Wydajność Swift Beta: sortowanie tablic
Implementowałem algorytm w Swift Beta i zauważyłem, że wydajność była bardzo słaba. Po kopaniu głębiej zdałem sobie sprawę, że jednym z wąskich gardeł było coś tak prostego, jak sortowanie tablic. Odpowiednia część znajduje się tutaj:
let n = 1000000
var x = [Int](repeating: 0, count: n)
for i in 0..<n {
x[i] = random()
}
// start clock here
let y = sort(x)
// stop clock here
W C++, podobna operacja trwa 0.06 s na moim komputerze.
W Pythonie zajmuje 0.6 s (bez sztuczek, tylko y = posortowane (x) dla listy liczb całkowitych).
W Swift zajmuje 6s jeśli skompiluję go z następujące polecenie:
xcrun swift -O3 -sdk `xcrun --show-sdk-path --sdk macosx`
I zajmuje to aż 88s jeśli skompiluję go za pomocą następującego polecenia:
xcrun swift -O0 -sdk `xcrun --show-sdk-path --sdk macosx`
Timingi w Xcode z kompilacjami "Release" i "Debug" są podobne.
Co tu się dzieje? Mogłem zrozumieć pewną utratę wydajności w porównaniu z C++, ale nie 10-krotne spowolnienie w porównaniu z czystym Pythonem.Edit: mweathers zauważył, że zmiana -O3 na -Ofast sprawia, że ten kod działa prawie tak szybko, jak C++ wersja! Jednak -Ofast bardzo zmienia semantykę języka - w moich testach wyłączono sprawdzanie przepełnień całkowitych i przepełnień indeksowania tablicy. Na przykład, z -Ofast następujący kod Swift działa cicho bez awarii (i wypisuje jakieś śmieci):
let n = 10000000
print(n*n*n*n*n)
let x = [Int](repeating: 10, count: n)
print(x[n])
Więc -Ofast to nie jest to, czego chcemy; cały sens Swift jest to, że mamy siatki bezpieczeństwa na miejscu. Oczywiście siatki zabezpieczające mają pewien wpływ na wydajność, ale nie powinny programy 100 razy wolniejsze. Pamiętaj, że Java sprawdza już granice tablic, a w typowych przypadkach spowolnienie jest czynnikiem znacznie mniejszym niż 2. W Clang i GCC mamy -ftrapv do sprawdzania (podpisanych) przepełnień liczb całkowitych i nie jest to zbyt wolne.
Stąd pytanie: jak możemy uzyskać rozsądną wydajność w Swift bez utraty siatek bezpieczeństwa?
Edit 2: zrobiłem więcej benchmarkingu, z bardzo prostymi pętlami wzdłuż linii z
for i in 0..<n {
x[i] = x[i] ^ 12345678
}
(tutaj operacja xor jest tam tylko po to, abym mógł łatwiej znaleźć odpowiednią pętlę w kodzie złożenia. Próbowałem wybrać operację, która jest łatwa do wykrycia, ale także "nieszkodliwa" w tym sensie, że nie powinna wymagać żadnych kontroli związanych z przepełnieniami całkowitymi.)
Ponownie, była ogromna różnica w wydajności między -O3 i -Ofast. Tak więc spojrzałem na kod montażowy:
Z
-Ofastdostaję to, czego bym się spodziewał. Na istotną częścią jest pętla z 5 instrukcjami języka maszynowego.Z
-O3dostaję coś, co było poza moją najśmielszą wyobraźnią. Wewnętrzna pętla obejmuje 88 linii kodu montażu. Nie próbowałem zrozumieć wszystkiego, ale najbardziej podejrzane części to 13 wywołań "callq _swift_retain" i kolejne 13 wywołań "callq _swift_release". To znaczy, 26 wywołań podprogramu w wewnętrznej pętli!
