Używanie group by na wielu kolumnach
Rozumiem sens GROUP BY x.
Ale jak działa GROUP BY x, y i co to oznacza?
4 answers
Group By X oznacza Umieść wszystkie te o tej samej wartości dla X w jednej grupie .
Group By X, Y oznacza umieścić wszystkie te z tymi samymi wartościami dla obu X i Y w jednej grupie .
Aby zilustrować na przykładzie, załóżmy, że mamy następującą tabelę, aby zrobić z tym, kto uczęszcza na jaki przedmiot na Uniwersytecie:
Table: Subject_Selection
+---------+----------+----------+
| Subject | Semester | Attendee |
+---------+----------+----------+
| ITB001 | 1 | John |
| ITB001 | 1 | Bob |
| ITB001 | 1 | Mickey |
| ITB001 | 2 | Jenny |
| ITB001 | 2 | James |
| MKB114 | 1 | John |
| MKB114 | 1 | Erica |
+---------+----------+----------+
Gdy używasz group by tylko w kolumnie temat; powiedz:
select Subject, Count(*)
from Subject_Selection
group by Subject
Dostaniesz coś w stylu:
+---------+-------+
| Subject | Count |
+---------+-------+
| ITB001 | 5 |
| MKB114 | 2 |
+---------+-------+
...bo jest 5 wpisów dla ITB001 i 2 dla MKB114
Gdybyśmy mieli group by dwie kolumny:
select Subject, Semester, Count(*)
from Subject_Selection
group by Subject, Semester
Dostalibyśmy to:
+---------+----------+-------+
| Subject | Semester | Count |
+---------+----------+-------+
| ITB001 | 1 | 3 |
| ITB001 | 2 | 2 |
| MKB114 | 1 | 2 |
+---------+----------+-------+
Dzieje się tak dlatego, że gdy grupujemy dwie kolumny, mówi się " Grupuj je tak, aby wszystkie osoby z tym samym przedmiotem i semestrem znalazły się w tej samej grupie, a następnie obliczamy wszystkie zagregowane funkcje (liczenie, suma, średnia itp.) dla każdej z tych grup". W tym przykładzie świadczy o tym fakt, że gdy je policzymy, są trzy osoby robiące to w pierwszym semestrze, i dwie osoby robiące to w drugim semestrze. W 2011 roku, w ramach programu MKB114, w ramach programu MKB114, w ramach programu MKB114, w ramach programu MKB114, w ramach programu MKB114, w ramach programu MKB114, w ramach programu MKB114, w ramach programu MKB114, w ramach programu MKB114.]} Mam nadzieję, że to ma sens.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-08-02 00:49:59
Tutaj wyjaśnię nie tylko użycie klauzuli grupowej, ale także użycie funkcji zbiorczych.
Klauzula GROUP BY jest używana w połączeniu z funkcjami agregującymi do grupowania wyników-ustawionych przez jedną lub więcej kolumn. np.:
-- GROUP BY with one parameter:
SELECT column_name, AGGREGATE_FUNCTION(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
-- GROUP BY with two parameters:
SELECT
column_name1,
column_name2,
AGGREGATE_FUNCTION(column_name3)
FROM
table_name
GROUP BY
column_name1,
column_name2;
Zapamiętaj ten rozkaz:
SELECT (służy do wybierania danych z bazy danych)
FROM (klauzula jest używana do wyświetlania tabel)
WHERE (klauzula służy do filtrowania records)
GROUP BY (klauzula może być używana w instrukcji SELECT do zbierania danych w wielu rekordach i pogrupować wyniki według jednej lub więcej kolumn)
HAVING (klauzula jest używana w połączeniu z klauzulą GROUP BY do ogranicz grupy zwracanych wierszy tylko do tych, których warunek jest prawdą)
Uporządkuj według (do sortowania wyników służy słowo kluczowe)
Możesz użyć wszystkich z nich, jeśli używasz agregować funkcje, i to jest kolejność, że muszą być ustawione, w przeciwnym razie można uzyskać błąd.
Funkcje zbiorcze to:
MIN () Zwraca najmniejszą wartość w danej kolumnie
MAX () Zwraca maksymalną wartość w danej kolumnie.
