Napisz program, aby znaleźć 100 największych liczb z tablicy 1 miliarda liczb
Ostatnio uczestniczyłem w wywiadzie, w którym zostałem poproszony o napisanie programu, aby znaleźć 100 największych liczb z tablicy 1 miliarda liczb."
Byłem w stanie podać tylko rozwiązanie brute force, które polegało na sortowaniu tablicy w o(nlogn) złożoności czasowej i pobieraniu ostatnich 100 liczb.
Arrays.sort(array);
Ankieter szukał lepszego czasu, próbowałem kilku innych rozwiązań, ale nie udało mu się odpowiedzieć. Czy istnieje lepsze rozwiązanie złożoności czasu?
30 answers
Możesz zachować priorytetową kolejkę 100 największych liczb, iterację przez miliardy liczb, gdy napotkasz liczbę większą niż najmniejsza liczba w kolejce (head of the queue), Usuń head of the queue i dodaj nowy numer do kolejki.
EDIT:
jak zauważył Dev, z kolejką priorytetową zaimplementowaną za pomocą sterty, złożoność wstawiania do kolejki wynosi O(logN)
W najgorszym przypadku dostajesz {[1] } który jest lepszy niż billionlog2(billion)
W ogólnie, jeśli potrzebujesz największej liczby K ze zbioru n liczb, złożoność wynosi O(NlogK) zamiast O(NlogN), może to być bardzo istotne, gdy K jest bardzo małe w porównaniu do N.
EDIT2:
Oczekiwany czas tego algorytmu jest dość interesujący, ponieważ w każdej iteracji może wystąpić wstawianie lub nie. Prawdopodobieństwo Wstawienia i ' tej liczby do kolejki jest prawdopodobieństwem, że zmienna losowa będzie większa niż co najmniej i-K zmienne losowe z ten sam rozkład (pierwsze liczby k są automatycznie dodawane do kolejki). Możemy użyć statystyki zamówienia (zobacz link) do obliczenia tego prawdopodobieństwa. Na przykład, załóżmy, że liczby zostały losowo wybrane jednolicie z {0, 1}, wartość oczekiwana (i-K)tej liczby (z liczb i) wynosi (i-k)/i, a szansa, że zmienna losowa będzie większa od tej wartości wynosi 1-[(i-k)/i] = k/i.
Tak więc oczekiwana liczba wstawek wynosi:
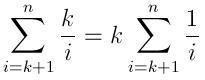
I oczekiwany bieg czas można wyrazić jako:
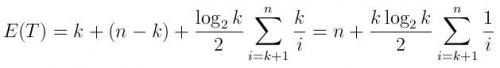
(k Czas generowania kolejki z pierwszymi elementami k, następnie porównaniami n-k i oczekiwaną liczbą wstawek, jak opisano powyżej, każdy zajmuje średni czas log(k)/2)
Zauważ, że gdy N jest bardzo duża w porównaniu do K, wyrażenie to jest znacznie bliższe n, a nie NlogK. Jest to nieco intuicyjne, jak w przypadku pytania, nawet po 10000 iteracji (co jest bardzo małe w porównaniu do miliard), szansa, że liczba zostanie wstawiona do kolejki jest bardzo mała.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 08:39:45
Jeśli zostanie to zadane w wywiadzie, myślę, że rozmówca prawdopodobnie chce zobaczyć twój proces rozwiązywania problemów, a nie tylko znajomość algorytmów.
Opis jest dość ogólny, więc może możesz zapytać go o zakres lub znaczenie tych liczb, aby wyjaśnić problem. Robi to może zaimponować rozmówcy. Jeśli, na przykład, liczby te oznaczają wiek ludzi w danym kraju (np. w Chinach), to jest to o wiele łatwiejszy problem. Z rozsądnym założeniem, że nikt nie żyje jest starszy niż 200, możesz użyć tablicy int O rozmiarze 200 (może 201), aby policzyć liczbę osób w tym samym wieku w jednej iteracji. Tutaj indeks oznacza wiek. Po tym to bułka z masłem, aby znaleźć 100 największą liczbę. Swoją drogą to algo nazywa się liczenie sortowania.
W każdym razie, bardziej szczegółowe i jaśniejsze pytanie jest dobre dla Ciebie w wywiadzie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-01-18 08:34:14
Możesz iterować nad liczbami, które zajmują O (n)
Za każdym razem, gdy znajdziesz wartość większą niż obecne minimum, Dodaj nową wartość do okrągłej kolejki O rozmiarze 100.
Min tej okrągłej kolejki jest twoją nową wartością porównawczą. Dodawaj do tej kolejki. Jeśli jest pełny, wyciągnij minimum z kolejki.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-07 19:34:06
Zdałem sobie sprawę, że jest to oznaczone 'algorytm' , ale wyrzucę kilka innych opcji, ponieważ prawdopodobnie powinno być również oznaczone 'Wywiad'.
