Jak mieć klastry ułożonych słupków z Pythonem (Pandy)
Oto jak wygląda mój zestaw danych:
In [1]: df1=pd.DataFrame(np.random.rand(4,2),index=["A","B","C","D"],columns=["I","J"])
In [2]: df2=pd.DataFrame(np.random.rand(4,2),index=["A","B","C","D"],columns=["I","J"])
In [3]: df1
Out[3]:
I J
A 0.675616 0.177597
B 0.675693 0.598682
C 0.631376 0.598966
D 0.229858 0.378817
In [4]: df2
Out[4]:
I J
A 0.939620 0.984616
B 0.314818 0.456252
C 0.630907 0.656341
D 0.020994 0.538303
Chcę mieć ułożony wykres słupkowy dla każdej ramki danych, ale ponieważ mają ten sam indeks, chciałbym mieć 2 ułożone słupki na indeks.
Próbowałem wykreślić oba na tych samych osiach:
In [5]: ax = df1.plot(kind="bar", stacked=True)
In [5]: ax2 = df2.plot(kind="bar", stacked=True, ax = ax)
Potem starałem się najpierw połączyć dwa zbiory danych:
pd.concat(dict(df1 = df1, df2 = df2),axis = 1).plot(kind="bar", stacked=True)
Ale tutaj wszystko jest ułożone
Moja najlepsza próba to:
pd.concat(dict(df1 = df1, df2 = df2),axis = 0).plot(kind="bar", stacked=True)
Co daje:
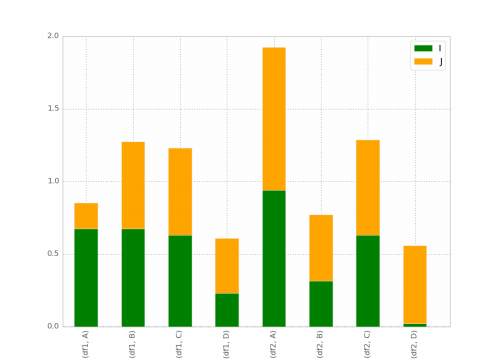
To jest zasadniczo to, czego chcę, z wyjątkiem tego, że chcę, aby pasek był zamówiony jako
(df1, A) (df2,a) (df1,B) (DF2,B) itd...
Myślę, że jest sztuczka, ale nie mogę jej znaleźć !
Po odpowiedzi @ bgschiller mam to:
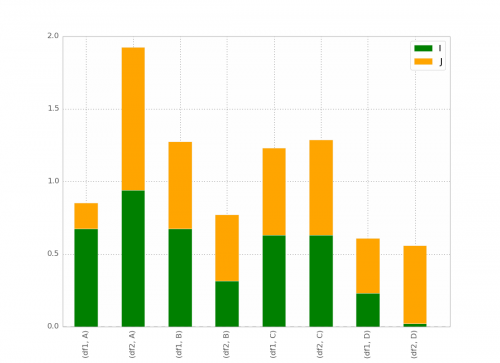
Bonus : posiadanie x-label nie jest zbędne, coś w stylu:
df1 df2 df1 df2
_______ _______ ...
A B
Dzięki za pomagam.
5 answers
W końcu znalazłem sztuczkę (edit: zobacz poniżej, jak używać seaborn i longform dataframe):
Roztwór z pand i matplotlib
Oto bardziej kompletny przykład:
import pandas as pd
import matplotlib.cm as cm
import numpy as np
import matplotlib.pyplot as plt
def plot_clustered_stacked(dfall, labels=None, title="multiple stacked bar plot", H="/", **kwargs):
"""Given a list of dataframes, with identical columns and index, create a clustered stacked bar plot.
