Który commit ma tego Bloba?
Biorąc pod uwagę hash Bloba, czy istnieje sposób, aby uzyskać listę commitów, które mają ten blob w swoim drzewie?
8 answers
Oba poniższe Skrypty przyjmują SHA1 obiektu Bloba jako pierwszy argument, a po nim opcjonalnie wszelkie argumenty, które git log zrozumie. Np. --all szukać we wszystkich gałęziach, a nie tylko w bieżącej, lub -g szukać w reflogu, czy cokolwiek innego, na co masz ochotę.
Tutaj jest to skrypt powłoki-krótki i słodki, ale powolny:
#!/bin/sh
obj_name="$1"
shift
git log "$@" --pretty=format:'%T %h %s' \
| while read tree commit subject ; do
if git ls-tree -r $tree | grep -q "$obj_name" ; then
echo $commit "$subject"
fi
done
I zoptymalizowana wersja w Perlu, wciąż dość krótka, ale znacznie szybsza:
#!/usr/bin/perl
use 5.008;
use strict;
use Memoize;
my $obj_name;
sub check_tree {
my ( $tree ) = @_;
my @subtree;
{
open my $ls_tree, '-|', git => 'ls-tree' => $tree
or die "Couldn't open pipe to git-ls-tree: $!\n";
while ( <$ls_tree> ) {
/\A[0-7]{6} (\S+) (\S+)/
or die "unexpected git-ls-tree output";
return 1 if $2 eq $obj_name;
push @subtree, $2 if $1 eq 'tree';
}
}
check_tree( $_ ) && return 1 for @subtree;
return;
}
memoize 'check_tree';
die "usage: git-find-blob <blob> [<git-log arguments ...>]\n"
if not @ARGV;
my $obj_short = shift @ARGV;
$obj_name = do {
local $ENV{'OBJ_NAME'} = $obj_short;
`git rev-parse --verify \$OBJ_NAME`;
} or die "Couldn't parse $obj_short: $!\n";
chomp $obj_name;
open my $log, '-|', git => log => @ARGV, '--pretty=format:%T %h %s'
or die "Couldn't open pipe to git-log: $!\n";
while ( <$log> ) {
chomp;
my ( $tree, $commit, $subject ) = split " ", $_, 3;
print "$commit $subject\n" if check_tree( $tree );
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-11-15 00:33:30
Niestety Skrypty były dla mnie trochę wolne, więc musiałem trochę zoptymalizować. Na szczęście miałem nie tylko hash, ale także ścieżkę do pliku.
git log --all --pretty=format:%H <path> | xargs -n1 -I% sh -c "git ls-tree % <path> | grep -q <hash> && echo %"
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-09-16 14:41:00
Myślałem, że to będzie ogólnie przydatna rzecz, więc napisałem mały skrypt Perla, aby to zrobić:
#!/usr/bin/perl -w
use strict;
my @commits;
my %trees;
my $blob;
sub blob_in_tree {
my $tree = $_[0];
if (defined $trees{$tree}) {
return $trees{$tree};
}
my $r = 0;
open(my $f, "git cat-file -p $tree|") or die $!;
while (<$f>) {
if (/^\d+ blob (\w+)/ && $1 eq $blob) {
$r = 1;
} elsif (/^\d+ tree (\w+)/) {
$r = blob_in_tree($1);
}
last if $r;
}
close($f);
$trees{$tree} = $r;
return $r;
}
sub handle_commit {
my $commit = $_[0];
open(my $f, "git cat-file commit $commit|") or die $!;
my $tree = <$f>;
die unless $tree =~ /^tree (\w+)$/;
if (blob_in_tree($1)) {
print "$commit\n";
}
while (1) {
my $parent = <$f>;
last unless $parent =~ /^parent (\w+)$/;
push @commits, $1;
}
close($f);
}
if (!@ARGV) {
print STDERR "Usage: git-find-blob blob [head ...]\n";
exit 1;
}
$blob = $ARGV[0];
if (@ARGV > 1) {
foreach (@ARGV) {
handle_commit($_);
}
} else {
handle_commit("HEAD");
}
while (@commits) {
handle_commit(pop @commits);
}
Update: wygląda na to, że ktoś już to zrobił . Ten używa tej samej ogólnej idei, ale szczegóły są różne, a implementacja jest znacznie krótsza. Nie wiem, który byłby szybszy, ale wydajność prawdopodobnie nie jest problemem tutaj!
Update 2: for what it ' s worth, moja implementacja jest o rząd wielkości szybsza, szczególnie w przypadku dużego repozytorium. To naprawdę boli.