Edit 3: in comments, Ferruccio poprosił o benchmarki, które są sprawiedliwe w tym sensie, że nie opierają się na wbudowanych funkcjach (np. sort). Myślę, że poniższy program jest dość dobrym przykładem: {]}
let n = 10000
var x = [Int](repeating: 1, count: n)
for i in 0..<n {
for j in 0..<n {
x[i] = x[j]
}
}
Nie ma arytmetyki, więc nie musimy się martwić o przepełnienia liczb całkowitych. Jedyne, co robimy, to mnóstwo odniesień do tablicy. A wyniki są tutaj-Swift-O3 traci o czynnik prawie 500 w porównaniu z-Ofast: {]}
- C++ - O3: 0.05 s
- C++ - O0: 0.4 s
- Java: 0.2 s
- Python with PyPy: 0.5 S
- Python: 12 s
- Swift-Ofast: 0.05 s
- Swift-O3: 23 s
- Swift-O0: 443 s
(jeśli obawiasz się, że kompilator może całkowicie zoptymalizować bezsensowne pętle, możesz zmienić je na np. x[i] ^= x[j] i dodać instrukcję print, która wyprowadza x[0]. To niczego nie zmienia; czasy będą bardzo podobne.)
I tak, tutaj implementacja Pythona była głupią, czystą implementacją Pythona z listą ints i zagnieżdżonymi pętlami. Powinien być znacznie wolniejszy od niepoptymalizowanego Swifta. Coś wydaje się być poważnie zepsute z indeksowaniem Swift i array.
Edit 4: te problemy (jak również niektóre inne problemy z wydajnością) wydają się być naprawione w Xcode 6 beta 5.
Do sortowania mam teraz następujące terminy:
- clang++ - O3: 0.06 s
- swiftc - Ofast: 0.1 S
- swiftc-O: 0.1 S
- swiftc: 4 s
Dla zagnieżdżonych pętli:
- clang++ - O3: 0.06 s
- swiftc-Ofast: 0.3 s
- swiftc-O: 0.4 S
- swiftc: 540 S
Wydaje się, że nie ma już powodu, aby używać niebezpiecznego -Ofast (Alias -Ounchecked); plain -O tworzy równie dobry kod.
8 answers
Tl; dr Swift 1.0 jest teraz tak szybki jak C przez ten benchmark przy użyciu domyślnego poziomu optymalizacji Wydania [- O].
Jest to pierwsza gra z serii, w której można grać na gitarze.]}
func quicksort_swift(inout a:CInt[], start:Int, end:Int) {
if (end - start < 2){
return
}
var p = a[start + (end - start)/2]
var l = start
var r = end - 1
while (l <= r){
if (a[l] < p){
l += 1
continue
}
if (a[r] > p){
r -= 1
continue
}
var t = a[l]
a[l] = a[r]
a[r] = t
l += 1
r -= 1
}
quicksort_swift(&a, start, r + 1)
quicksort_swift(&a, r + 1, end)
}
I to samo w C:
void quicksort_c(int *a, int n) {
if (n < 2)
return;
int p = a[n / 2];
int *l = a;
int *r = a + n - 1;
while (l <= r) {
if (*l < p) {
l++;
continue;
}
if (*r > p) {
r--;
continue;
}
int t = *l;
*l++ = *r;
*r-- = t;
}
quicksort_c(a, r - a + 1);
quicksort_c(l, a + n - l);
}
Obie prace:
var a_swift:CInt[] = [0,5,2,8,1234,-1,2]
var a_c:CInt[] = [0,5,2,8,1234,-1,2]
quicksort_swift(&a_swift, 0, a_swift.count)
quicksort_c(&a_c, CInt(a_c.count))
// [-1, 0, 2, 2, 5, 8, 1234]
// [-1, 0, 2, 2, 5, 8, 1234]
Oba są wywoływane w tym samym programie co napisane.
var x_swift = CInt[](count: n, repeatedValue: 0)
var x_c = CInt[](count: n, repeatedValue: 0)
for var i = 0; i < n; ++i {
x_swift[i] = CInt(random())
x_c[i] = CInt(random())
}
let swift_start:UInt64 = mach_absolute_time();
quicksort_swift(&x_swift, 0, x_swift.count)
let swift_stop:UInt64 = mach_absolute_time();
let c_start:UInt64 = mach_absolute_time();
quicksort_c(&x_c, CInt(x_c.count))
let c_stop:UInt64 = mach_absolute_time();
To zamienia bezwzględne czasy na sekundy:
static const uint64_t NANOS_PER_USEC = 1000ULL;
static const uint64_t NANOS_PER_MSEC = 1000ULL * NANOS_PER_USEC;
static const uint64_t NANOS_PER_SEC = 1000ULL * NANOS_PER_MSEC;
mach_timebase_info_data_t timebase_info;
uint64_t abs_to_nanos(uint64_t abs) {
if ( timebase_info.denom == 0 ) {
(void)mach_timebase_info(&timebase_info);
}
return abs * timebase_info.numer / timebase_info.denom;
}
double abs_to_seconds(uint64_t abs) {
return abs_to_nanos(abs) / (double)NANOS_PER_SEC;
}
[-Onone] no optimizations, the default for debug.
