Korzystanie z modeli widoku z wzorcem repozytorium
Używam Domain driven N-layered application architecture Z EF code first w moim niedawnym projekcie zdefiniowałem moje Kontrakty Repository w warstwie Domain.
Podstawowa umowa, aby inne Repositories mniej wyraziste:
public interface IRepository<TEntity, in TKey> where TEntity : class
{
TEntity GetById(TKey id);
void Create(TEntity entity);
void Update(TEntity entity);
void Delete(TEntity entity);
}
I specjalistyczne Repositories dla każdego Aggregation root, np.:
public interface IOrderRepository : IRepository<Order, int>
{
IEnumerable<Order> FindAllOrders();
IEnumerable<Order> Find(string text);
//other methods that return Order aggregation root
}
Jak widzisz, wszystkie te metody zależą od Domain entities.
Ale w niektórych przypadkach, aplikacja UI, potrzebuje danych, które nie są Entity, Dane te mogą być wykonane z dwóch lub więcej danych entitis (View-Models), w tych przypadki definiuję View-Modelw Application layer, ponieważ są one ściśle zależne od Application's potrzeb, a nie od Domain.
Więc myślę, że mam 2 sposoby, aby pokazać dane jako View-Models w UI:
- pozostaw specialized
Repositoryzależy tylko odEntitiesi Mapuj wyniki metodyRepositoriesnaView-Modelskiedy chcę pokazać użytkownikowi(wApplication Layerzazwyczaj). - dodaj kilka metod do mojego specialized
Repositories, które zwracają swoje wyniki bezpośrednio jakoView-Modelsi użyj tych zwróconych wartości, wApplication Layera potemUI(te wyspecjalizowaneRepositorieskontrakty, które nazywamReadonly Repository Contract, wkładamApplication LayerW przeciwieństwie do innychRepositorieskontraktów, które wkładamDomain).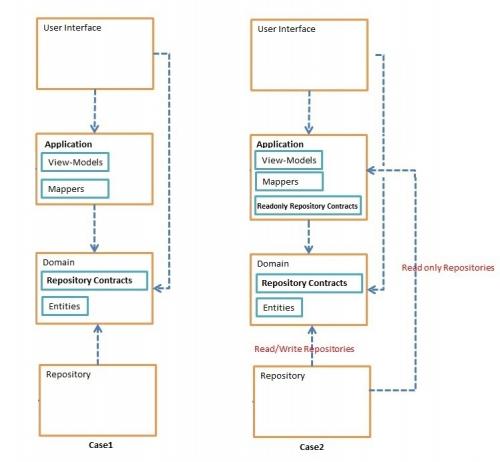
Załóżmy, że mój UI potrzebuje View-Model z 3 lub 4 właściwościami (od 3 lub 4 duży Entities).
Dane mogą być generowane za pomocą prostej projekcji, ale w przypadku 1, ponieważ moje metody nie mogły uzyskać dostępu do View-Models, muszę pobrać wszystkie pola wszystkich 3 lub 4 tabel Z czasami ogromnymi połączeniami, a następnie zmapować wyniki do View-Models.
Ale w przypadku 2, mógłbym po prostu użyć projekcji i wypełnić View-Modelbezpośrednio.
Entities, a nie View-Models z punktu widzenia projektu.
Czy jest jakiś lepszy sposób, który nie powoduje, że warstwa Domain zależy od Application layer, a także nie wpływa na wydajność? czy jest to dopuszczalne, że do czytania zapytań, moje Repositories zależy od View-Models?(case2)
3 answers
Być może za pomocą rozdzielanie poleceń-zapytań (na poziomie aplikacji) może trochę pomóc.
Powinieneś uzależnić swoje repozytoria tylko od encji i przechowywać tylko trivial retrieve method - czyli GetOrderById() - w swoim repozytorium (wraz z create / update / merge / delete, oczywiście). Wyobraź sobie, że encje, repozytoria, Usługi domenowe, polecenia interfejsu użytkownika, usługi aplikacji, które obsługują te polecenia (na przykład kontroler sieciowy obsługujący żądania POST w aplikacji internetowej itp.) reprezentuje twój Model zapisu , strona zapisu Twojej aplikacji.
Następnie zbuduj oddzielny Model odczytu , który może być tak brudny, jak chcesz - umieść tam łączniki 5 tabel, kod, który odczytuje z pliku liczbę gwiazd we wszechświecie, mnoży go z liczbą książek zaczynającą się od A (po wykonaniu zapytania przeciwko Amazon) i buduje N-wymiarowa struktura, która itp. - masz pomysł :) ale na read-model nie dodawaj żadnego kodu, który zajmuje się modyfikacją Twoich Bytów. Możesz zwrócić dowolne modele widoku z tego modelu odczytu, ale wywołaj wszelkie zmiany danych stąd.
