Bezpośrednie pobieranie z Dysku Google za pomocą interfejsu API Dysku Google
Moja aplikacja desktopowa, napisana w Javie, próbuje pobrać Publiczne pliki z Dysku Google. Jak się dowiedziałem, można go zaimplementować za pomocą pliku webContentLink (chodzi o możliwość pobierania plików publicznych bez autoryzacji użytkownika).
Tak więc poniższy kod działa z małymi plikami:
String webContentLink = aFile.getWebContentLink();
InputStream in = new URL(webContentLink).openStream();
Ale to nie działa na dużych plikach, ponieważ w tym przypadku plik nie może być pobrany bezpośrednio przez webContentLink bez potwierdzenia użytkownika z ostrzeżeniem skanowania antywirusowego google. Zobacz przykład: web content link .
Więc moje pytanie brzmi, jak uzyskać zawartość publicznego pliku z Dysku Google bez autoryzacji użytkownika?
11 answers
Aktualizacja 8 grudnia 2015 Według Google Support za pomocą
googledrive.com/host/ID
Metoda zostanie wyłączona 31 sierpnia 2016.
Właśnie natknąłem się na ten problem.
Sztuczka polega na traktowaniu folderu dysku Google jak hosta internetowego.
Aktualizacja 1 kwietnia, 2015
Dysk Google się zmienił i istnieje prosty sposób na bezpośrednie połączenie z dyskiem. Zostawiłem moje poprzednie Odpowiedzi poniżej w celach informacyjnych, ale tutaj jest zaktualizowana odpowiedź.
- Utwórz folder publiczny na Dysku Google.
- Udostępnij ten dysk publicznie.
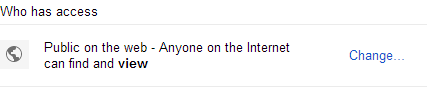
- Pobierz uuid folderu z paska adresu, gdy jesteś w tym folderze

- Umieść ten UUID w tym adresie URL
https://googledrive.com/host/<folder UUID>/ - Dodaj nazwę pliku do miejsca, w którym znajduje się plik.
https://googledrive.com/host/<folder UUID>/<file name>
który jest przeznaczony przez Google
nowy Link do Dysku Google .
Wszystko, co musisz zrobić, to uzyskać adres URL hosta dla publicznie udostępnionego folderu dysku. Aby to zrobić, możesz przesłać zwykły plik HTML i podgląd na Dysku Google, aby znaleźć adres URL hosta.
Oto kroki:
- Utwórz folder na Dysku Google.
- Udostępnij ten dysk publicznie.
- Prześlij prosty plik HTML. Dodaj dodatkowe pliki (podfoldery ok)

- Otwórz i" podgląd " pliku HTML na Dysku Google
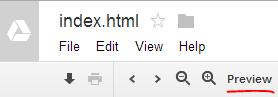
- Pobierz adres URL tego folderu

- Utwórz adres URL bezpośredniego łącza z bazy folderów URL

- Ten adres URL powinien umożliwiać bezpośrednie pobieranie dużych plików.
[edytuj]
Zapomniałem dodać. Jeśli używasz podfolderów do organizowania swoich pliki, po prostu używasz nazwy folderu tak, jak można się spodziewać w hierarchii URL.https://googledrive.com/host/<your public folders id string>/images/my-image.png
What I was looking to do
Stworzyłem niestandardowy obraz Debiana z Virtual Box Dla Vagrant. Chciałem się tym podzielić".box " Plik z kolegami, aby mogli umieścić bezpośredni link do ich Vagrantfile.
W końcu potrzebowałem bezpośredniego linku do aktualnego pliku.
Problem z Dyskiem Google
Jeśli ustawisz uprawnienia do pliku na aby uzyskać dostęp do Internetu, należy użyć narzędzia gdocs2direct (10) lub stworzyć link bezpośrednio do niego:
https://docs.google.com/uc?export=download&id=<your file id>
Otrzymasz kod weryfikacyjny oparty na plikach cookie i monit "Google nie może zeskanować tego pliku", który nie będzie działał dla takich rzeczy, jak wget lub vagrantfile configs.