[-O] perform optimizations, the default for release.
[-Ofast] perform optimizations and disable runtime overflow checks and runtime type checks.
Czas w sekundach z [-Onone] dla n=10_000:
Swift: 0.895296452
C: 0.001223848
Oto wbudowane sort () Swifta dla n=10_000:
Swift_builtin: 0.77865783
Oto [- O] dla n=10_000:
Swift: 0.045478346
C: 0.000784666
Swift_builtin: 0.032513488
Jak widać, wydajność Swifta poprawiła się o współczynnik 20.
Zgodnie z odpowiedzią mweathers , ustawienie [- Ofast] robi rzeczywistą różnicę, co daje te czasy dla n=10_000:
Swift: 0.000706745
C: 0.000742374
Swift_builtin: 0.000603576
I dla n=1_000_000:
Swift: 0.107111846
C: 0.114957179
Swift_sort: 0.092688548
Dla porównania, jest to z [- Onone] dla n=1_000_000:
Swift: 142.659763258
C: 0.162065333
Swift_sort: 114.095478272
Więc Swift bez optymalizacji był prawie 1000x wolniejszy niż C w tym benchmarku, na tym etapie jego rozwoju. Z drugiej strony, z obydwoma kompilatorami ustawionymi na [-Ofast] Swift faktycznie działał co najmniej równie dobrze, jeśli nie nieco lepiej niż C.
Zwrócono uwagę, że [- Ofast] zmienia semantykę języka, czyniąc go potencjalnie niebezpieczne. To jest to, co Apple stwierdza w Xcode 5.0 uwagi do wydania:
Oni wszyscy tylko opowiadają się za tym. Czy to mądre, czy nie, nie mogłem powiedzieć, ale z tego, co wiem, wydaje się wystarczająco rozsądne, aby użyć [- Ofast] w wydaniu, jeśli nie wykonujesz arytmetyki zmiennoprzecinkowej o wysokiej precyzji i jesteś pewien, że w twoim programie nie są możliwe przepełnienia liczb całkowitych ani tablic. Jeśli potrzebujesz wysokiej wydajności i sprawdzania przepełnienia / precyzyjnej arytmetyki, wybierz na razie inny język.Nowy poziom optymalizacji-Ofast, dostępny w LLVM, umożliwia agresywne optymalizacje. - Ofast łagodzi pewne konserwatywne ograniczenia, głównie dla operacji zmiennoprzecinkowych, które są bezpieczne dla większości kodu. Może przynieść znaczne korzyści z wysokiej wydajności kompilatora.
AKTUALIZACJA BETA 3:
N = 10_000 Z [- O]:
Swift: 0.019697268
C: 0.000718064
Swift_sort: 0.002094721
Swift ogólnie jest nieco szybszy i wygląda na to, że Wbudowany sort Swifta ma zmienił się dość znacząco.
OSTATNIA AKTUALIZACJA:
[-Onone]:
Swift: 0.678056695
C: 0.000973914
[-O]:
Swift: 0.001158492
C: 0.001192406
[-Ounchecked]:
Swift: 0.000827764
C: 0.001078914
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-09-25 09:36:39
TL; DR: Tak, jedyna implementacja języka Swift jest powolna, w tej chwili. Jeśli potrzebujesz szybkiego, numerycznego (i innych rodzajów kodu, prawdopodobnie) kodu, po prostu wybierz inny. W przyszłości powinieneś ponownie ocenić swój wybór. Może to być jednak wystarczająco dobre dla większości kodu aplikacji, który jest napisany na wyższym poziomie.