labels is a list of the names of the dataframe, used for the legend
title is a string for the title of the plot
H is the hatch used for identification of the different dataframe"""
n_df = len(dfall)
n_col = len(dfall[0].columns)
n_ind = len(dfall[0].index)
axe = plt.subplot(111)
for df in dfall : # for each data frame
axe = df.plot(kind="bar",
linewidth=0,
stacked=True,
ax=axe,
legend=False,
grid=False,
**kwargs) # make bar plots
h,l = axe.get_legend_handles_labels() # get the handles we want to modify
for i in range(0, n_df * n_col, n_col): # len(h) = n_col * n_df
for j, pa in enumerate(h[i:i+n_col]):
for rect in pa.patches: # for each index
rect.set_x(rect.get_x() + 1 / float(n_df + 1) * i / float(n_col))
rect.set_hatch(H * int(i / n_col)) #edited part
rect.set_width(1 / float(n_df + 1))
axe.set_xticks((np.arange(0, 2 * n_ind, 2) + 1 / float(n_df + 1)) / 2.)
axe.set_xticklabels(df.index, rotation = 0)
axe.set_title(title)
# Add invisible data to add another legend
n=[]
for i in range(n_df):
n.append(axe.bar(0, 0, color="gray", hatch=H * i))
l1 = axe.legend(h[:n_col], l[:n_col], loc=[1.01, 0.5])
if labels is not None:
l2 = plt.legend(n, labels, loc=[1.01, 0.1])
axe.add_artist(l1)
return axe
# create fake dataframes
df1 = pd.DataFrame(np.random.rand(4, 5),
index=["A", "B", "C", "D"],
columns=["I", "J", "K", "L", "M"])
df2 = pd.DataFrame(np.random.rand(4, 5),
index=["A", "B", "C", "D"],
columns=["I", "J", "K", "L", "M"])
df3 = pd.DataFrame(np.random.rand(4, 5),
index=["A", "B", "C", "D"],
columns=["I", "J", "K", "L", "M"])
# Then, just call :
plot_clustered_stacked([df1, df2, df3],["df1", "df2", "df3"])
I daje to:
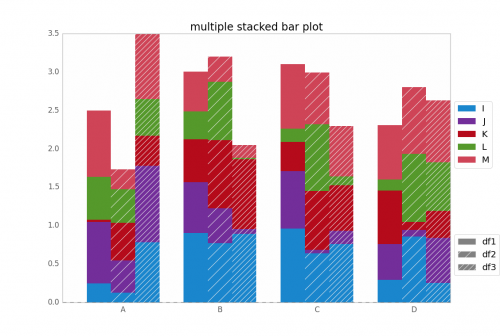
Możesz zmienić kolory paska, przekazując argument cmap:
plot_clustered_stacked([df1, df2, df3],
["df1", "df2", "df3"],
cmap=plt.cm.viridis)
Roztwór z seaborn:
Biorąc pod uwagę te same df1, DF2, DF3, poniżej, konwertuję je w postaci długiej:
df1["Name"] = "df1"
df2["Name"] = "df2"
df3["Name"] = "df3"
dfall = pd.concat([pd.melt(i.reset_index(),
id_vars=["Name", "index"]) # transform in tidy format each df
for i in [df1, df2, df3]],
ignore_index=True)
Problem z seaborn polega na tym, że nie układa słupków natywnie, więc sztuczka polega na wykreśleniu skumulowanej sumy każdego słupka jeden na drugim: {]}
dfall.set_index(["Name", "index", "variable"], inplace=1)
dfall["vcs"] = dfall.groupby(level=["Name", "index"]).cumsum()
dfall.reset_index(inplace=True)
>>> dfall.head(6)
Name index variable value vcs
0 df1 A I 0.717286 0.717286
1 df1 B I 0.236867 0.236867
2 df1 C I 0.952557 0.952557
3 df1 D I 0.487995 0.487995
4 df1 A J 0.174489 0.891775
5 df1 B J 0.332001 0.568868
Następnie pętla nad każdą grupą variable i wykreślić sumę skumulowaną:
c = ["blue", "purple", "red", "green", "pink"]
for i, g in enumerate(dfall.groupby("variable")):
ax = sns.barplot(data=g[1],
x="index",
y="vcs",
hue="Name",
color=c[i],
zorder=-i, # so first bars stay on top
edgecolor="k")
ax.legend_.remove() # remove the redundant legends

Brakuje mu legendy, którą można łatwo dodać. Problem w tym, że zamiast włazów (które można łatwo dodać) do różnicowania ramek danych mamy gradient lekkości, a na pierwszy jest trochę za lekki, a ja nie naprawdę wiem, jak to zmienić, nie zmieniając każdego prostokąta jeden po drugim (jak w pierwszym rozwiązaniu).