Kod, który generuje jest prostym kodem, który dołącza zmienną zapytania GET ...&confirm=### do łańcucha znaków, ale jest specyficzny dla użytkownika, więc to nie jest tak, że można skopiować/wkleić tę zmienną zapytania dla innych.
Ale jeśli używasz powyższej metody "hosting stron internetowych", możesz ominąć ten monit.
Mam nadzieję, że to pomoże!Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-12-08 19:59:05
Jeśli pojawi się strona "Ten plik nie może być sprawdzony pod kątem wirusów", pobieranie nie jest takie proste.
Zasadniczo musisz najpierw pobrać normalny link do pobrania, który jednak przekieruje Cię do strony" Pobierz mimo to". Musisz przechowywać pliki cookie z tego pierwszego żądania, znaleźć link wskazywany przez przycisk" Pobierz mimo to", a następnie użyć tego linku, aby pobrać plik, ale ponownie używając plików cookie, które otrzymałeś od pierwszego żądania.
Oto bash wariant procesu pobierania za pomocą CURL:
curl -c /tmp/cookies "https://drive.google.com/uc?export=download&id=DOCUMENT_ID" > /tmp/intermezzo.html
curl -L -b /tmp/cookies "https://drive.google.com$(cat /tmp/intermezzo.html | grep -Po 'uc-download-link" [^>]* href="\K[^"]*' | sed 's/\&/\&/g')" > FINAL_DOWNLOADED_FILENAME
Uwagi:
- ta procedura prawdopodobnie przestanie działać po pewnych zmianach w Google
- polecenie grep używa składni Perla (
-P) i\K"operator", co zasadniczo oznacza " nie dołączaj niczego poprzedzającego\Kdo dopasowanego wyniku. Nie wiem, która wersja grepa wprowadziła te opcje, ale wersje starożytne lub nie-Ubuntu prawdopodobnie ich nie mają - rozwiązanie Java byłoby mniej więcej to samo, po prostu weź bibliotekę HTTPS, która może obsługiwać pliki cookie, i jakąś ładną bibliotekę analizowania tekstu
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-09-23 14:44:29
To wydaje się być aktualizowane ponownie od maja 19, 2015:
Jak to działa:
Jak w ostatnio zaktualizowanej odpowiedzi jmbertucciego, upublicznij swój folder wszystkim. Jest to nieco bardziej skomplikowane niż wcześniej, musisz kliknąć Zaawansowane, aby zmienić folder na " ON-Public w Internecie."Znajdź swój uuid folderu jak wcześniej--po prostu wejdź do folderu i znajdź swój UUID w pasku adresu:
https://drive.google.com/drive/folders/<folder UUID>
Następnie udaj się do
https://googledrive.com/host/<folder UUID>
Przekieruje Cię do indeks typ strony z gigantyczną subdomeną, ale powinieneś być w stanie zobaczyć pliki w folderze. Następnie możesz kliknąć prawym przyciskiem myszy, aby zapisać link do pliku, który chcesz (zauważyłem, że ten bezpośredni link ma również tę dużą subdomenę dla googledrive.com). Świetnie mi poszło z wget.
Wygląda na to, że działa to również z folderami współdzielonymi innych osób.
Np.,
Https://drive.google.com/folderview?id=0B7l10Bj_LprhQnpSRkpGMGV2eE0&usp=sharing
Mapy do
Https://googledrive.com/host/0B7l10Bj_LprhQnpSRkpGMGV2eE0
I kliknięcie prawym przyciskiem myszy może zapisać bezpośredni link do dowolnego z tych plików.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-05-19 19:01:20
wiem, że to stare pytanie, ale nie mogłem znaleźć rozwiązania tego problemu po pewnych badaniach, więc dzielę się tym, co działało dla mnie.