Jakie jest źródło 1 miliarda liczb? Jeśli jest to baza danych, to 'select value from table order by value desc limit 100' zrobiłby to całkiem nieźle - mogą występować różnice w dialekcie.
Czy to jednorazowe,czy coś, co się powtórzy? Jeśli powtarzane, jak często? Jeśli jest jednorazowy i dane znajdują się w pliku, to 'cat srcfile / sort | options as needed) / head -100' pozwoli Ci szybko wykonywać produktywną pracę, za którą otrzymujesz wynagrodzenie, podczas gdy komputer radzi sobie z tym banalnym obowiązkiem.
Jeśli się powtórzy, radzisz wybrać jakieś przyzwoite podejście, aby uzyskać początkową odpowiedź i zapisać / buforować wyniki, aby móc stale zgłaszać top 100.
Wreszcie jest to rozważenie. Szukasz pracy na poziomie podstawowym i rozmowy kwalifikacyjnej z geeky managerem lub przyszły współpracownik? Jeśli tak, to można wyrzucić wszelkiego rodzaju podejścia opisujące względne plusy i minusy techniczne. Jeśli szukasz bardziej menedżerskiej pracy, podejmij ją tak, jak menedżer, zaniepokojony kosztami rozwoju i utrzymania rozwiązania, i powiedz "dziękuję bardzo" i odejdź, jeśli to jest ankieter chce skupić się na ciekawostkach CS. On I ty nie mielibyście tam większego potencjału.
Powodzenia w następnym wywiadzie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-08 22:09:02
Możesz użyć algorytmu Quick select , aby znaleźć liczbę w indeksie (według kolejności) [miliard-101] a potem powtarzaj Liczby i znajdź liczby, które są większe od tej liczby.
array={...the billion numbers...}
result[100];
pivot=QuickSelect(array,billion-101);//O(N)
for(i=0;i<billion;i++)//O(N)
if(array[i]>=pivot)
result.add(array[i]);
Czas algorytmu wynosi: 2 X O (N) = O (N) (średnia wydajność przypadku)
Druga opcja jak Thomas Jungblut suggest is:
Użyj sterta zbudowanie maksymalnej sterty zajmie O (N), wtedy 100 najwyższych liczb będzie w górnej części Heap, wszystko czego potrzebujesz to wyciągnąć je ze sterty (100 X O(Log(N)).
Czas algorytmu wynosi: O (N) + 100 X O(Log(N)) = O (N)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 11:46:46
Moją natychmiastową reakcją na to byłoby użycie sterty, ale jest sposób na użycie QuickSelect bez trzymania wszystkich wartości wejściowych pod ręką w tym samym czasie.
Utwórz tablicę o rozmiarze 200 i wypełnij ją pierwszymi 200 wartościami wejściowymi. Uruchom QuickSelect i odrzuć niskie 100, pozostawiając ci 100 wolnych miejsc. Odczytaj kolejne 100 wartości wejściowych i uruchom ponownie QuickSelect. Kontynuuj, dopóki nie uruchomisz całego wejścia w partiach po 100.
Na końcu masz górę 100 wartości. Dla N wartości uruchomiłeś QuickSelect mniej więcej N / 100 razy. Każdy Quickselect kosztuje około 200 razy jakąś stałą, więc całkowity koszt jest 2N razy pewną stałą. Wygląda to liniowo w rozmiarze wejścia dla mnie, niezależnie od wielkości parametru, który jestem Hardwired do 100 w tym wyjaśnieniu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-07 18:50:36
Chociaż inne rozwiązanie quickselect zostało odrzucone, faktem pozostaje, że quickselect znajdzie rozwiązanie szybciej niż używając kolejki o rozmiarze 100. Quickselect ma oczekiwany czas działania 2n + o( n), jeśli chodzi o porównania. Bardzo prostą implementacją byłoby
array = input array of length n
r = Quickselect(array,n-100)
result = array of length 100
for(i = 1 to n)
if(array[i]>r)
add array[i] to result
To zajmie średnio 3n + o(n) porównań. Co więcej, może być bardziej wydajny dzięki temu, że quickselect pozostawi największe 100 pozycji w tablicy w 100 prawej-najbardziej miejsca. Tak więc w rzeczywistości czas pracy można poprawić do 2n + o (n).
Istnieje problem, że jest to oczekiwany czas pracy, a nie najgorszy przypadek, ale używając przyzwoitej strategii wyboru pivot (np. wybierz 21 elementów losowo i wybierz medianę z tych 21 jako pivot), wtedy liczba porównań może być zagwarantowana z dużym prawdopodobieństwem, aby być co najwyżej (2 + c) N dla arbitralnie małej stałej c.
W rzeczywistości, przy użyciu zoptymalizowanej strategii pobierania próbek (np przykład sqrt(n) elements at random, and choose the 99th percentyl), the running time can get down to (1 + c)n + o (n) for arbitralnie small c(assuming that K, The number of elements to be selected is o (n)).
Z drugiej strony, użycie kolejki o rozmiarze 100 wymaga porównania O(log (100)n), A baza log 2 z 100 jest w przybliżeniu równa 6.6.
