boost:: płaska mapa i jej wydajność w porównaniu z mapą i mapą nieuporządkowaną
Powszechnie wiadomo w programowaniu, że lokalizacja pamięci znacznie poprawia wydajność z powodu trafień w pamięci podręcznej. Niedawno dowiedziałem się o boost::flat_map, która jest implementacją mapy wektorowej. Nie wydaje się być tak popularny jak typowy map/unordered_map więc nie udało mi się znaleźć żadnych porównań wydajności. Jak to porównać i jakie są najlepsze przypadki użycia dla niego?
2 answers
Przeprowadziłem ostatnio test porównawczy różnych struktur danych w mojej firmie, więc czuję, że muszę rzucić słowo. To bardzo skomplikowane, aby porównać coś poprawnie.
Benchmarking
W sieci rzadko znajdujemy (jeśli w ogóle) dobrze zaprojektowany benchmark. Do dzisiaj znalazłem tylko benchmarki, które zostały wykonane w sposób dziennikarski (dość szybko i zamiatając dziesiątki zmiennych pod dywan).
1) musisz wziąć pod uwagę pamięć podręczną ocieplenie
Większość ludzi uruchamiających benchmarki boi się rozbieżności czasowej, dlatego uruchamiają swoje rzeczy tysiące razy i zajmują cały czas, po prostu są ostrożni, aby wziąć ten sam tysiąc razy dla każdej operacji, a następnie uważają, że porównywalne.
Prawda jest taka, że w prawdziwym świecie to nie ma sensu, ponieważ twoja pamięć podręczna nie będzie ciepła, a Twoja operacja prawdopodobnie zostanie wywołana tylko raz. Dlatego trzeba benchmark za pomocą RDTSC, i rzeczy czasu nazywając je tylko raz. Intel sporządził papier opisujący Jak używać rdtsc (używając instrukcji cpuid do przepłukania potoku i wywołując go co najmniej 3 razy na początku programu, aby go ustabilizować).2) miara dokładności RDTSC
Polecam również zrobić to:
u64 g_correctionFactor; // number of clocks to offset after each measurement to remove the overhead of the measurer itself.
u64 g_accuracy;
static u64 const errormeasure = ~((u64)0);
#ifdef _MSC_VER
#pragma intrinsic(__rdtsc)
inline u64 GetRDTSC()
{
int a[4];
__cpuid(a, 0x80000000); // flush OOO instruction pipeline
return __rdtsc();
}
inline void WarmupRDTSC()
{
int a[4];
__cpuid(a, 0x80000000); // warmup cpuid.
__cpuid(a, 0x80000000);
__cpuid(a, 0x80000000);
// measure the measurer overhead with the measurer (crazy he..)
u64 minDiff = LLONG_MAX;
u64 maxDiff = 0; // this is going to help calculate our PRECISION ERROR MARGIN
for (int i = 0; i < 80; ++i)
{
u64 tick1 = GetRDTSC();
u64 tick2 = GetRDTSC();
minDiff = Aska::Min(minDiff, tick2 - tick1); // make many takes, take the smallest that ever come.
maxDiff = Aska::Max(maxDiff, tick2 - tick1);
}
g_correctionFactor = minDiff;
printf("Correction factor %llu clocks\n", g_correctionFactor);
g_accuracy = maxDiff - minDiff;
printf("Measurement Accuracy (in clocks) : %llu\n", g_accuracy);
}
#endif
Jest to miernik rozbieżności, który zajmie minimum wszystkich zmierzonych wartości, aby uniknąć uzyskania -10 * * 18 (64-bitowe pierwsze wartości ujemne) od czasu do czas.
Zwróć uwagę na użycie elementów wewnętrznych, a nie wbudowanych. Pierwszy inline assembly jest obecnie rzadko obsługiwany przez kompilatory, ale co gorsza, kompilator tworzy pełną barierę porządkowania wokół wbudowanego assembly, ponieważ nie może statycznie analizować wnętrza, więc jest to problem do porównywania rzeczywistych rzeczy, szczególnie gdy wywołanie rzeczy tylko raz. Tak więc intrinsic nadaje się tutaj, ponieważ nie łamie kompilatora free-re-order instrukcji.
