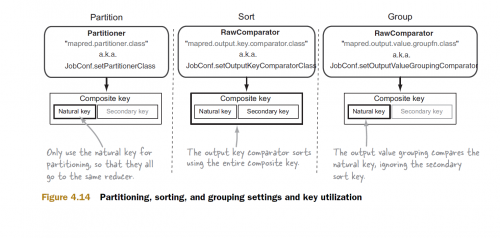
Partycjoner i komparator grup używają tylko klucza naturalnego, partycjoner używa go do przesyłania wszystkich rekordów za pomocą ten sam naturalny klucz do jednego reduktora. to partycjonowanie odbywa się w fazie Map, dane z różnych zadań Map są odbierane przez reduktory, gdzie są zgrupowane, a następnie wysyłane do metody reduce. Jeśli nie określilibyśmy Niestandardowy komparator grup, Hadoop użyłby domyślnej implementacji, która uwzględniałaby cały klucz złożony, co prowadziłoby do nieprawidłowego wyniki.
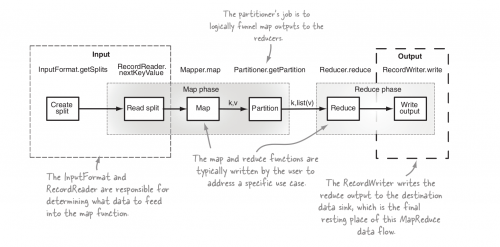
Przegląd kroków MR
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-04-15 08:30:27
Oto przykład grupowania. Rozważmy klucz złożony (a, b) i jego wartość v. I załóżmy, że po sortowaniu kończy się m.in. następującą grupą par (klucz, wartość):
(a1, b11) -> v1
(a1, b12) -> v2
(a1, b13) -> v3
Z domyślnym komparatorem grup framework wywoła funkcję reduce 3 razy z odpowiednimi parami (klucz, wartość), ponieważ wszystkie klucze są różne. Jeśli jednak podasz swój własny, niestandardowy komparator Grupowy i zdefiniujesz go tak, aby zależał tylko od a, ignorując b, następnie Framework stwierdza, że wszystkie klucze w tej grupie są równe i wywołuje funkcję reduce tylko raz używając następującego klucza i listy wartości:
(a1, b11) -> <v1, v2, v3>
Zauważ, że używany jest tylko pierwszy klucz złożony, A b12 i b13 są "utracone", tzn. nie są przekazywane do reduktora.
W dobrze znanym przykładzie z książki "Hadoop" obliczanie maksymalnej temperatury przez rok, a jest rokiem, a b są temperaturami posortowanymi w porządku malejącym, więc B11 jest pożądanym max temperatura i nie dbasz o inne b's. funkcja reduce po prostu zapisuje otrzymane (a1, b11) jako rozwiązanie dla tego roku.
W twoim przykładzie z "bigdataspeak.com" wszystkie b są wymagane w reduktorze, ale są dostępne jako części odpowiednich wartości (obiektów) v.
W ten sposób, włączając wartość lub jej część do klucza, możesz użyć Hadoop do sortowania nie tylko kluczy, ale także wartości.
Mam nadzieję, że to pomoże.Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-20 07:09:00
Partycjoner tylko zapewnia, że jeden reduktor odbiera wszystkie rekordy należące do klucza, ale nie zmienia to faktu, że reduktor grupuje według klucza wewnątrz partycji.
W przypadku sortowania wtórnego tworzymy klucze złożone i jeśli pozwolimy na kontynuowanie domyślnego zachowania, logika grupowania uzna klucze za inne.
Więc musimy kontrolować zgrupowanie. Dlatego musimy wskazać ramy do grupy opartej na naturalnej części klucza, a nie na klucz złożony. Dlatego komparator grupujący musi być używany do tego samego.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-23 13:22:31
Powyższe przykłady mają dobre wyjaśnienie, pozwól mi to uprościć.musimy wykonać trzy główne kroki.
- Mapout powinien być (klucz+wartość, wartość)
- Kiedy dołączyliśmy Key & Value. Jeszcze musimy mieć mechanizm sortowania na oryginalnym kluczu jak i na value.So dodalibyśmy Niestandardowy komparator.
- Teraz dane są sortowane na oryginalnym kluczu, ale jeśli wyślemy te dane do reduktora, nie zagwarantuje to wysłania całej wartości danego klucza do jednego reduktora, ponieważ używamy klucza+wartość jako klucz. Aby się upewnić dodamy komparator Grupowy.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-09-12 08:17:50