Jeśli pomyślimy o tym problemie w bardziej abstrakcyjnym sensie wyboru największych elementów K z tablicy wielkości N, gdzie K=o (N), ale zarówno K i N przejdź do nieskończoności, wtedy czas działania wersji quickselect będzie wynosił O(N), A wersja kolejki będzie wynosić O (N log K), więc w tym sensie quickselect jest również asymptotycznie lepszy.
W komentarzach wspomniano, że rozwiązanie kolejki będzie działać w oczekiwanym czasie N + K log N na losowym wejściu. Oczywiście, założenie losowego wejścia nigdy nie jest ważne, chyba że pytanie stwierdza to wyraźnie. Rozwiązanie kolejki może być wykonane tak, aby przemierzać tablicę w losowej kolejności, ale spowoduje to dodatkowy koszt N wywołań do generatora liczb losowych, a także albo permutacja całej tablicy wejściowej lub przydzielenie nowej tablicy długości N zawierającej indeksy losowe.
Jeśli problem nie pozwala na poruszanie się po elementach w oryginalnej tablicy, a koszt alokacji pamięci jest wysoki, więc powielanie tablicy nie jest opcją, to inna sprawa. Ale ściśle pod względem czasu pracy, jest to najlepsze rozwiązanie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 17:19:33
Weź pierwsze 100 liczb z miliarda I posortuj je. teraz wystarczy iterować przez miliard, jeśli liczba źródłowa jest wyższa niż najmniejsza z 100, wstawić w kolejności sortowania. To, co kończysz, to coś znacznie bliższego O (n) niż rozmiar zestawu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-07 14:56:15
Dwie opcje:
(1) Heap (priorityQueue)
Zachowaj stertę min O rozmiarze 100. Przemierzaj tablicę. Gdy element jest mniejszy od pierwszego elementu w stercie, zastąp go.
InSERT ELEMENT INTO HEAP: O(log100)
compare the first element: O(1)
There are n elements in the array, so the total would be O(nlog100), which is O(n)
(2) Model Map-reduce.
Jest to bardzo podobne do przykładu liczby słów w hadoop. Zadanie mapy: policz częstotliwość lub czasy pojawiania się każdego elementu. Reduce: Get top K element.
Zazwyczaj dawałem rekruterowi dwie odpowiedzi. Daj im, co chcą. Oczywiście, Mapa zmniejszenie kodowania byłoby pracą-niektóre, ponieważ trzeba znać wszystkie dokładne parametry. Nie zaszkodzi ćwiczyć. Powodzenia.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 00:27:50
Bardzo łatwym rozwiązaniem byłoby przeszukiwanie tablicy 100 razy. Czyli O(n).
Za każdym razem, gdy wyciągasz największą liczbę (i zmieniasz jej wartość na minimalną, tak, że nie widzisz jej w następnej iteracji, lub śledzisz indeksy poprzednich odpowiedzi (przez śledzenie indeksów oryginalna tablica może mieć wielokrotność tej samej liczby)). Po 100 iteracjach masz 100 największych liczb.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 16:45:46
Zainspirowany odpowiedzią @ Rona Tellera, oto program barebones C do robienia tego, co chcesz.
#include <stdlib.h>
#include <stdio.h>
#define TOTAL_NUMBERS 1000000000
#define N_TOP_NUMBERS 100
int
compare_function(const void *first, const void *second)
{
int a = *((int *) first);
int b = *((int *) second);
if (a > b){
return 1;
}
if (a < b){
return -1;
}
return 0;
}
int
main(int argc, char ** argv)
{
if(argc != 2){
printf("please supply a path to a binary file containing 1000000000"
"integers of this machine's wordlength and endianness\n");
exit(1);
}
FILE * f = fopen(argv[1], "r");
if(!f){
exit(1);
}
int top100[N_TOP_NUMBERS] = {0};
int sorts = 0;
for (int i = 0; i < TOTAL_NUMBERS; i++){
int number;
int ok;
ok = fread(&number, sizeof(int), 1, f);
if(!ok){
printf("not enough numbers!\n");
break;
}
if(number > top100[0]){
sorts++;
top100[0] = number;
qsort(top100, N_TOP_NUMBERS, sizeof(int), compare_function);
}
}
printf("%d sorts made\n"
"the top 100 integers in %s are:\n",
sorts, argv[1] );
for (int i = 0; i < N_TOP_NUMBERS; i++){
printf("%d\n", top100[i]);
}
fclose(f);
exit(0);
}
Na moim komputerze (core i3 z szybkim SSD) trwa 25 sekund i 1724 sek.
Wygenerowałem plik binarny z dd if=/dev/urandom/ count=1000000000 bs=1 dla tego uruchomienia.