Napisałem ten kod C# dla jednego z moich projektów. Może programowo ominąć ostrzeżenie o wirusie skanowania. Kod można prawdopodobnie przekonwertować na Javę.
using System;
using System.IO;
using System.Net;
public static class FileDownloader
{
private const string GOOGLE_DRIVE_DOMAIN = "drive.google.com";
private const string GOOGLE_DRIVE_DOMAIN2 = "https://drive.google.com";
// Normal example: FileDownloader.DownloadFileFromURLToPath( "http://example.com/file/download/link", @"C:\file.txt" );
// Drive example: FileDownloader.DownloadFileFromURLToPath( "http://drive.google.com/file/d/FILEID/view?usp=sharing", @"C:\file.txt" );
public static FileInfo DownloadFileFromURLToPath( string url, string path )
{
if( url.StartsWith( GOOGLE_DRIVE_DOMAIN ) || url.StartsWith( GOOGLE_DRIVE_DOMAIN2 ) )
return DownloadGoogleDriveFileFromURLToPath( url, path );
else
return DownloadFileFromURLToPath( url, path, null );
}
private static FileInfo DownloadFileFromURLToPath( string url, string path, WebClient webClient )
{
try
{
if( webClient == null )
{
using( webClient = new WebClient() )
{
webClient.DownloadFile( url, path );
return new FileInfo( path );
}
}
else
{
webClient.DownloadFile( url, path );
return new FileInfo( path );
}
}
catch( WebException )
{
return null;
}
}
// Downloading large files from Google Drive prompts a warning screen and
// requires manual confirmation. Consider that case and try to confirm the download automatically
// if warning prompt occurs
private static FileInfo DownloadGoogleDriveFileFromURLToPath( string url, string path )
{
// You can comment the statement below if the provided url is guaranteed to be in the following format:
// https://drive.google.com/uc?id=FILEID&export=download
url = GetGoogleDriveDownloadLinkFromUrl( url );
using( CookieAwareWebClient webClient = new CookieAwareWebClient() )
{
FileInfo downloadedFile;
// Sometimes Drive returns an NID cookie instead of a download_warning cookie at first attempt,
// but works in the second attempt
for( int i = 0; i < 2; i++ )
{
downloadedFile = DownloadFileFromURLToPath( url, path, webClient );
if( downloadedFile == null )
return null;
// Confirmation page is around 50KB, shouldn't be larger than 60KB
if( downloadedFile.Length > 60000 )
return downloadedFile;
// Downloaded file might be the confirmation page, check it
string content;
using( var reader = downloadedFile.OpenText() )
{
// Confirmation page starts with <!DOCTYPE html>, which can be preceeded by a newline
char[] header = new char[20];
int readCount = reader.ReadBlock( header, 0, 20 );
if( readCount < 20 || !( new string( header ).Contains( "<!DOCTYPE html>" ) ) )
return downloadedFile;
content = reader.ReadToEnd();
}
int linkIndex = content.LastIndexOf( "href=\"/uc?" );
if( linkIndex < 0 )
return downloadedFile;
linkIndex += 6;
int linkEnd = content.IndexOf( '"', linkIndex );
if( linkEnd < 0 )
return downloadedFile;
url = "https://drive.google.com" + content.Substring( linkIndex, linkEnd - linkIndex ).Replace( "&", "&" );
}
downloadedFile = DownloadFileFromURLToPath( url, path, webClient );
return downloadedFile;
}
}
// Handles 3 kinds of links (they can be preceeded by https://):
// - drive.google.com/open?id=FILEID
// - drive.google.com/file/d/FILEID/view?usp=sharing
// - drive.google.com/uc?id=FILEID&export=download