Aktualizacja 3: powinienem zauważyć, że moje komentarze dotyczące wydajności powyżej odnoszą się do implementacji, którą podlinkowałem powyżej w pierwszej aktualizacji. implementacja Arystotelesa jest porównywalna do mojej. Więcej szczegółów w komentarzach dla ciekawskich.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:18:05
Podczas gdy oryginalne pytanie nie pyta o to, myślę, że warto również sprawdzić miejsce postoju, aby zobaczyć, czy obiekt blob jest odwołany. Zmodyfikowałem oryginalny skrypt Basha, aby to zrobić i znalazłem to, co odnosi się do uszkodzonej Bloba w moim repozytorium:
#!/bin/sh
obj_name="$1"
shift
git ls-files --stage \
| if grep -q "$obj_name"; then
echo Found in staging area. Run git ls-files --stage to see.
fi
git log "$@" --pretty=format:'%T %h %s' \
| while read tree commit subject ; do
if git ls-tree -r $tree | grep -q "$obj_name" ; then
echo $commit "$subject"
fi
done
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-05-23 21:37:37
Oto szczegóły skryptu, który dopracowałem jako odpowiedź na podobne pytanie, a tutaj możecie zobaczyć go w akcji:
Zrzut ekranu z uruchomieniem git-ls-dir http://adamspiers.org/computing/git-ls-dir.png
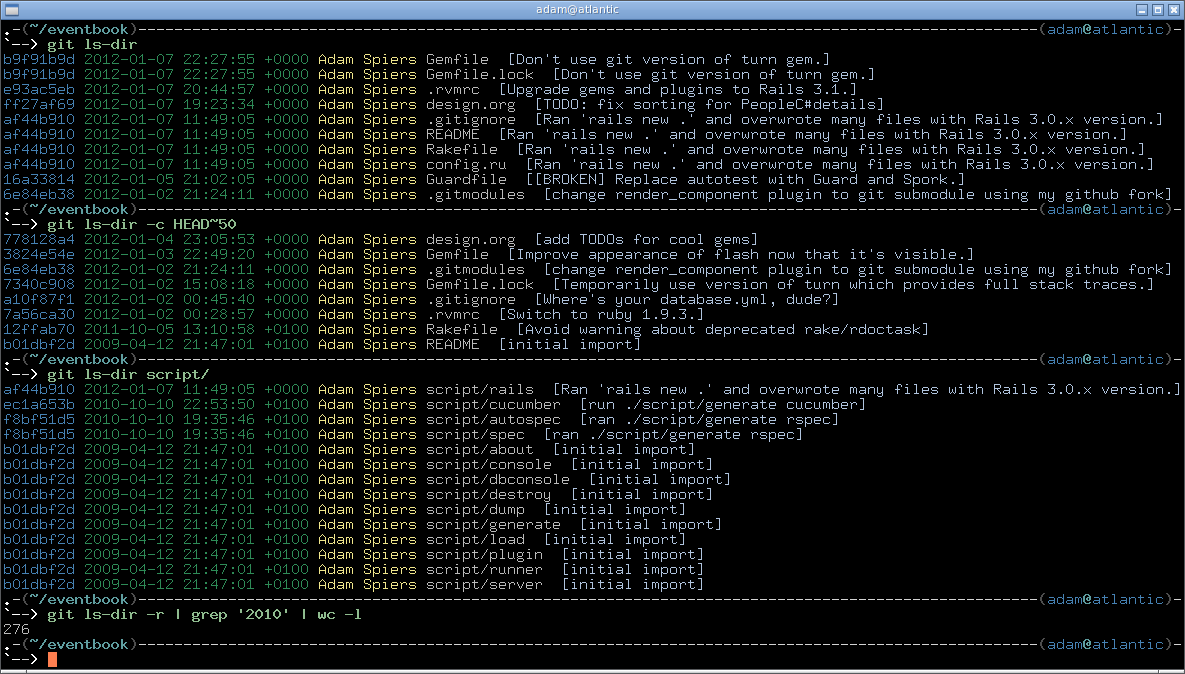{kind=link}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:34:25
Więc... Musiałem znaleźć wszystkie pliki powyżej danego limitu w repo o rozmiarze ponad 8GB, z ponad 108,000 rewizjami. Zaadaptowałem skrypt Perla Arystotelesa wraz ze skryptem ruby, który napisałem, aby osiągnąć to kompletne rozwiązanie.