3) parametry
[17]}ostatnim problemem jest to, że ludzie zwykle testują zbyt mało wariantów scenariusza. Na wydajność kontenera ma wpływ:- alokator
- wielkość typu
- koszt wykonania operacji kopiowania, operacji cesji, operacji przenoszenia, operacji budowy, typu zamkniętego.
- liczba elementów w kontenerze (rozmiar problemu)
- typ ma trywialne 3.- operacje
- typ jest POD
Punkt 1 jest ważny, ponieważ kontenery przydzielają się od czasu do czasu i ma duże znaczenie, jeśli przydzielają za pomocą CRT "new" lub jakiejś operacji zdefiniowanej przez użytkownika, takiej jak alokacja puli, freelist lub inne...
(dla osób zainteresowanych pt 1, dołącz do tajemniczego wątku na gamedev o wpływie wydajności alokatora systemu )
Punkt 2 wynika z tego, że niektóre kontenery (powiedzmy A) tracą czas kopiowania rzeczy wokół, a im większy Typ im większe koszty. Problem polega na tym, że w porównaniu do innego kontenera B, A może wygrać z B dla małych typów, i luźne dla większych typów.
Punkt 3 jest taki sam jak punkt 2, z tym że mnoży koszt przez pewien czynnik ważący.
Punkt 4 to kwestia wielkiego O zmieszanego z problemami z pamięcią podręczną. Niektóre kontenery o złej złożoności mogą znacznie przewyższać kontenery o niskiej złożoności dla niewielkiej liczby typów (np. map vs. vector, ponieważ ich lokalizacja pamięci podręcznej jest dobra, ale map fragmentuje pamięć). A potem w pewnym punkcie krzyżowym stracą, ponieważ zawarty Całkowity rozmiar zaczyna "przeciekać" do pamięci głównej i powodować pudła pamięci podręcznej, to plus fakt, że asymptotyczna złożoność może zacząć być odczuwalna.
Punkt 5 mówi o tym, że Kompilatory są w stanie wymykać się rzeczy, które są puste lub trywialne w czasie kompilacji. Może to znacznie zoptymalizować niektóre operacje, ponieważ kontenery są szablonami, dlatego każdy typ będzie miał swoją własną wydajność profil.
Punkt 6 podobnie jak punkt 5, PODS mogą korzystać z faktu, że konstrukcja kopii jest tylko memcpy, a niektóre kontenery mogą mieć specyficzną implementację dla tych przypadków, używając częściowych specjalizacji szablonów, lub SFINAE do wyboru algorytmów zgodnie z cechami T.
O płaskiej mapie
Najwyraźniej płaska mapa jest sortowaną wektorową owijką, jak loki AssocVector, ale z pewnymi dodatkowymi modernizacjami w C++11, wykorzystującymi semantykę move do Przyspiesz wstawianie i usuwanie pojedynczych elementów.
To wciąż zamówiony kontener. Większość ludzi zazwyczaj nie potrzebuje części zamawiającej, dlatego istnienie unordered...
Rozważałeś, że może potrzebujesz flat_unorderedmap? czyli coś w stylu google::sparse_map lub coś w tym stylu-Mapa hashów otwartych adresów.
Problem map hashowych otwartych adresów polega na tym, że w momencie rehash muszą kopiować wszystko dookoła na nowy Rozszerzony płaski teren. Gdy standard Bez zamówienia mapa musi tylko odtworzyć indeks hash, ale przydzielone dane pozostają tam, gdzie są. Wadą jest oczywiście to, że pamięć jest rozdrobniona jak diabli.
Kryterium rekuperacji w mapie skrótu adresu otwartego jest wtedy, gdy pojemność przekracza rozmiar wektora łyżki pomnożony przez współczynnik obciążenia.
Typowym współczynnikiem obciążenia jest 0.8; dlatego musisz o to dbać, jeśli możesz wstępnie rozmiar mapy hash przed wypełnieniem, zawsze Pre-size do: intended_filling * (1/0.8) + epsilon to da ci gwarancja, że podczas napełniania nigdy nie będziesz musiał gwałtownie odświeżać i ponownie kopiować wszystkiego.