Rozdzielenie odczytów i zapisów powinno zmniejszyć złożoność programu i sprawić, że wszystko będzie łatwiejsze do opanowania. Możesz również zobaczyć, że nie złamie zasad projektowania, o których wspomniałeś w swoim pytaniu (miejmy nadzieję).
Z punktu widzenia wydajności, korzystanie z modelu odczytu , to znaczy pisanie kodu, który odczytuje Dane oddzielnie od kodu, który zapisuje / zmienia Dane jest najlepsze, jak możesz uzyskać :) dzieje się tak dlatego, że możesz nawet wstawić tam kod SQL bez spania w nocy - a zapytania SQL, jeśli są dobrze napisane, zapewnią Twojej aplikacji znaczny wzrost prędkości.
Nota bene: trochę żartowałem co i jak można kodować swoją stronę odczytu-the kod po stronie odczytu powinien być czysty i prosty jak kod po stronie zapisu, oczywiście:)
Ponadto możesz pozbyć się interfejsugeneric repository , ponieważ po prostu zaśmieca domenę, którą modelujesz i zmusza każde konkretne repozytorium do ujawniania metod, które nie są konieczne :) Zobaczto . Na przykład, jest wysoce prawdopodobne, że metoda Delete() nigdy nie zostanie użyta dla OrderRepository - ponieważ być może polecenia nigdy nie powinny być usunięte (oczywiście, jak zawsze, to zależy). Oczywiście możesz przechowywać zarządzanie bazami danych prymitywy w jednym module i ponownie używać tych prymitywów w swoich konkretnych repozytoriach, ale nie ujawniać tych prymitywów nikomu innemu, tylko implementacji repozytoriów-po prostu dlatego, że nie są one potrzebne nigdzie indziej i mogą zmylić pijanego programistę, jeśli zostanie publicznie ujawniony.
Wreszcie, być może dobrze byłoby nie myśleć o warstwie domeny , warstwa aplikacji, Warstwa danych lub wyświetlanie warstwy modeli w zbyt surowy sposób. Proszę przeczytać to. Pakowanie modułów oprogramowania według ich rzeczywistego znaczenia / celu (lub funkcji) jest nieco lepsze niż pakowanie ich w oparciu o nienaturalne, trudne do zrozumienia, trudno-wyjasnic-5-staremu-dziecku kryterium, czyli pakowanie ich po warstwie .
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-04-29 21:13:20
Cóż, dla mnie mapowałbym ViewModel na obiekty modelu i używał tych w moich repozytoriach do odczytu / zapisu, jak zapewne wiesz, istnieje kilka narzędzi, które możesz zrobić w tym celu, w moim osobistym przypadku używam automapper , który uważam za bardzo łatwy do zaimplementowania.
Staraj się utrzymać zależność między warstwą Web a warstwami repozytorium tak od siebie, jak to tylko możliwe, mówiąc, że repos powinny rozmawiać tylko z modelem, a twoja warstwa web powinna rozmawiać z Twoim widokiem modelki.
Opcja może być taka, że możesz używać DTO w usłudze i automatyzować te obiekty w warstwie internetowej (może być tak, że mapowanie jeden do jednego) wadą jest to, że możesz skończyć z dużą ilością kodu boilerplate i modele dtos i view mogą czuć się zduplikowane.
Inną opcją jest zwrócenie częściowo uwodnionych obiektów w modelu i wystawienie tych obiektów jako Dto i mapowanie tych obiektów do modeli widoku. może tworzyć żądane prognozy i zwracać tylko potrzebne informacje.
Możesz pozbyć się modeli widoków i wyeksponować Dto w warstwie internetowej i używać ich jako modeli widoków, mniej kodu, ale bardziej sprzężonego podejścia.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-04-30 16:29:07
Zgadzam się z Pedro. korzystanie z warstwy usług aplikacji może być korzystne. jeśli dążysz do implementacji typu MVVM radzę stworzyć klasę modelu, która jest odpowiedzialna za przechowywanie danych pobieranych za pomocą warstwy usług. Mapowanie danych za pomocą automapper jest naprawdę dobrym pomysłem, jeśli Twoje entity, DTO i modele są nazwane konsekwentnie (więc nie musisz pisać wielu ręcznych mapowań).
Z mojego doświadczenia korzystania z Twoich Bytów / poco w viewmodels do wyświetlania danych spowoduje duże kulki błota. Różne widoki mają różne potrzeby PL dodają potrzebę dodania większej liczby właściwości do encji. Powoli sprawiając, że zapytania stają się bardziej złożone i wolniejsze.
Jeśli Twoje dane nie zmieniają się często, warto rozważyć wprowadzenie widoków (SQL/database), które przeniosą część ciężaru do bazy danych (gdzie jest wysoce zoptymalizowany). EF dość dobrze obsługuje widoki baz danych. Następnie pobranie encji i mapowanie dane (z widoków) do modelu lub DTO stają się dość proste.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-04-30 18:53:22