Po pierwsze, git gc - zrób to, aby upewnić się, że wszystkie obiekty są w plikach packfiles - nie skanujemy obiektów Nie znajdujących się w plikach packfiles.
Następnie uruchom ten skrypt, aby zlokalizować wszystkie obiekty BLOB nad bajtami CUTOFF_SIZE. Przechwytywanie danych wyjściowych do pliku typu " large-blobs.log "
#!/usr/bin/env ruby
require 'log4r'
# The output of git verify-pack -v is:
# SHA1 type size size-in-packfile offset-in-packfile depth base-SHA1
#
#
GIT_PACKS_RELATIVE_PATH=File.join('.git', 'objects', 'pack', '*.pack')
# 10MB cutoff
CUTOFF_SIZE=1024*1024*10
#CUTOFF_SIZE=1024
begin
include Log4r
log = Logger.new 'git-find-large-objects'
log.level = INFO
log.outputters = Outputter.stdout
git_dir = %x[ git rev-parse --show-toplevel ].chomp
if git_dir.empty?
log.fatal "ERROR: must be run in a git repository"
exit 1
end
log.debug "Git Dir: '#{git_dir}'"
pack_files = Dir[File.join(git_dir, GIT_PACKS_RELATIVE_PATH)]
log.debug "Git Packs: #{pack_files.to_s}"
# For details on this IO, see http://stackoverflow.com/questions/1154846/continuously-read-from-stdout-of-external-process-in-ruby
#
# Short version is, git verify-pack flushes buffers only on line endings, so
# this works, if it didn't, then we could get partial lines and be sad.
types = {
:blob => 1,
:tree => 1,
:commit => 1,
}
total_count = 0
counted_objects = 0
large_objects = []
IO.popen("git verify-pack -v -- #{pack_files.join(" ")}") do |pipe|
pipe.each do |line|
# The output of git verify-pack -v is:
# SHA1 type size size-in-packfile offset-in-packfile depth base-SHA1
data = line.chomp.split(' ')
# types are blob, tree, or commit
# we ignore other lines by looking for that
next unless types[data[1].to_sym] == 1
log.info "INPUT_THREAD: Processing object #{data[0]} type #{data[1]} size #{data[2]}"
hash = {
:sha1 => data[0],
:type => data[1],
:size => data[2].to_i,
}
total_count += hash[:size]
counted_objects += 1
if hash[:size] > CUTOFF_SIZE
large_objects.push hash
end
end
end
log.info "Input complete"
log.info "Counted #{counted_objects} totalling #{total_count} bytes."
log.info "Sorting"
large_objects.sort! { |a,b| b[:size] <=> a[:size] }
log.info "Sorting complete"
large_objects.each do |obj|
log.info "#{obj[:sha1]} #{obj[:type]} #{obj[:size]}"
end
exit 0
end
Następnie Edytuj plik do usuń wszystkie obiekty BLOB, które nie czekają i bity INPUT_THREAD na górze. gdy masz tylko wiersze dla sha1s, które chcesz znaleźć, uruchom następujący skrypt w następujący sposób:
cat edited-large-files.log | cut -d' ' -f4 | xargs git-find-blob | tee large-file-paths.log
Gdzie git-find-blob skrypt znajduje się poniżej.