Oczywiście występują problemy z wydajnością przy odczytywaniu tylko 4 bajtów na raz-z dysku, ale tak jest na przykład. Na plus, bardzo mało pamięci jest potrzebne.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 00:55:48
Najprostszym rozwiązaniem jest skanowanie dużej tablicy miliardów liczb i przechowywanie 100 największych wartości znalezionych do tej pory w buforze małej tablicy bez sortowania i zapamiętanie najmniejszej wartości tego bufora. Najpierw myślałem, że ta metoda została zaproponowana przez fordprefect, ale w komentarzu powiedział, że zakłada, że struktura danych liczbowych 100 jest implementowana jako sterta. Ilekroć zostanie znaleziona Nowa liczba, która jest większa, to minimum w buforze zostanie nadpisane przez nową wartość znalezioną i bufor ponownie wyszukuje aktualne minimum. Jeśli liczby w tablicy miliardów liczb są losowo rozmieszczone przez większość czasu wartość z dużej tablicy jest porównywana do minimum z małej tablicy i odrzucana. Tylko dla bardzo małego ułamka liczby wartość musi być włożona do małej tablicy. Można więc pominąć różnicę w manipulowaniu strukturą danych utrzymującą małe liczby. Dla niewielkiej liczby elementów trudno określić, czy użycie kolejki priorytetowej jest właściwie szybciej niż przy użyciu mojego naiwnego podejścia.
Chcę oszacować liczbę wstawek w małym buforze tablicy 100 elementów podczas skanowania tablicy 10^9 elementów. Program skanuje pierwsze 1000 elementów tej dużej tablicy i musi wstawić do bufora co najwyżej 1000 elementów. Bufor zawiera 100 z 1000 zeskanowanych elementów, czyli 0,1 zeskanowanego elementu. Zakładamy więc, że prawdopodobieństwo, że wartość z dużej tablicy jest większa niż obecne minimum bufor wynosi około 0.1 taki element musi być wstawiony do bufora . Teraz program skanuje kolejne 10^4 elementy z dużej tablicy. Ponieważ minimum bufora będzie rosło za każdym razem, gdy wstawiany jest nowy element. Oszacowaliśmy, że stosunek elementów większych od naszego obecnego minimum wynosi około 0,1, a więc do wstawienia jest 0,1*10^4=1000 elementów. W rzeczywistości oczekiwana liczba elementów, które zostaną wstawione do bufora, będzie mniejsza. Po zeskanowaniu tego 10^4 elementów ułamek liczb w buforze będzie wynosił około 0,01 elementów zeskanowanych do tej pory. Więc podczas skanowania kolejnych 10^5 liczb Zakładamy, że nie więcej niż 0.01*10^5=1000 zostanie wstawione do bufora. Kontynuując tę argumentację wstawiliśmy około 7000 wartości po zeskanowaniu 1000+10^4+10^5+...+ 10^9 ~ 10^9 elementów dużej tablicy. Tak więc podczas skanowania tablicy z 10^9 elementów o losowej wielkości oczekujemy nie więcej niż 10^4 (=7000 zaokrąglonych w górę) wstawek w buforze. Po każdym włożeniu do bufora musi zostać znalezione nowe minimum. Jeśli bufor jest prostą tablicą, potrzebujemy porównania 100, aby znaleźć nowe minimum. Jeśli bufor jest inną strukturą danych (jak sterta), potrzebujemy co najmniej 1 porównania, aby znaleźć minimum. Aby porównać elementy dużej tablicy potrzebujemy porównań 10^9. Więc w sumie potrzebujemy o 10^9+100*10^4=1.001 * 10^9 porównania przy użyciu tablicy jako bufora i co najmniej 1.000 * 10^9 porównania przy użyciu innego typu struktury danych (np. sterty). Więc użycie sterty przynosi tylko zysk o 0,1%, jeśli wydajność zależy od liczby porównań. Ale jaka jest różnica w czasie wykonania między wstawieniem elementu w tablicy 100 elementów a zastąpieniem elementu w tablicy 100 elementów i znalezieniem jego nowego minimum?
-
Na poziomie teoretycznym: ile porównań jest potrzebnych do wstawienia w stercie. Wiem, że jest O(log (n)), ale jak duży jest współczynnik stały? I
Na poziomie maszyny: Co to jest wpływ buforowania i przewidywania gałęzi na czas wykonania wstawki sterty i wyszukiwanie liniowe w tablicy.
Na poziomie implementacji: jakie dodatkowe koszty kryje struktura danych dostarczana przez bibliotekę lub kompilator?
Myślę, że są to niektóre z pytań, na które należy odpowiedzieć, zanim można spróbować oszacować rzeczywistą różnicę między wydajnością stosu 100 elementów lub tablicy 100 elementów. Więc byłoby sensowne, aby eksperyment i zmierzyć rzeczywistą wydajność.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-10 20:03:10
Although in this question we should search for top 100 numbers, I will
generalize things and write x. Still, I will treat x as constant value.
algorytm największych elementów x Z n:
Wywołam return value LIST . Jest to zbiór elementów x (moim zdaniem, które powinny być połączone listą)
- pierwsze elementy x są pobierane z puli "as they come" i sortowane w liście( odbywa się to w stałym czasie, ponieważ X jest traktowane jako stała - O(X log (X) ) time)
- dla każdego następnego elementu sprawdzamy, czy jest większy niż najmniejszy element w liście i jeśli jest, wyskakujemy z najmniejszy i wstawia bieżący element do listy. Ponieważ jest to lista uporządkowana, każdy element powinien znaleźć swoje miejsce w czasie logarytmicznym (wyszukiwanie binarne), a ponieważ jest to lista uporządkowana wstawianie nie stanowi problemu. Każdy krok jest również wykonywany w stałym czasie(o (log (x) ) time).