Powiedz, jeśli czegoś nie rozumiesz w kodzie.Możesz ponownie użyć tego kodu, który znajduje się pod CC0.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-06-09 16:45:56
Udało mi się zrobić to samo używając podprogramów pandy i matplotlib z podstawowymi poleceniami.
Oto przykład:
fig, axes = plt.subplots(nrows=1, ncols=3)
ax_position = 0
for concept in df.index.get_level_values('concept').unique():
idx = pd.IndexSlice
subset = df.loc[idx[[concept], :],
['cmp_tr_neg_p_wrk', 'exp_tr_pos_p_wrk',
'cmp_p_spot', 'exp_p_spot']]
print(subset.info())
subset = subset.groupby(
subset.index.get_level_values('datetime').year).sum()
subset = subset / 4 # quarter hours
subset = subset / 100 # installed capacity
ax = subset.plot(kind="bar", stacked=True, colormap="Blues",
ax=axes[ax_position])
ax.set_title("Concept \"" + concept + "\"", fontsize=30, alpha=1.0)
ax.set_ylabel("Hours", fontsize=30),
ax.set_xlabel("Concept \"" + concept + "\"", fontsize=30, alpha=0.0),
ax.set_ylim(0, 9000)
ax.set_yticks(range(0, 9000, 1000))
ax.set_yticklabels(labels=range(0, 9000, 1000), rotation=0,
minor=False, fontsize=28)
ax.set_xticklabels(labels=['2012', '2013', '2014'], rotation=0,
minor=False, fontsize=28)
handles, labels = ax.get_legend_handles_labels()
ax.legend(['Market A', 'Market B',
'Market C', 'Market D'],
loc='upper right', fontsize=28)
ax_position += 1
# look "three subplots"
#plt.tight_layout(pad=0.0, w_pad=-8.0, h_pad=0.0)
# look "one plot"
plt.tight_layout(pad=0., w_pad=-16.5, h_pad=0.0)
axes[1].set_ylabel("")
axes[2].set_ylabel("")
axes[1].set_yticklabels("")
axes[2].set_yticklabels("")
axes[0].legend().set_visible(False)
axes[1].legend().set_visible(False)
axes[2].legend(['Market A', 'Market B',
'Market C', 'Market D'],
loc='upper right', fontsize=28)
Struktura ramki danych "podzbioru" przed grupowaniem wygląda następująco:
<class 'pandas.core.frame.DataFrame'>
MultiIndex: 105216 entries, (D_REC, 2012-01-01 00:00:00) to (D_REC, 2014-12-31 23:45:00)
Data columns (total 4 columns):
cmp_tr_neg_p_wrk 105216 non-null float64
exp_tr_pos_p_wrk 105216 non-null float64
cmp_p_spot 105216 non-null float64
exp_p_spot 105216 non-null float64
dtypes: float64(4)
memory usage: 4.0+ MB
A fabuła taka:

Jest sformatowany w stylu "ggplot" z następującym nagłówkiem:
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.style.use('ggplot')
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-01-28 11:42:45
Jesteś na dobrej drodze! Aby zmienić kolejność słupków, należy zmienić kolejność w indeksie.