Z tego, co widzę w SIL i LLVM IR, wygląda na to, że potrzebują kilku optymalizacji do usuwania zatrzymań i wydań, które mogą być zaimplementowano w Clang (dla Objective-C), ale jeszcze ich nie przeportowano. Z tą teorią się Zgadzam (na razie... muszę jeszcze potwierdzić, że Clang coś z tym robi), ponieważ profiler uruchomiony na ostatnim przypadku testowym tego pytania daje ten "ładny" wynik: {]}
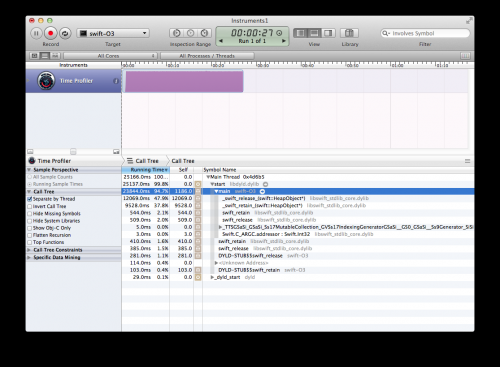
Jak zostało powiedziane przez wielu innych, -Ofast jest całkowicie niebezpieczne i zmienia semantykę języka. Dla mnie jest to etap "jeśli masz zamiar tego użyć, po prostu użyj innego języka". Ja oceń ten wybór później, jeśli się zmieni.
-O3 / align = "center" bgcolor = "# e0ffe0 " / cesarz chin / / align = center / Optymalizator powinien usunąć (większość) z nich AFAICT, ponieważ zna większość informacji o tablicy i wie, że ma (przynajmniej) silne odniesienie do niej.
Nie powinien emitować więcej zatrzymań, gdy nawet nie wywołuje funkcji, które mogłyby zwolnić obiekty. Nie sądzę, żeby konstruktor tablicy może zwrócić tablicę, która jest mniejsza niż ta, o którą poproszono, co oznacza, że wiele kontroli, które zostały wyemitowane, jest bezużytecznych. Wie również, że liczba całkowita nigdy nie będzie wyższa niż 10k, więc sprawdzanie przepełnienia Może być zoptymalizowane (nie ze względu na dziwność -Ofast, ale ze względu na semantykę języka(nic innego nie zmienia, że var nie może uzyskać do niego dostępu, a dodanie do 10K jest bezpieczne dla typu Int).
Kompilator może nie być w stanie rozpakować tablicy lub tablicy elementy, ponieważ są przekazywane do sort(), która jest zewnętrzną funkcją I musi uzyskać argumenty, których oczekuje. Spowoduje to, że będziemy musieli użyć wartości Int pośrednio, co sprawi, że będzie to działać nieco wolniej. Może się to zmienić, jeśli funkcja ogólna sort() (nie w sposób wielowątkowy) będzie dostępna dla kompilatora i zostanie zainlinowana.
Jest to bardzo nowy (publicznie) język i przechodzi przez to, co zakładam, że jest wiele zmian, ponieważ są ludzie (mocno) język Swift prosi o opinie i wszyscy mówią, że język nie jest skończony i się zmieni.
Użyty kod:
import Cocoa
let swift_start = NSDate.timeIntervalSinceReferenceDate();
let n: Int = 10000
let x = Int[](count: n, repeatedValue: 1)
for i in 0..n {
for j in 0..n {
let tmp: Int = x[j]
x[i] = tmp
}
}
let y: Int[] = sort(x)
let swift_stop = NSDate.timeIntervalSinceReferenceDate();
println("\(swift_stop - swift_start)s")
P. s: nie jestem ekspertem od Objective-C ani wszystkich urządzeń z Cocoa , Objective-C, czy Swift runtimes. Mogę też zakładać pewne rzeczy, których nie napisałem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-06-22 21:55:11
W tym samym czasie, w którym się pojawiłem, postanowiłem rzucić na to okiem dla zabawy, a oto momenty, które otrzymałem:
Swift 4.0.2 : 0.83s (0.74s with `-Ounchecked`)
C++ (Apple LLVM 8.0.0): 0.74s
Swift
// Swift 4.0 code
import Foundation
func doTest() -> Void {
let arraySize = 10000000
var randomNumbers = [UInt32]()
for _ in 0..<arraySize {
randomNumbers.append(arc4random_uniform(UInt32(arraySize)))
}
let start = Date()
randomNumbers.sort()
let end = Date()
print(randomNumbers[0])
print("Elapsed time: \(end.timeIntervalSince(start))")
}
doTest()
Wyniki:
Swift 1.1
xcrun swiftc --version
Swift version 1.1 (swift-600.0.54.20)
Target: x86_64-apple-darwin14.0.0
xcrun swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 1.02204304933548
Swift 1.2
xcrun swiftc --version
Apple Swift version 1.2 (swiftlang-602.0.49.6 clang-602.0.49)
Target: x86_64-apple-darwin14.3.0
xcrun -sdk macosx swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 0.738763988018036
Swift 2.0
xcrun swiftc --version
Apple Swift version 2.0 (swiftlang-700.0.59 clang-700.0.72)
Target: x86_64-apple-darwin15.0.0
xcrun -sdk macosx swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 0.767306983470917
Wydaje się być taka sama wydajność, jeśli kompiluję z -Ounchecked.