#!/usr/bin/perl
# taken from: http://stackoverflow.com/questions/223678/which-commit-has-this-blob
# and modified by Carl Myers <[email protected]> to scan multiple blobs at once
# Also, modified to keep the discovered filenames
# vi: ft=perl
use 5.008;
use strict;
use Memoize;
use Data::Dumper;
my $BLOBS = {};
MAIN: {
memoize 'check_tree';
die "usage: git-find-blob <blob1> <blob2> ... -- [<git-log arguments ...>]\n"
if not @ARGV;
while ( @ARGV && $ARGV[0] ne '--' ) {
my $arg = $ARGV[0];
#print "Processing argument $arg\n";
open my $rev_parse, '-|', git => 'rev-parse' => '--verify', $arg or die "Couldn't open pipe to git-rev-parse: $!\n";
my $obj_name = <$rev_parse>;
close $rev_parse or die "Couldn't expand passed blob.\n";
chomp $obj_name;
#$obj_name eq $ARGV[0] or print "($ARGV[0] expands to $obj_name)\n";
print "($arg expands to $obj_name)\n";
$BLOBS->{$obj_name} = $arg;
shift @ARGV;
}
shift @ARGV; # drop the -- if present
#print "BLOBS: " . Dumper($BLOBS) . "\n";
foreach my $blob ( keys %{$BLOBS} ) {
#print "Printing results for blob $blob:\n";
open my $log, '-|', git => log => @ARGV, '--pretty=format:%T %h %s'
or die "Couldn't open pipe to git-log: $!\n";
while ( <$log> ) {
chomp;
my ( $tree, $commit, $subject ) = split " ", $_, 3;
#print "Checking tree $tree\n";
my $results = check_tree( $tree );
#print "RESULTS: " . Dumper($results);
if (%{$results}) {
print "$commit $subject\n";
foreach my $blob ( keys %{$results} ) {
print "\t" . (join ", ", @{$results->{$blob}}) . "\n";
}
}
}
}
}
sub check_tree {
my ( $tree ) = @_;
#print "Calculating hits for tree $tree\n";
my @subtree;
# results = { BLOB => [ FILENAME1 ] }
my $results = {};
{
open my $ls_tree, '-|', git => 'ls-tree' => $tree
or die "Couldn't open pipe to git-ls-tree: $!\n";
# example git ls-tree output:
# 100644 blob 15d408e386400ee58e8695417fbe0f858f3ed424 filaname.txt
while ( <$ls_tree> ) {
/\A[0-7]{6} (\S+) (\S+)\s+(.*)/
or die "unexpected git-ls-tree output";
#print "Scanning line '$_' tree $2 file $3\n";
foreach my $blob ( keys %{$BLOBS} ) {
if ( $2 eq $blob ) {
print "Found $blob in $tree:$3\n";
push @{$results->{$blob}}, $3;
}
}
push @subtree, [$2, $3] if $1 eq 'tree';
}
}
foreach my $st ( @subtree ) {
# $st->[0] is tree, $st->[1] is dirname
my $st_result = check_tree( $st->[0] );
foreach my $blob ( keys %{$st_result} ) {
foreach my $filename ( @{$st_result->{$blob}} ) {
my $path = $st->[1] . '/' . $filename;
#print "Generating subdir path $path\n";
push @{$results->{$blob}}, $path;
}
}
}
#print "Returning results for tree $tree: " . Dumper($results) . "\n\n";
return $results;
}
Wynik będzie wyglądał następująco:
<hash prefix> <oneline log message>
path/to/file.txt
path/to/file2.txt
...
<hash prefix2> <oneline log msg...>
I tak dalej. Każdy commit zawierający duży plik w drzewie zostanie wyświetlony. Jeśli grep wyświetli się linia rozpoczynająca się tabulatorem i uniq, będzie wyświetlona lista wszystkich ścieżek, które można filtrować do usunięcia, albo możesz zrobić coś bardziej skomplikowanego.
Powtórzę: ten proces przebiegł pomyślnie, na repo 10GB z 108,000 commitów. Zajęło to znacznie dłużej, niż przewidywałem, gdy działałem na dużej liczbie blobów, chociaż ponad 10 godzin, będę musiał sprawdzić, czy bit zapamiętywania działa...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-03-06 17:35:47
Biorąc pod uwagę hash Bloba, czy istnieje sposób, aby uzyskać listę commitów, które mają ten blob w swoim drzewie?
With Git 2.16 (Q1 2018), git describe byłoby dobrym rozwiązaniem, ponieważ uczono kopać drzewa głębiej, aby znaleźć <commit-ish>:<path>, który odnosi się do danego obiektu blob.
Zobacz commit 644eb60, commit 4dbc59a, commit cdaed0c, commit c87b653, w 2017 roku, po raz pierwszy w historii, w Polsce, w Polsce, w Polsce i na świecie, w 2017 roku, w Polsce i na świecie.]}, commit 2deda00 (02 Nov 2017) by Stefan Beller (stefanbeller).
(dodany przez Junio C Hamano -- gitster -- in commit 556de1a, 28 Dec 2017)
builtin/describe.c: Opis BlobaCzasami użytkownicy otrzymują hash obiektu i chcą zidentyfikuj go dalej (ex.: Użyj
verify-pack, aby znaleźć największe plamy, ale co to jest? albo to bardzo pytanie " który commit ma tego Bloba?")Opisując commity, staramy się zakotwiczyć je w tagach lub refach, ponieważ te są koncepcyjnie na wyższym poziomie niż commit. A jeśli nie ma ref albo znacznik, który pasuje dokładnie, nie mamy szczęścia.