Zaletą zamkniętych map adresowych (std::unordered..) jest to, że nie musisz przejmować się tymi parametrami.
Ale boost::flat_map jest wektorem uporządkowanym, dlatego zawsze będzie miał złożoność asymptotyczną log(N), która jest mniej dobra niż Mapa hashowa adresu otwartego (zamortyzowana stała czasu). To też powinieneś rozważyć.
Wyniki porównawcze
Jest to test z udziałem różne mapy (z kluczem int i _ _ int64/somestruct jako wartością) i std:: vector.
Informacje o testowanych typach:
typeid=__int64 . sizeof=8 . ispod=yes
typeid=struct MediumTypePod . sizeof=184 . ispod=yes
Wstawianie
EDIT:
Moje poprzednie wyniki zawierały błąd: faktycznie testowali wstawianie uporządkowane, które wykazywało bardzo szybkie zachowanie dla płaskich map.
Zostawiłem te wyniki później na tej stronie, ponieważ są interesujące.
To jest prawidłowy test:
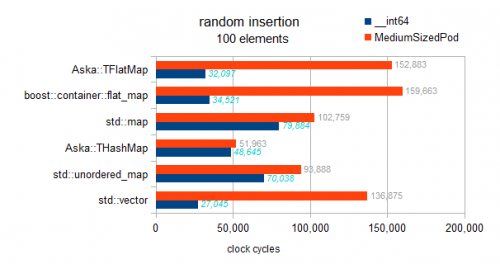
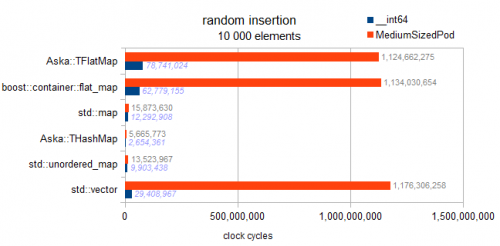
Mam sprawdziłem implementację, nie ma czegoś takiego jak odroczony rodzaj zaimplementowany w płaskich mapach tutaj. Każda wstawka sortuje się w locie, dlatego ten wzorzec wykazuje tendencje asymptotyczne:
Mapa: n * log (N)
hashmaps: amortyzowane N
vector and flatmaps : N * N
Warning: poniżej 2 testy dla std::mapi obu flat_mapS są buggy i faktycznie test uporządkowane wstawianie (vs losowe wstawianie dla innych kontenerów. tak to jest mylące przepraszam):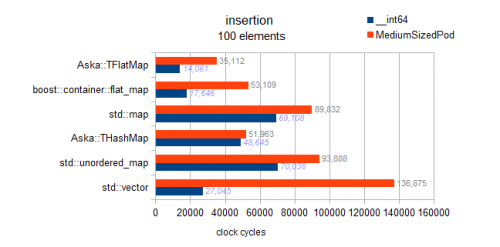
Widzimy, że uporządkowane wstawianie powoduje popychanie do tyłu i jest niezwykle szybkie. Jednak z nie wykresowych wyników mojego benchmarka mogę również powiedzieć, że nie jest to absolutna optymalność dla wstawiania wstecznego. Przy elementach 10k na wstępnie zarezerwowanym wektorze uzyskuje się doskonałą optymalność wstawiania wstecznego. Co daje nam 3 miliony cykli; obserwujemy tutaj 4,8 M dla uporządkowanego wstawiania do flat_map (dlatego 160% optymalne).
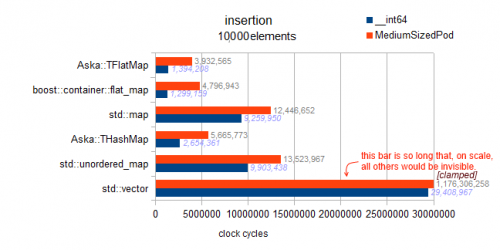 Analiza: pamiętaj, że jest to "losowa wstawka" dla wektora, więc masywny 1 miliard cykli wynika z konieczności przesunięcia o połowę (średnio) danych w górę (jeden element o jeden element) przy każdym wstawieniu.