In [5]: df_both = pd.concat(dict(df1 = df1, df2 = df2),axis = 0)
In [6]: df_both
Out[6]:
I J
df1 A 0.423816 0.094405
B 0.825094 0.759266
C 0.654216 0.250606
D 0.676110 0.495251
df2 A 0.607304 0.336233
B 0.581771 0.436421
C 0.233125 0.360291
D 0.519266 0.199637
[8 rows x 2 columns]
Więc chcemy zamienić osie, a następnie zmienić kolejność. Oto prosty sposób, aby to zrobić
In [7]: df_both.swaplevel(0,1)
Out[7]:
I J
A df1 0.423816 0.094405
B df1 0.825094 0.759266
C df1 0.654216 0.250606
D df1 0.676110 0.495251
A df2 0.607304 0.336233
B df2 0.581771 0.436421
C df2 0.233125 0.360291
D df2 0.519266 0.199637
[8 rows x 2 columns]
In [8]: df_both.swaplevel(0,1).sort_index()
Out[8]:
I J
A df1 0.423816 0.094405
df2 0.607304 0.336233
B df1 0.825094 0.759266
df2 0.581771 0.436421
C df1 0.654216 0.250606
df2 0.233125 0.360291
D df1 0.676110 0.495251
df2 0.519266 0.199637
[8 rows x 2 columns]
Jeśli ważne jest, aby poziome etykiety pokazywały się w starej kolejności (df1,A), a nie (A, df1), możemy po prostu swaplevelS ponownie, a nie sort_index:
In [9]: df_both.swaplevel(0,1).sort_index().swaplevel(0,1)
Out[9]:
I J
df1 A 0.423816 0.094405
df2 A 0.607304 0.336233
df1 B 0.825094 0.759266
df2 B 0.581771 0.436421
df1 C 0.654216 0.250606
df2 C 0.233125 0.360291
df1 D 0.676110 0.495251
df2 D 0.519266 0.199637
[8 rows x 2 columns]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-04-01 13:44:17
To świetny początek, ale myślę, że kolory można nieco zmodyfikować dla jasności. Należy również uważać na importowanie każdego argumentu w Altair, ponieważ może to spowodować kolizje z istniejącymi obiektami w przestrzeni nazw. Oto kilka rekonfiguracji kodu, aby wyświetlić prawidłowy kolor wyświetlacza podczas układania wartości:

Import pakietów
import pandas as pd
import numpy as np
import altair as alt
Wygeneruj losowe DANE
df1=pd.DataFrame(10*np.random.rand(4,3),index=["A","B","C","D"],columns=["I","J","K"])
df2=pd.DataFrame(10*np.random.rand(4,3),index=["A","B","C","D"],columns=["I","J","K"])
df3=pd.DataFrame(10*np.random.rand(4,3),index=["A","B","C","D"],columns=["I","J","K"])
def prep_df(df, name):
df = df.stack().reset_index()
df.columns = ['c1', 'c2', 'values']
df['DF'] = name
return df
df1 = prep_df(df1, 'DF1')
df2 = prep_df(df2, 'DF2')
df3 = prep_df(df3, 'DF3')
df = pd.concat([df1, df2, df3])
Dane wykresu z Altair
alt.Chart(df).mark_bar().encode(
# tell Altair which field to group columns on
x=alt.X('c2:N',
axis=alt.Axis(
title='')),
# tell Altair which field to use as Y values and how to calculate
y=alt.Y('sum(values):Q',
axis=alt.Axis(
grid=False,
title='')),
# tell Altair which field to use to use as the set of columns to be represented in each group
column=alt.Column('c1:N',
axis=alt.Axis(
title='')),
# tell Altair which field to use for color segmentation
color=alt.Color('DF:N',
scale=alt.Scale(
# make it look pretty with an enjoyable color pallet
range=['#96ceb4', '#ffcc5c','#ff6f69'],
),
))\
.configure_facet_cell(
# remove grid lines around column clusters
strokeWidth=0.0)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-10-31 16:31:11
Altair może być tutaj pomocny. Oto Wyprodukowana fabuła.

Import
import pandas as pd
import numpy as np
from altair import *
Tworzenie zbiorów danych
df1=pd.DataFrame(10*np.random.rand(4,2),index=["A","B","C","D"],columns=["I","J"])
df2=pd.DataFrame(10*np.random.rand(4,2),index=["A","B","C","D"],columns=["I","J"])
Przygotowanie zbioru danych
def prep_df(df, name):
df = df.stack().reset_index()
df.columns = ['c1', 'c2', 'values']
df['DF'] = name
return df
df1 = prep_df(df1, 'DF1')
df2 = prep_df(df2, 'DF2')
df = pd.concat([df1, df2])
Altair plot
Chart(df).mark_bar().encode(y=Y('values', axis=Axis(grid=False)),
x='c2:N',
column=Column('c1:N') ,
color='DF:N').configure_facet_cell( strokeWidth=0.0).configure_cell(width=200, height=200)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-07-06 03:21:40