Jaki jest cel fazy tasowania i sortowania w reduktorze w programowaniu Map Reduce?
W programowaniu Map Reduce Faza reduce ma tasowanie, sortowanie i reduce jako swoje podczęści. Sortowanie to kosztowna sprawa.
Jaki jest cel fazy tasowania i sortowania w reduktorze w programowaniu Map Reduce?
9 answers
Przede wszystkim {[0] } jest to proces przesyłania danych z maperów do reduktorów, więc myślę, że jest oczywiste, że jest to konieczne dla reduktorów, ponieważ w przeciwnym razie nie byłyby one w stanie mieć żadnego wejścia (lub wejścia od każdego mapera). Tasowanie może rozpocząć się jeszcze przed zakończeniem fazy mapy, aby zaoszczędzić trochę czasu. Dlatego możesz zobaczyć status redukcji większy niż 0% (ale mniejszy niż 33%), gdy status mapy nie wynosi jeszcze 100%.
Sorting oszczędza czas na reduktor, pomagając mu łatwo odróżnić, kiedy powinno rozpocząć się nowe zadanie redukcji. Po prostu uruchamia nowe zadanie redukcji, gdy następny klucz w posortowanych danych wejściowych jest inny niż poprzedni, mówiąc prościej. Każde zadanie reduce pobiera listę par klucz-wartość, ale musi wywołać metodę reduce (), która pobiera dane wejściowe key-list(value), więc musi grupować wartości według klucza. Łatwo to zrobić, jeśli Dane wejściowe są wstępnie posortowane (lokalnie) w fazie map i po prostu scalają-posortowane w fazie reduction (ponieważ reduktory pobierają dane z wielu maperów).
Partitioning, to, o czym wspomniałeś w jednej z odpowiedzi, to inny proces. Określa, w którym reduktorze zostanie wysłana para (klucz, wartość), wyjście fazy mapy. Domyślny Partycjoner używa hashowania na kluczach, aby rozpowszechnić je w zadaniach redukcji, ale można go zastąpić i użyć własnego Partycjonera niestandardowego.
Doskonałym źródłem informacji dla tych kroków jest ten Yahoo tutorial .
Ładne graficzne przedstawienie tego jest following (shuffle na tym rysunku nazywa się "copy"):
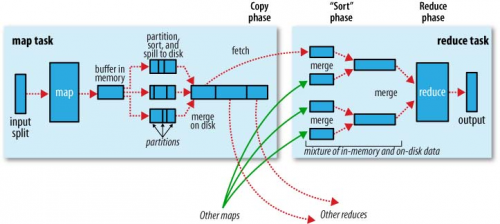
Zauważ, że shuffling i sorting nie są wykonywane w ogóle, Jeśli podasz zero reduktorów(setNumReduceTasks (0)). Następnie zadanie MapReduce zatrzymuje się na fazie map, a faza map nie obejmuje żadnego sortowania (więc nawet Faza map jest szybsza).
Aktualizacja: ponieważ szukasz czegoś bardziej oficjalnego, możesz również przeczytać książkę Toma White 'a"Hadoop: the Definitive Guide". tutaj jest interesująca część twojego pytania.
Tom White był Apache Hadoop committer od lutego 2007, i jest członkiem Apache Software Foundation, więc myślę, że jest to dość wiarygodne i oficjalne...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-21 09:21:03
Wróćmy do kluczowych faz programu Mapreduce.
Faza map jest wykonywana przez maperów. Mapery działają na nieposortowanych parach klucz/wartości wejściowych. Każdy maper emituje zero, jedną lub wiele par klucz/wartość wyjściowa dla każdej pary klucz/wartość wejściowa.
Faza łączenia jest wykonywana przez kombinatorów. Kombinator powinien łączyć pary klucz/wartość z tym samym kluczem. Każdy kombiner może działać zero, raz lub wiele razy.
The shuffle and sort phase odbywa się przez ramy. Dane ze wszystkich maperów są grupowane według klucza, dzielone między reduktory i sortowane według klucza. Każdy reduktor uzyskuje wszystkie wartości związane z tym samym kluczem. Programista może dostarczyć niestandardowe funkcje porównywania do sortowania i partycjonera do podziału danych.
Partycjoner decyduje, który reduktor otrzyma określoną parę wartości klucza.
Reduktor uzyskuje posortowane pary klucza/[lista wartości], posortowane według klucza. Lista wartości zawiera wszystkie wartości z tym samym kluczem produkowane przez maperów. Każdy reduktor emituje zero, jedną lub wiele par wyjściowych klucz/wartość dla każdej pary wejściowej klucz/wartość .
Aby dowiedzieć się więcej na temat javacodegeeks, przeczytaj artykuł Maria Jurcovicova i mssqltips Datta dla lepszego zrozumieniaPoniżej znajduje się obrazek z safaribooksonline Artykuł
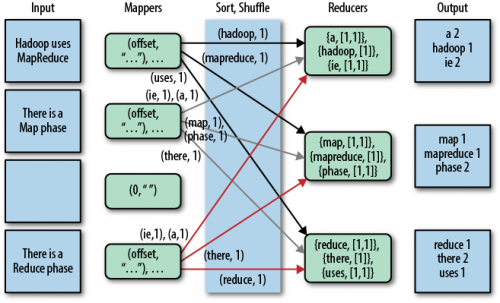
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-03-10 15:18:24
Pomyślałem o dodaniu kilku punktów brakujących w powyższych odpowiedziach. Ten diagram zaczerpnięty z tutaj jasno określa, co naprawdę się dzieje.