Swift 3.0
xcrun swiftc --version
Apple Swift version 3.0 (swiftlang-800.0.46.2 clang-800.0.38)
Target: x86_64-apple-macosx10.9
xcrun -sdk macosx swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 0.939633965492249
xcrun -sdk macosx swiftc -Ounchecked SwiftSort.swift
./SwiftSort
Elapsed time: 0.866258025169373
-O i -Ounchecked po raz pierwszy.
Swift 4.0
xcrun swiftc --version
Apple Swift version 4.0.2 (swiftlang-900.0.69.2 clang-900.0.38)
Target: x86_64-apple-macosx10.9
xcrun -sdk macosx swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 0.834299981594086
xcrun -sdk macosx swiftc -Ounchecked SwiftSort.swift
./SwiftSort
Elapsed time: 0.742045998573303
Swift 4 ponownie poprawia wydajność, zachowując lukę między -O a -Ounchecked. -O -whole-module-optimization wydawało się, że nie robi różnicy.
C++
#include <chrono>
#include <iostream>
#include <vector>
#include <cstdint>
#include <stdlib.h>
using namespace std;
using namespace std::chrono;
int main(int argc, const char * argv[]) {
const auto arraySize = 10000000;
vector<uint32_t> randomNumbers;
for (int i = 0; i < arraySize; ++i) {
randomNumbers.emplace_back(arc4random_uniform(arraySize));
}
const auto start = high_resolution_clock::now();
sort(begin(randomNumbers), end(randomNumbers));
const auto end = high_resolution_clock::now();
cout << randomNumbers[0] << "\n";
cout << "Elapsed time: " << duration_cast<duration<double>>(end - start).count() << "\n";
return 0;
}
Wyniki:
Apple Clang 6.0
clang++ --version
Apple LLVM version 6.0 (clang-600.0.54) (based on LLVM 3.5svn)
Target: x86_64-apple-darwin14.0.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.688969
Apple Clang 6.1.0
clang++ --version
Apple LLVM version 6.1.0 (clang-602.0.49) (based on LLVM 3.6.0svn)
Target: x86_64-apple-darwin14.3.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.670652
Apple Clang 7.0.0
clang++ --version
Apple LLVM version 7.0.0 (clang-700.0.72)
Target: x86_64-apple-darwin15.0.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.690152
Apple Clang 8.0.0
clang++ --version
Apple LLVM version 8.0.0 (clang-800.0.38)
Target: x86_64-apple-darwin15.6.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.68253
Apple Clang 9.0.0
clang++ --version
Apple LLVM version 9.0.0 (clang-900.0.38)
Target: x86_64-apple-darwin16.7.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.736784
Werdykt
W momencie pisania tego tekstu, sortowanie Swifta jest szybkie, ale nie tak szybkie jak sortowanie C++, gdy jest skompilowane z -O, z powyższymi kompilatorami i bibliotekami. Z -Ounchecked, wydaje się być tak szybki jak C++ w Swift 4.0.2 i Apple LLVM 9.0.0.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-01 21:27:32
Od The Swift Programming Language:
Funkcja sortowania Biblioteka Standardowa Swift udostępnia funkcję o nazwie sort, który sortuje tablicę wartości znanego typu, na podstawie wyjście zamknięcia sortowania, które dostarczasz. Po zakończeniu procesu sortowania, funkcja sort zwraca nową tablicę o tej samej typ i rozmiar jak stary, z jego elementami w poprawnym posortowaniu spokój.