Więc użyjemy heurystyki, aby stworzyć Nazwę dla commit. Nazwy te są niejednoznaczne, mogą być różne tagi lub refy do zakotwiczenia i mogą być różne ścieżki w DAG, aby dotrzeć do commita.Opisując blob, chcemy opisz blob z wyższej warstwy również, co jest krotką
(commit, deep/path)jako obiekty drzewa zaangażowane są raczej nieciekawe.
Ten sam obiekt blob może być odwołany przez wiele commitów, więc jak decydujemy, którego commita użyć?Ta łatka implementuje dość naiwne podejście do tej kwestii: ponieważ nie ma wstecznych wskaźników od obiektów blob do commitów, w których obiekt blob występuje, zaczniemy od wszelkich dostępnych wskazówek, wymieniając obiekty BLOB w kolejności commitów i gdy znalazłem Bloba, weźmiemy pierwszy commit, który wymienia Bloba.
Na przykład:
git describe --tags v0.99:Makefile conversion-901-g7672db20c2:MakefileMówi nam
[[18]}spacer odbywa się w odwrotnej kolejności, aby pokazać wprowadzenie blob zamiast jego ostatniego wystąpienia.MakefileJak to było wv0.99został wprowadzony w commit 7672db2.
To znaczy, że git describe strona podręcznika dodaje do celów tego polecenia:
Zamiast po prostu opisywać commit używając najnowszego znacznika osiągalnego na podstawie tego git describe nada obiektowi czytelną dla człowieka nazwę opartą na dostępnym ref, gdy zostanie użyty jako git describe <blob>.
Jeśli dany obiekt odnosi się do obiektu blob, zostanie on opisany jako
<commit-ish>:<path>, tak że obiekt blob można znaleźć w<path>w<commit-ish>, który sam opisuje pierwszy commit, w którym obiekt blob występuje w odwrotnej rewizji od HEAD.
Ale:
Błędy
Obiektów drzewiastych, jak również obiektów znaczników nie wskazujących na commity, nie można opisać .
Podczas opisywania obiektów blob, lekkie znaczniki wskazujące na obiekty blob są ignorowane, ale obiekt blob jest nadal opisywany jako<committ-ish>:<path>, mimo że tag lightweight jest korzystny.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-12-29 19:54:30
Oprócz git describe, o czym wspominam w poprzedniej odpowiedzi, git log i git diff teraz korzysta również z opcji " --find-object=<object-id>", aby ograniczyć wyniki do zmian, które dotyczą nazwanego obiektu.
To jest w Git 2.16.x / 2.17 (Q1 2018)
Zobacz commit 4d8c51a, / align = "left" / 550525, commit 15af58c, commit cf63051, commit c1ddc46, w 2018 roku, po raz pierwszy w historii, w Polsce, w Polsce, w 2018 roku, w Polsce, w 2019 roku, w Polsce, w 2019 roku, w Polsce, w 2019 roku, w Polsce, w 2019 roku. (stefanbeller).
(dodany przez Junio C Hamano -- gitster -- in commit c0d75f0, 23 Jan 2018)
[[7]}: Dodaj opcję kilofa, aby znaleźć konkretną blob
Czasami użytkownicy otrzymują hash obiektu i chcą zidentyfikuj go dalej (ex.: Użyj verify-pack, aby znaleźć największe plamy, ale co to jest? albo pytanie o przepełnienie stosu " który commit ma tę blob?")
[[15]] można się pokusić o przedłużeniegit-describedo pracy z blobami, taki, żegit describe <blob-id>daje opis jako ':'.
To zostało zaimplementowane tutaj ; Jak widać przez samą liczba odpowiedzi (>110), okazuje się, że jest to trudne do poprawienia.
Najtrudniej jest wybrać właściwy "commit-OWS", ponieważ może to być commit, który (ponownie)wprowadził obiekt blob lub obiekt blob, który usunięto blob; blob może istnieć w różnych gałęziach.Junio zasugerował inne podejście do rozwiązywania ten problem, który to Patch implements.
Naucz maszynędiffinną flagę ograniczającą informacje do tego, co jest pokazane.
Na przykład:$ ./git log --oneline --find-object=v2.0.0:Makefile b2feb64 Revert the whole "ask curl-config" topic for now 47fbfde i18n: only extract comments marked with "TRANSLATORS:"Obserwujemy, że
Makefilejako wysłane z2.0pojawił się wv1.9.2-471-g47fbfded53i wv2.0.0-rc1-5-gb2feb6430b.
Powodem, dla którego oba commity występują przed v2. 0. 0 są złe połączenia, które nie zostały znalezione przy użyciu tego nowego mechanizmu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-02-02 20:15:45