X log (x) + (n-x) (log (x) + 1) = nlog(x) + n - x
Więc to jest O (N) czas na najgorszy przypadek. +1 jest sprawdzaniem, czy liczba jest większa od najmniejszej na liście. Oczekiwany czas dla przeciętnego przypadku będzie zależał od rozkładu matematycznego tych n elementów.
możliwe ulepszenia
Ten algorytm można nieco poprawić w najgorszym przypadku, ale IMHO (nie mogę udowodnić tego twierdzenia), które pogorszy średnie zachowanie. Zachowanie asymptotyczne będzie takie samo.
Ulepszeniem tego algorytmu będzie to, że nie będziemy sprawdzać, czy element jest większy od najmniejszego. Dla każdego elementu postaramy się go wstawić i jeśli jest mniejszy niż najmniejszy, będziemy go lekceważyć. Chociaż brzmi to niedorzecznie, jeśli weźmiemy pod uwagę tylko najgorszy scenariusz, będziemy mieli
X log (x) + (n-x)log (x) = nlog (x)
Operacje.
W tym przypadku użycia nie widzę żadnych dalszych ulepszeń. Ale musisz zadać sobie pytanie - co jeśli muszę to robić więcej niż log (n) razy i dla różnych X-ów? Oczywiście posortowalibyśmy tę tablicę w O(N log (n)) i bierzemy nasz element x, kiedy tylko ich potrzebujemy.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-25 12:49:16
Na to pytanie odpowiadałoby n log (100) złożoności (zamiast n log N) z tylko jedną linijką kodu C++.
std::vector<int> myvector = ...; // Define your 1 billion numbers.
// Assumed integer just for concreteness
std::partial_sort (myvector.begin(), myvector.begin()+100, myvector.end());
Ostateczną odpowiedzią byłby wektor, w którym pierwsze 100 elementów jest gwarantowane jako 100 największych liczb tablicy, podczas gdy pozostałe elementy nie są uporządkowane
C++ STL (biblioteka standardowa) jest bardzo przydatna w tego typu problemach.
Uwaga: Nie mówię, że jest to optymalne rozwiązanie, ale uratowałoby to Twój Wywiad.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-27 15:29:27
Prostym rozwiązaniem byłoby użycie kolejki priorytetowej, dodanie pierwszych 100 liczb do kolejki i śledzenie najmniejszej liczby w kolejce, a następnie iterację przez pozostałe miliardy liczb, i za każdym razem, gdy znajdujemy taką, która jest większa niż największa liczba w kolejce priorytetowej, usuwamy najmniejszą liczbę, dodajemy nową liczbę i ponownie śledzimy najmniejszą liczbę w kolejce.
Gdyby liczby były w losowej kolejności, to działałoby to pięknie, ponieważ jak idąc przez miliard liczb losowych, bardzo rzadko zdarza się, aby następna liczba należała do 100 największych do tej pory. Ale liczby mogą nie być przypadkowe. Jeśli tablica była już posortowana w porządku rosnącym, to Zawsze wstawiamy element do kolejki priorytetów.
Wybieramy więc 100 000 losowych liczb z tablicy jako pierwszych. Aby uniknąć losowego dostępu, który może być powolny, dodajemy powiedzmy 400 losowych grup po 250 kolejnych liczb. Dzięki temu losowemu doborowi możemy być całkiem pewny, że bardzo niewiele z pozostałych liczb znajduje się w pierwszej setce, więc czas wykonania będzie bardzo zbliżony do prostej pętli porównującej miliard liczb do pewnej maksymalnej wartości.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-04-04 18:42:33
Znalezienie top 100 z miliarda liczb najlepiej wykonać za pomocą min-Stos 100 elementów.
Najpierw uruchom stertę min z pierwszymi 100 napotkanymi liczbami. min-heap będzie przechowywać najmniejszą z pierwszych 100 liczb w katalogu głównym (u góry).
Teraz, gdy idziesz wzdłuż reszty liczb, porównuj je tylko z korzeniem(najmniejszym ze 100).
Jeśli napotkana Nowa liczba jest większa niż root min-heap zastąp root tą liczbą, w przeciwnym razie zignoruj to.
W ramach wstawiania nowej liczby w min-heap najmniejsza liczba w stercie pojawi się na górze (root).