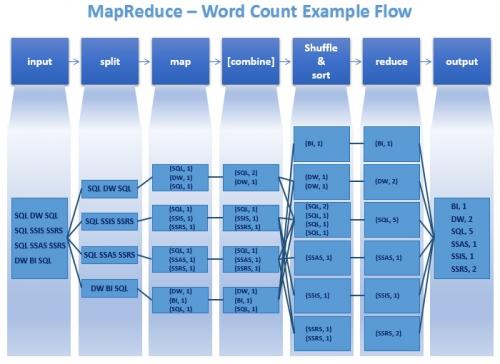
Jeśli ponownie stwierdzę prawdziwy cel
Split: poprawia przetwarzanie równoległe poprzez rozłożenie obciążenia przetwarzania na różne węzły (Mapery), co pozwala zaoszczędzić ogólny czas przetwarzania.
Połączenie: zmniejsza wyjście każdego Mapera. Zaoszczędziłoby to czas na przenoszenie danych z jednego węzła do drugiego.
Sort (Shuffle & Sort): ułatwia czas pracy, aby zaplanować (spawn / start) nowe reduktory, gdzie podczas przechodzenia przez Listę sortowanych elementów, gdy bieżący klucz różni się od poprzedniego, może wywołać nowy reduktor.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-08-01 04:33:31
Niektóre wymagania przetwarzania danych nie wymagają sortowania. Syncsort uczynił sortowanie w Hadoop pluggable. Tutaj {[2] } jest fajny blog od nich o sortowaniu. Proces przenoszenia danych z maperów do reduktorów nazywa się tasowaniem, sprawdź Ten artykuł , aby uzyskać więcej informacji na ten temat.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-03-04 12:18:50
Zawsze zakładałem, że jest to konieczne, ponieważ wyjście z mapera jest wejściem dla reduktora, więc zostało posortowane na podstawie przestrzeni kluczy, a następnie podzielone na wiadra dla każdego wejścia reduktora. Chcesz upewnić się, że wszystkie te same wartości klucza trafią do tego samego wiadra, które trafią do reduktora, aby zostały zmniejszone razem. Nie ma sensu wysyłać K1, V2 i K1, V4 do różnych reduktorów, ponieważ muszą być razem, aby je zmniejszyć.
Próbowałem wyjaśnić to tak prosto, jak to możliwe
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-03-03 09:04:55
Tasowanie jest procesem, w którym pośrednie dane z maperów są przesyłane do 0,1 lub więcej reduktorów. Każdy reduktor otrzymuje 1 lub więcej kluczy i związanych z nimi wartości w zależności od liczby reduktorów (dla równoważnego obciążenia). Następnie wartości związane z każdym kluczem są lokalnie sortowane.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-03-30 20:21:37
Istnieją tylko dwie rzeczy, które MapReduce robi natywnie: sortowanie i (zaimplementowane przez sortowanie) skalowalne GroupBy.
Większość aplikacji i wzorców projektowych nad MapReduce jest zbudowana na tych dwóch operacjach, które są dostarczane przez shuffle i sort.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-03-03 12:28:07
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-05-12 05:12:26
Dobrze, W Mapreduce są dwa ważne zwroty o nazwie Mapper i reducer oba są zbyt ważne, ale Reducer jest obowiązkowy. W niektórych programach reduktory są opcjonalne. Teraz przejdź do pytania. Tasowanie i sortowanie to dwie ważne operacje w Mapreduce. Pierwszy Framework Hadoop pobiera dane ustrukturyzowane/nieustrukturyzowane i oddziela dane na klucz, wartość.
Teraz program Mapper oddziela i porządkuje dane na klucze i wartości do przetworzenia. Wygeneruj Klucz 2 i wartości 2. Wartości te powinny przetwarzać i ponownie zorganizować w odpowiedniej kolejności, aby uzyskać pożądane rozwiązanie. Teraz to przetasowanie i sortowanie odbywa się w systemie lokalnym (Framework dbaj o to) i proces w systemie lokalnym po frameworku procesu czyszczenie danych w systemie lokalnym. Ok
Tutaj używamy combiner i partycji również do optymalizacji tego procesu shuffle i sortowania. Po odpowiednim ułożeniu te kluczowe wartości przechodzą do reduktora, aby uzyskać pożądany wynik klienta. Wreszcie Reduktor uzyskaj żądaną wydajność.
K1, V1 -> K2, V2 (napiszemy program Mapper), - > K2, V' (tutaj shuffle i soft dane) - > K3, V3 generuje wyjście. K4, V4.
Należy pamiętać, że wszystkie te kroki są tylko logiczną operacją, a nie zmianą oryginalnych danych.
Twoje pytanie: jaki jest cel tasowania i sortowania fazy w reduktorze w programowaniu Map Reduce?
Krótka odpowiedź: aby przetworzyć dane, aby uzyskać pożądany wynik. Tasowanie to agregacja danych, redukcja to uzyskanie oczekiwana wydajność.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-12-15 09:19:16