public static string GetGoogleDriveDownloadLinkFromUrl( string url )
{
int index = url.IndexOf( "id=" );
int closingIndex;
if( index > 0 )
{
index += 3;
closingIndex = url.IndexOf( '&', index );
if( closingIndex < 0 )
closingIndex = url.Length;
}
else
{
index = url.IndexOf( "file/d/" );
if( index < 0 ) // url is not in any of the supported forms
return string.Empty;
index += 7;
closingIndex = url.IndexOf( '/', index );
if( closingIndex < 0 )
{
closingIndex = url.IndexOf( '?', index );
if( closingIndex < 0 )
closingIndex = url.Length;
}
}
return string.Format( "https://drive.google.com/uc?id={0}&export=download", url.Substring( index, closingIndex - index ) );
}
}
// Web client used for Google Drive
public class CookieAwareWebClient : WebClient
{
private class CookieContainer
{
Dictionary<string, string> _cookies;
public string this[Uri url]
{
get
{
string cookie;
if( _cookies.TryGetValue( url.Host, out cookie ) )
return cookie;
return null;
}
set
{
_cookies[url.Host] = value;
}
}
public CookieContainer()
{
_cookies = new Dictionary<string, string>();
}
}
private CookieContainer cookies;
public CookieAwareWebClient() : base()
{
cookies = new CookieContainer();
}
protected override WebRequest GetWebRequest( Uri address )
{
WebRequest request = base.GetWebRequest( address );
if( request is HttpWebRequest )
{
string cookie = cookies[address];
if( cookie != null )
( (HttpWebRequest) request ).Headers.Set( "cookie", cookie );
}
return request;
}
protected override WebResponse GetWebResponse( WebRequest request, IAsyncResult result )
{
WebResponse response = base.GetWebResponse( request, result );
string[] cookies = response.Headers.GetValues( "Set-Cookie" );
if( cookies != null && cookies.Length > 0 )
{
string cookie = "";
foreach( string c in cookies )
cookie += c;
this.cookies[response.ResponseUri] = cookie;
}
return response;
}
protected override WebResponse GetWebResponse( WebRequest request )
{
WebResponse response = base.GetWebResponse( request );
string[] cookies = response.Headers.GetValues( "Set-Cookie" );
if( cookies != null && cookies.Length > 0 )
{
string cookie = "";
foreach( string c in cookies )
cookie += c;
this.cookies[response.ResponseUri] = cookie;
}
return response;
}
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-01-27 05:51:05
Korzystanie z konta usługi może Ci się udać.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-12-19 06:58:38
#Przypadek 1: Pobierz plik o małym rozmiarze.
- możesz użyć url z formatem https://drive.google.com/uc?export=download&id=FILE_ID {[11] } a następnie strumień wejściowy pliku można uzyskać bezpośrednio.
#Przypadek 2: pobierz plik o dużym rozmiarze.
-
/ Align = "left" / Analizując element html dom, próbowałem uzyskać link z kodem potwierdzającym pod przyciskiem "Pobierz mimo to", ale nie zadziałało. Its może wymagane informacje o plikach cookie lub sesji.
wpisz tutaj opis obrazu
{kind=link}
Rozwiązanie:
-
W końcu znalazłem rozwiązanie dla dwóch powyższych przypadków. Wystarczy umieścić
httpConnection.setDoOutput(true)w kroku połączenia, aby uzyskać Json.)]}' { "disposition":"SCAN_CLEAN", "downloadUrl":"http:www...", "fileName":"exam_list_json.txt", "scanResult":"OK", "sizeBytes":2392}
Następnie możesz użyć dowolnego parsera Json, aby odczytać downloadUrl, fileName i sizeBytes.