Po przejrzeniu wszystkich liczb będziemy mieli największe 100 liczb w stercie min.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-24 10:55:00
Napisałem proste rozwiązanie w Pythonie na wypadek gdyby ktoś był zainteresowany. Używa modułu bisect i tymczasowej listy zwrotnej, którą utrzymuje w porządku. Jest to podobne do implementacji kolejki priorytetów.
import bisect
def kLargest(A, k):
'''returns list of k largest integers in A'''
ret = []
for i, a in enumerate(A):
# For first k elements, simply construct sorted temp list
# It is treated similarly to a priority queue
if i < k:
bisect.insort(ret, a) # properly inserts a into sorted list ret
# Iterate over rest of array
# Replace and update return array when more optimal element is found
else:
if a > ret[0]:
del ret[0] # pop min element off queue
bisect.insort(ret, a) # properly inserts a into sorted list ret
return ret
Użycie z 100,000,000 elementów i najgorszymi literami wejściowymi, które są posortowaną listą:
>>> from so import kLargest
>>> kLargest(range(100000000), 100)
[99999900, 99999901, 99999902, 99999903, 99999904, 99999905, 99999906, 99999907,
99999908, 99999909, 99999910, 99999911, 99999912, 99999913, 99999914, 99999915,
99999916, 99999917, 99999918, 99999919, 99999920, 99999921, 99999922, 99999923,
99999924, 99999925, 99999926, 99999927, 99999928, 99999929, 99999930, 99999931,
99999932, 99999933, 99999934, 99999935, 99999936, 99999937, 99999938, 99999939,
99999940, 99999941, 99999942, 99999943, 99999944, 99999945, 99999946, 99999947,
99999948, 99999949, 99999950, 99999951, 99999952, 99999953, 99999954, 99999955,
99999956, 99999957, 99999958, 99999959, 99999960, 99999961, 99999962, 99999963,
99999964, 99999965, 99999966, 99999967, 99999968, 99999969, 99999970, 99999971,
99999972, 99999973, 99999974, 99999975, 99999976, 99999977, 99999978, 99999979,
99999980, 99999981, 99999982, 99999983, 99999984, 99999985, 99999986, 99999987,
99999988, 99999989, 99999990, 99999991, 99999992, 99999993, 99999994, 99999995,
99999996, 99999997, 99999998, 99999999]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-07 20:35:36
Widzę dużo dyskusji O (N), więc proponuję coś innego tylko dla ćwiczenia myślowego.
Czy są jakieś znane informacje o naturze tych liczb? Jeśli jest to przypadkowe, to nie idź dalej i spójrz na inne odpowiedzi. Nie osiągniesz lepszych wyników niż oni.
Jednak! Sprawdź, czy jakikolwiek mechanizm wypełniania listy wypełniał tę listę w określonej kolejności. Czy są one w dobrze zdefiniowanym wzorze, gdzie można wiedzieć z pewnością, że największe wielkość liczb zostanie znaleziona w określonym regionie listy lub w określonym przedziale czasu? Może być jakiś wzór. Jeśli tak jest, na przykład jeśli mają gwarancję, że będą w jakimś normalnym rozkładzie z charakterystycznym garbem w środku, zawsze mają powtarzające się trendy wzrostowe wśród zdefiniowanych podzbiorów, mają przedłużony skok w pewnym momencie T w środku zestawu danych, jak być może częstość występowania insider trading lub awarii sprzętu, a może po prostu mają "skok" co N-ta liczba podobnie jak w przypadku analizy sił po katastrofie, można znacznie zmniejszyć liczbę rekordów, które trzeba sprawdzić.
I tak jest coś do przemyślenia. Może to pomoże Ci dać przyszłym rozmówcom przemyślaną odpowiedź. Wiem, że byłbym pod wrażeniem, gdyby ktoś zadał mi takie pytanie w odpowiedzi na taki problem - powiedziałby mi, że myśli o optymalizacji. Wystarczy zauważyć, że nie zawsze może być możliwość optymalizacji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-08 20:33:55
Time ~ O(100 * N)
Space ~ O(100 + N)
-
Tworzenie pustej listy 100 pustych slotów
-
Dla każdej liczby w input-list:
-
Jeśli liczba jest mniejsza od pierwszej, pomiń
-
W przeciwnym razie zastąp go tą liczbą
-
Następnie przepchnij numer przez sąsiadujący swap; aż będzie mniejszy niż następny
-
-
Return the list
Uwaga: Jeśli log(input-list.size) + c < 100, to optymalnym sposobem jest sortowanie input-list, a następnie podzielić pierwsze 100 pozycji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 06:24:28
Złożoność jest O (N)
Najpierw Utwórz tablicę 100 ints inicjując pierwszy element tej tablicy jako pierwszy element wartości N, śledzenie indeksu bieżącego elementu za pomocą innej zmiennej, nazwij ją CurrentBig
Iteratuj chociaż wartości N
if N[i] > M[CurrentBig] {
M[CurrentBig]=N[i]; ( overwrite the current value with the newly found larger number)
CurrentBig++; ( go to the next position in the M array)
CurrentBig %= 100; ( modulo arithmetic saves you from using lists/hashes etc.)