Funkcja sort posiada dwie deklaracje.
Domyślna deklaracja, która pozwala określić zakończenie porównania:
func sort<T>(array: T[], pred: (T, T) -> Bool) -> T[]
I druga deklaracja, która przyjmuje tylko jeden parametr (tablicę) i jest " zakodowana na twardo, aby użyć komparatora less-than."
func sort<T : Comparable>(array: T[]) -> T[]
Example:
sort( _arrayToSort_ ) { $0 > $1 }
Przetestowałem zmodyfikowaną wersję Twojego kodu na placu zabaw z włączonym zamknięciem, aby móc dokładniej monitorować funkcję, i odkryłem, że z n ustawionym na 1000, zamknięcie było wywoływane około 11,000 razy.
let n = 1000
let x = Int[](count: n, repeatedValue: 0)
for i in 0..n {
x[i] = random()
}
let y = sort(x) { $0 > $1 }
Nie jest funkcją efektywną, a Polecam użycie lepszej implementacji funkcji sortowania.
EDIT:
Zajrzałem na stronę quicksort wikipedia i napisałem dla niej szybką implementację. Oto pełny program, którego użyłem (na placu zabaw)import Foundation
func quickSort(inout array: Int[], begin: Int, end: Int) {
if (begin < end) {
let p = partition(&array, begin, end)
quickSort(&array, begin, p - 1)
quickSort(&array, p + 1, end)
}
}
func partition(inout array: Int[], left: Int, right: Int) -> Int {
let numElements = right - left + 1
let pivotIndex = left + numElements / 2
let pivotValue = array[pivotIndex]
swap(&array[pivotIndex], &array[right])
var storeIndex = left
for i in left..right {
let a = 1 // <- Used to see how many comparisons are made
if array[i] <= pivotValue {
swap(&array[i], &array[storeIndex])
storeIndex++
}
}
swap(&array[storeIndex], &array[right]) // Move pivot to its final place
return storeIndex
}
let n = 1000
var x = Int[](count: n, repeatedValue: 0)
for i in 0..n {
x[i] = Int(arc4random())
}
quickSort(&x, 0, x.count - 1) // <- Does the sorting
for i in 0..n {
x[i] // <- Used by the playground to display the results
}
Używając tego z n=1000, stwierdziłem, że
- quickSort () został wywołany około 650 razy,
- około 6000 swapów zostało wykonanych,
- i jest około 10 000 porównań
Wygląda na to, że wbudowany sort metoda jest (lub jest blisko) szybkim sortowaniem i jest naprawdę powolna...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-06-16 14:06:27
Od Xcode 7 można włączyć Fast, Whole Module Optimization. Powinno to natychmiast zwiększyć wydajność.

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-06-11 16:56:04
Swift array performance revisited:
Napisałem własny benchmark porównujący Swift z C / Objective - C. mój benchmark oblicza liczby pierwsze. Używa tablicy poprzednich liczb pierwszych, aby szukać czynników pierwszych w każdym nowym kandydacie, więc jest to dość szybkie. Jednak robi mnóstwo odczytu tablic i mniej zapisu do tablic.
Początkowo zrobiłem ten benchmark przeciwko Swift 1.2. Postanowiłem zaktualizować projekt i uruchomić go pod Swift 2.0.
Projekt pozwala Wybierz pomiędzy używaniem zwykłych tablic swift a używaniem bezpiecznych buforów pamięci Swift przy użyciu semantyki tablicy.
Dla C/Objective-C, możesz użyć tablic NSArrays lub C malloc ' ed.
Wyniki testów wydają się być bardzo podobne z najszybszą, najmniejszą optymalizacją kodu ([- 0s]) lub najszybszą, agresywną ([- 0fast]) optymalizacją.
Wydajność Swift 2.0 jest nadal okropna z wyłączoną optymalizacją kodu, podczas gdy wydajność C/Objective-C jest tylko umiarkowana wolniej.