-
Możesz polecić follow snippet, mam nadzieję, że to pomoże.
private InputStream gConnect(String remoteFile) throws IOException{ URL url = new URL(remoteFile); URLConnection connection = url.openConnection(); if(connection instanceof HttpURLConnection){ HttpURLConnection httpConnection = (HttpURLConnection) connection; connection.setAllowUserInteraction(false); httpConnection.setInstanceFollowRedirects(true); httpConnection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows 2000)"); httpConnection.setDoOutput(true); httpConnection.setRequestMethod("GET"); httpConnection.connect(); int reqCode = httpConnection.getResponseCode(); if(reqCode == HttpURLConnection.HTTP_OK){ InputStream is = httpConnection.getInputStream(); Map<String, List<String>> map = httpConnection.getHeaderFields(); List<String> values = map.get("content-type"); if(values != null && !values.isEmpty()){ String type = values.get(0); if(type.contains("text/html")){ String cookie = httpConnection.getHeaderField("Set-Cookie"); String temp = Constants.getPath(mContext, Constants.PATH_TEMP) + "/temp.html"; if(saveGHtmlFile(is, temp)){ String href = getRealUrl(temp); if(href != null){ return parseUrl(href, cookie); } } } else if(type.contains("application/json")){ String temp = Constants.getPath(mContext, Constants.PATH_TEMP) + "/temp.txt"; if(saveGJsonFile(is, temp)){ FileDataSet data = JsonReaderHelper.readFileDataset(new File(temp)); if(data.getPath() != null){ return parseUrl(data.getPath()); } } } } return is; } } return null; }
I
public static FileDataSet readFileDataset(File file) throws IOException{
FileInputStream is = new FileInputStream(file);
JsonReader reader = new JsonReader(new InputStreamReader(is, "UTF-8"));
reader.beginObject();
FileDataSet rs = new FileDataSet();
while(reader.hasNext()){
String name = reader.nextName();
if(name.equals("downloadUrl")){
rs.setPath(reader.nextString());
} else if(name.equals("fileName")){
rs.setName(reader.nextString());
} else if(name.equals("sizeBytes")){
rs.setSize(reader.nextLong());
} else {
reader.skipValue();
}
}
reader.endObject();
return rs;
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-03-17 04:32:32
Rozważyłbym pobranie z linku, zeskrobanie strony, którą można pobrać link potwierdzający, a następnie pobranie tego.
Jeśli spojrzysz na adres URL "Pobierz mimo to", ma on dodatkowy parametr zapytania confirm z pozornie losowo wygenerowanym tokenem. Skoro to przypadek...i prawdopodobnie nie chcesz dowiedzieć się, jak samemu go wygenerować, skrobanie może być najłatwiejszym sposobem, nie wiedząc nic o tym, jak działa strona.
Być może będziesz musiał rozważyć różne scenariusze.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-12-18 22:20:01
Jeśli po prostu chcesz programowo (w przeciwieństwie do podania użytkownikowi linku do otwarcia w przeglądarce) pobrać plik za pośrednictwem interfejsu API Dysku Google, sugerowałbym użycie downloadUrl pliku zamiast webContentLink, Jak to udokumentowano tutaj: https://developers.google.com/drive/web/manage-downloads
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-06-16 10:24:04
Https://github.com/google/skicka
Użyłem tego narzędzia wiersza poleceń do pobierania plików z Dysku Google. Wystarczy postępować zgodnie z instrukcjami w sekcji pierwsze kroki, aby pobrać pliki z Dysku Google w kilka minut.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-03-22 10:19:32
Https://drive.google.com/uc?export=download&id=FILE_ID zastąp FILE_ID id pliku.
Jeśli nie wiesz gdzie jest ID pliku to sprawdź ten artykuł link do artykułu
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-01-27 11:20:53
Po prostu tworzę javascript tak, aby automatycznie przechwytywał link i pobierał i zamykał kartę za pomocą tampermonkey.
// ==UserScript==
// @name Bypass Google drive virus scan
// @namespace SmartManoj
// @version 0.1
// @description Quickly get the download link
// @author SmartManoj
// @match https://drive.google.com/uc?id=*&export=download*
// @grant none
// ==/UserScript==
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function demo() {
await sleep(5000);
window.close();
}
(function() {
location.replace(document.getElementById("uc-download-link").href);
demo();
})();
Podobnie można uzyskać źródło html adresu url i pobrać w Javie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-04-27 00:18:08