M[CurrentBig]=N[i]; ( pick up the current value again to use it for the next Iteration of the N array)
}
Po zakończeniu wydrukuj tablicę M Z CurrentBig 100 razy modulo 100 :-) Dla ucznia: upewnij się, że ostatnia linia kodu nie przebija ważnych danych tuż przed zakończeniem kodu
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 08:42:24
Inny algorytm O(n) -
Algorytm wyszukuje największą 100 przez eliminację
Rozważmy wszystkie miliony liczb w ich reprezentacji binarnej. Zacznij od najważniejszego bitu. Stwierdzenie, czy MSB jest równe 1, może być wykonane przez mnożenie operacji boolowskiej z odpowiednią liczbą. Jeśli w tych milionach jest więcej niż 100 jedynek, wyeliminuj pozostałe liczby z zerami. Teraz z pozostałych numerów przejść do następnego najbardziej znaczącego bitu. zachowaj licznik liczba pozostałych numerów po eliminacji i kontynuować tak długo, jak liczba ta jest większa niż 100.
Główna operacja logiczna może być wykonywana równolegle na GPU
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 12:56:53
Dowiedziałbym się, kto miał czas, aby umieścić miliard cyfr w tablicy i zwolnić go. Musi pracować dla rządu. Przynajmniej jeśli masz połączoną listę, możesz wstawić liczbę do środka bez przesuwania pół miliarda, aby zrobić miejsce. Jeszcze lepiej Btree pozwala na wyszukiwanie binarne. Każde porównanie eliminuje połowę Twojej sumy. Algorytm hash pozwalałby wypełniać strukturę danych jak szachownicę, ale nie tak dobrze dla rzadkich danych. Jak to jest najlepszym rozwiązaniem jest mieć rozwiązanie tablica 100 liczb całkowitych i śledź najniższą liczbę w tablicy rozwiązania, dzięki czemu możesz ją zastąpić, gdy natkniesz się na wyższą liczbę w oryginalnej tablicy. Trzeba by przyjrzeć się każdemu elementowi w oryginalnej tablicy, zakładając, że nie jest on posortowany.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 15:11:46
Możesz to zrobić w O(n) czasie. Wystarczy przejrzeć listę i śledzić 100 największych liczb, które widziałeś w danym momencie i minimalną wartość w tej grupie. Gdy znajdziesz nową liczbę większą niż najmniejsza z dziesięciu, zastąp ją i zaktualizuj nową minimalną wartość 100 (może to zająć stały czas 100, aby ustalić tę wartość za każdym razem, ale nie ma to wpływu na ogólną analizę).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 15:37:35
- Użyj n-tego elementu, aby uzyskać 100-ty element O (n)
- powtarza drugi raz, ale tylko raz i wyświetla każdy element, który jest większy od tego konkretnego elementu.
Zwróć uwagę na esp. drugi krok może być łatwy do obliczenia równolegle! Sprawnie sprawdzi się również wtedy, gdy potrzebujesz miliona największych elementów.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-11 08:01:42
[1]}to pytanie od Google lub innych gigantów branży.Być może poniższy kod jest właściwą odpowiedzią oczekiwaną przez rozmówcę. Koszt czasu i koszt przestrzeni zależą od maksymalnej liczby w tablicy wejściowej.Dla 32-bitowego wejścia tablicy int maksymalny koszt przestrzeni wynosi 4 * 125m bajtów, koszt czasu wynosi 5 * miliardów.
public class TopNumber {
public static void main(String[] args) {
final int input[] = {2389,8922,3382,6982,5231,8934
,4322,7922,6892,5224,4829,3829
,6892,6872,4682,6723,8923,3492};
//One int(4 bytes) hold 32 = 2^5 value,
//About 4 * 125M Bytes
//int sort[] = new int[1 << (32 - 5)];
//Allocate small array for local test
int sort[] = new int[1000];
//Set all bit to 0
for(int index = 0; index < sort.length; index++){
sort[index] = 0;
}
for(int number : input){
sort[number >>> 5] |= (1 << (number % 32));
}
int topNum = 0;
outer:
for(int index = sort.length - 1; index >= 0; index--){
if(0 != sort[index]){
for(int bit = 31; bit >= 0; bit--){
if(0 != (sort[index] & (1 << bit))){
System.out.println((index << 5) + bit);
topNum++;
if(topNum >= 3){
break outer;
}
}
}
}
}
}
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-16 12:20:29
Zrobiłem swój własny kod, Nie wiem, czy to, co" ankieter " to wygląda
private static final int MAX=100;
PriorityQueue<Integer> queue = new PriorityQueue<>(MAX);
queue.add(array[0]);
for (int i=1;i<array.length;i++)
{
if(queue.peek()<array[i])
{
if(queue.size() >=MAX)
{
queue.poll();
}
queue.add(array[i]);
}
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-05-11 21:04:20
Możliwe ulepszenia.
Jeśli plik zawiera 1 miliardową liczbę, odczyt może być naprawdę długi...