Analiza: pamiętaj, że jest to "losowa wstawka" dla wektora, więc masywny 1 miliard cykli wynika z konieczności przesunięcia o połowę (średnio) danych w górę (jeden element o jeden element) przy każdym wstawieniu.
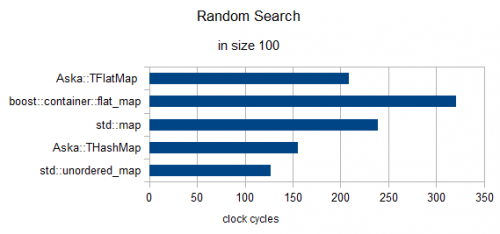
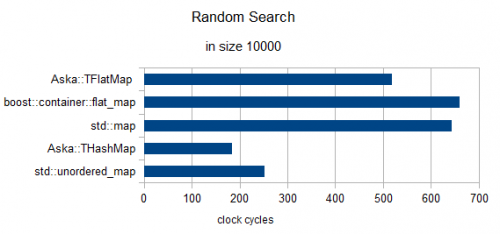
Losowe Wyszukiwanie 3 elementów (Zegary renormalizowane na 1)
In size = 100
In size = 10000
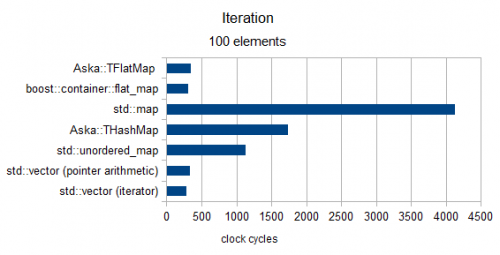
Iteracja
Powyżej rozmiaru 100 (tylko MediumPod Typ)
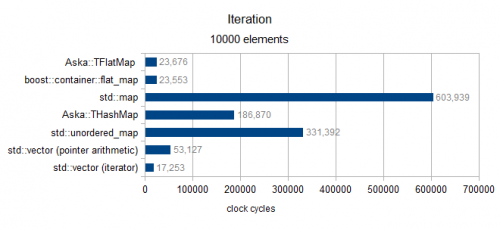
Ponad Rozmiar 10000 (tylko Typ MediumPod)
Końcowe ziarno soli
Na koniec chciałem wrócić do "Benchmarking §3 Pt1" (system allocator). W ostatnim eksperymencie, który prowadzę wokół wydajności otwartej mapy hashowej adresów, którą opracowuję , zmierzyłem lukę wydajności ponad 3000% między Windows 7 i Windows 8 na niektórych przypadkach std::unordered_map (omówione tutaj ).
Które chcę ostrzec czytelnika o powyższych wynikach (zostały wykonane na Win7); tak więc przebieg może się różnić.
Pozdrawiam
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-04-10 02:29:38
Z dokumentów wynika, że jest to analogiczne do Loki::AssocVector, którego jestem dość ciężkim użytkownikiem. Ponieważ opiera się na wektorze, ma cechy wektora, to znaczy:
- Iteratory są unieważniane, gdy
sizerośnie pozacapacity. - gdy wyrasta poza
capacity, musi się ponownie przydzielić i przesunąć obiekty, tzn. wstawianie nie jest gwarantowane w stałym czasie, z wyjątkiem specjalnego przypadku wstawiania wend, Gdycapacity > size - wyszukiwanie jest szybsze niż
std::mapze względu na Cache location, wyszukiwanie binarne, które ma takie same właściwości wydajności jakstd::mapinaczej - używa mniej pamięci, ponieważ nie jest połączonym drzewem binarnym
- nigdy się nie kurczy, chyba że zmusisz go do tego (ponieważ to wyzwala realokację)
Najlepiej używać, gdy znasz liczbę elementów z góry (dzięki czemu możesz reserve z góry ) lub gdy wstawianie / usuwanie jest rzadkie, ale wyszukiwanie jest częste. Unieważnienie iteratora sprawia, że jest to nieco uciążliwe w niektórych zastosowaniach przypadki więc nie są wymienne pod względem poprawności programu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-01-19 04:01:32