Najważniejsze jest to, że obliczenia oparte na tablicy C malloc ' D są najszybsze, o skromny margines
Swift z niebezpiecznymi buforami zajmuje około 1,19 x - 1,20 x dłużej niż tablice C przy zastosowaniu najszybszej, najmniejszej optymalizacji kodu. różnica wydaje się nieco mniejsza przy szybkiej, agresywnej optymalizacji (Swift zajmuje więcej od 1,18 X do 1,16 x dłużej niż C.
Jeśli używasz zwykłych tablic Swift, różnica z C jest nieznacznie większa. (Swift zajmuje ~1.22 do 1.23 dłużej.)
Zwykłe tablice Swift są DRAMATICALLY szybsze niż w Swift 1.2 / Xcode 6. Ich wydajność jest tak bliska tablicom opartym na bezpiecznych buforach Swift, że używanie niebezpiecznych buforów pamięci nie wydaje się już warte zachodu, co jest duże.
BTW, Objective - C nsArray wydajność śmierdzi. Jeśli zamierzasz używać natywnych obiektów kontenera w obu językach, Swift jest dramatycznie szybszy.
Możesz sprawdzić mój projekt na GitHubie pod adresem SwiftPerformanceBenchmark
Posiada prosty interfejs, który ułatwia zbieranie statystyk.
Interesujące jest to, że sortowanie wydaje się być nieco szybsze w języku Swift niż w C, ale ten algorytm liczb pierwszych jest jeszcze szybszy w języku Swift.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-02-26 01:31:03
Głównym problemem, o którym wspominają inni, ale nie przywołanym wystarczająco, jest to, że -O3 nic nie robi w Swifcie (i nigdy nie robił), więc po skompilowaniu z tym jest efektywnie nieoptymalizowany (-Onone).
Nazwy opcji zmieniały się z czasem, więc niektóre inne odpowiedzi mają przestarzałe flagi dla opcji budowania. Poprawne bieżące opcje (Swift 2.2) to:
-Onone // Debug - slow
-O // Optimised
-O -whole-module-optimization //Optimised across files
Optymalizacja całego modułu ma wolniejszą kompilację, ale może zoptymalizować pliki wewnątrz modułu, tj. w ramach każdego frameworka i w ramach rzeczywistego kodu aplikacji, ale nie między nimi. Powinieneś użyć tego do wszystkiego, co krytyczne dla wydajności)
Można również wyłączyć kontrole bezpieczeństwa dla jeszcze większej prędkości, ale ze wszystkimi twierdzeniami i warunkami wstępnymi nie tylko wyłączonymi, ale zoptymalizowanymi na podstawie ich poprawności. Jeśli kiedykolwiek trafisz na twierdzenie, oznacza to, że jesteś w nieokreślonym zachowaniu. Używaj ze szczególną ostrożnością i tylko wtedy, gdy stwierdzisz, że przyspieszenie prędkości jest dla Ciebie opłacalne (testując). Jeśli go znajdziesz cenny dla jakiegoś kodu polecam rozdzielenie tego kodu na osobny framework i wyłączenie tylko kontroli bezpieczeństwa dla tego modułu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-04-13 10:58:05
func partition(inout list : [Int], low: Int, high : Int) -> Int {
let pivot = list[high]
var j = low
var i = j - 1
while j < high {
if list[j] <= pivot{
i += 1
(list[i], list[j]) = (list[j], list[i])
}
j += 1
}
(list[i+1], list[high]) = (list[high], list[i+1])
return i+1
}
func quikcSort(inout list : [Int] , low : Int , high : Int) {
if low < high {
let pIndex = partition(&list, low: low, high: high)
quikcSort(&list, low: low, high: pIndex-1)
quikcSort(&list, low: pIndex + 1, high: high)
}
}
var list = [7,3,15,10,0,8,2,4]
quikcSort(&list, low: 0, high: list.count-1)
var list2 = [ 10, 0, 3, 9, 2, 14, 26, 27, 1, 5, 8, -1, 8 ]
quikcSort(&list2, low: 0, high: list2.count-1)
var list3 = [1,3,9,8,2,7,5]
quikcSort(&list3, low: 0, high: list3.count-1)
Możesz spojrzeć na algorytm partycjonowania Lomuto w partycjonowaniu listy. Napisane w Swift
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-03-25 17:30:49