Aby usprawnić tę pracę możesz:
- podziel plik Na n części, Utwórz n wątków, spraw, aby N wątków szukało 100 największych liczb w swojej części pliku (używając kolejki priorytetów), a na koniec uzyskaj 100 największych liczb ze wszystkich wątków wyjściowych.
- użyj klastra do wykonania takiego zadania, z rozwiązaniem takim jak hadoop. Proszę. możesz podzielić plik jeszcze bardziej i uzyskać szybsze wyjście dla pliku liczb 1 miliarda (lub 10^12).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-08-02 01:27:32
Ten kod służy do znajdowania N największych liczb w Nieposortowana tablica.
#include <iostream>
using namespace std;
#define Array_Size 5 // No Of Largest Numbers To Find
#define BILLION 10000000000
void findLargest(int max[], int array[]);
int checkDup(int temp, int max[]);
int main() {
int array[BILLION] // contains data
int i=0, temp;
int max[Array_Size];
findLargest(max,array);
cout<< "The "<< Array_Size<< " largest numbers in the array are: \n";
for(i=0; i< Array_Size; i++)
cout<< max[i] << endl;
return 0;
}
void findLargest(int max[], int array[])
{
int i,temp,res;
for(int k=0; k< Array_Size; k++)
{
i=0;
while(i < BILLION)
{
for(int j=0; j< Array_Size ; j++)
{
temp = array[i];
res= checkDup(temp,max);
if(res == 0 && max[j] < temp)
max[j] = temp;
}
i++;
}
}
}
int checkDup(int temp, int max[])
{
for(int i=0; i<N_O_L_N_T_F; i++)
{
if(max[i] == temp)
return -1;
}
return 0;
}
Hope this helps
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 16:00:18
Wiem, że to może zostać Zakopane, ale oto mój pomysł na odmianę radix MSD.
pseudo-code:
//billion is the array of 1 billion numbers
int[] billion = getMyBillionNumbers();
//this assumes these are 32-bit integers and we are using hex digits
int[][] mynums = int[8][16];
for number in billion
putInTop100Array(number)
function putInTop100Array(number){
//basically if we got past all the digits successfully
if(number == null)
return true;
msdIdx = getMsdIdx(number);
msd = getMsd(number);
//check if the idx above where we are is already full
if(mynums[msdIdx][msd+1] > 99) {
return false;
} else if(putInTop100Array(removeMSD(number)){
mynums[msdIdx][msd]++;
//we've found 100 digits here, no need to keep looking below where we are
if(mynums[msdIdx][msd] > 99){
for(int i = 0; i < mds; i++){
//making it 101 just so we can tell the difference
//between numbers where we actually found 101, and
//where we just set it
mynums[msdIdx][i] = 101;
}
}
return true;
}
return false;
}
Funkcja getMsdIdx(int num) zwróci indeks największej cyfry (niezerowej). Funkcja getMsd(int num) zwróci największą cyfrę. Funkcja removeMSD(int num) usuwa najważniejszą cyfrę z Liczby i zwraca liczbę (lub zwraca null, jeśli po usunięciu najważniejszej cyfry nic nie pozostało).
Kiedy to się skończy, wszystko co zostanie przemierza mynums, aby pobrać pierwsze 100 cyfr. To byłoby coś w stylu:
int[] nums = int[100];
int idx = 0;
for(int i = 7; i >= 0; i--){
int timesAdded = 0;
for(int j = 16; j >=0 && timesAdded < 100; j--){
for(int k = mynums[i][j]; k > 0; k--){
nums[idx] += j;
timesAdded++;
idx++;
}
}
}
Powinienem zauważyć, że chociaż powyższe wygląda na to, że ma wysoką złożoność czasową, tak naprawdę będzie to tylko wokół O(7*100).
Szybkie wyjaśnienie, co to próbuje zrobić: Zasadniczo ten system próbuje użyć każdej cyfry w tablicy 2d na podstawie indeksu cyfry w liczbie i jej wartości. Używa ich jako indeksów, aby śledzić, ile liczb tej wartości zostało / align = "left" / Po osiągnięciu 100 zamyka wszystkie "dolne gałęzie".
Czas tego algorytmu jest czymś w rodzaju O(billion*log(16)*7)+O(100). Mogę się mylić. Jest również bardzo prawdopodobne, że wymaga to debugowania, ponieważ jest to dość skomplikowane i po prostu napisałem to z czubka głowy.
EDIT: Downvoty bez wyjaśnienia nie są pomocne. Jeśli uważasz, że ta odpowiedź jest nieprawidłowa, zostaw komentarz dlaczego. Jestem pewien, że StackOverflow nawet każe ci to zrobić, gdy głosy przeciw:
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 16:00:34
Zarządzanie oddzielną listą jest dodatkową pracą i musisz przesuwać rzeczy po całej liście za każdym razem, gdy znajdziesz innego zastępcę. Wystarczy qsort to i wziąć top 100.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-09 16:32:56