Sum () Zwraca sumę wartości liczbowych w danej kolumnie
AVG () Zwraca średnią wartość danej kolumny
COUNT () zwraca całkowitą liczbę wartości w danej kolumnie
COUNT ( * ) Zwraca liczbę wierszy w tabeli
Przykłady skryptów SQL na temat korzystania z funkcji zbiorczych:
Powiedzmy, że musimy znaleźć zlecenia sprzedaży, których całkowita sprzedaż jest większa niż $950. Aby to osiągnąć, łączymy klauzulę HAVING i klauzulę GROUP BY:
SELECT
orderId, SUM(unitPrice * qty) Total
FROM
OrderDetails
GROUP BY orderId
HAVING Total > 950;
Zliczanie wszystkich rozkazów i grupowanie ich customerID oraz sortowanie wyniku Ascendent. Łączymy funkcję COUNT i GROUP BY, ORDER BY klauzule i ASC:
SELECT
customerId, COUNT(*)
FROM
Orders
GROUP BY customerId
ORDER BY COUNT(*) ASC;
Pobierz kategorię, która ma średnią cenę jednostkową większą niż $10, używając funkcji AVG połącz z GROUP BY i HAVING klauzulami:
SELECT
categoryName, AVG(unitPrice)
FROM
Products p
INNER JOIN
Categories c ON c.categoryId = p.categoryId
GROUP BY categoryName
HAVING AVG(unitPrice) > 10;
Uzyskanie tańszego produktu z każdej kategorii, za pomocą funkcji MIN w zapytaniu podrzędnym:
SELECT categoryId,
productId,
productName,
unitPrice
FROM Products p1
WHERE unitPrice = (
SELECT MIN(unitPrice)
FROM Products p2
WHERE p2.categoryId = p1.categoryId)
Poniższe polecenie grupuje wiersze o tych samych wartościach w obu categoryId oraz productId kolumny:
SELECT
categoryId, categoryName, productId, SUM(unitPrice)
FROM
Products p
INNER JOIN
Categories c ON c.categoryId = p.categoryId
GROUP BY categoryId, productId
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2021-02-08 15:29:43
Jak rozumiesz punkt grupy przez x. tutaj x to nazwa kolumny tabeli. Jest to wywołanie GROUP By Table Single Column_Name. W GROUP By x, y. oznacza to, że Tabela GROUP By Two Column_Names x and y. jest to tzw. "wiele grupujących kolumn". Mogę to wyjaśnić bardziej szczegółowo poniżej.
W SQL Instrukcja GROUP BY służy do porządkowania identycznych danych w grupy za pomocą niektórych funkcji. Przykład: - Jeśli a dana kolumna ma te same wartości w różnych wierszach, a następnie ułoży te wiersze w grupie. Ta klauzula GROUP BY jest następująca po klauzuli Gdzie w instrukcji SELECT i poprzedza ORDER BY klauzula. Są to ważne punkty: -
- Klauzula GROUP BY jest używana z instrukcją SELECT .
- w zapytaniu klauzula GROUP BY jest umieszczona po klauzuli Gdzie .
- w zapytaniu grupa Klauzula BY jest umieszczana przed ORDER BY klauzula jeśli jest używana.
Podstawowa składnia klauzuli GROUP BY jest pokazana w poniższym bloku kodu. Klauzula GROUP BY musi spełniać warunki w klauzuli Gdzie I musi poprzedzać klauzulę ORDER BY jeśli jest używana.
SELECT column1, column2
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2
ORDER BY column1, column2
- nazwa_funkcji: - Nazwa użytej funkcji na przykład MIN (), MAX (), SUM (), AVG (), COUNT ().
- table_name:- Name of stół.
- condition:- Condition used.
Klauzula GROUP BY może zawierać dwie lub więcej kolumn-innymi słowy, grupa może składać się z dwóch lub więcej kolumn. Zilustrujemy to dwoma przykładami.
W pierwszy przykład grupujemy pojedynczą kolumnę, aby umieścić wszystkie wiersze o tej samej wartości tylko tej konkretnej kolumny w jednej grupie. To jest Szczegóły tabeli pracowników: -
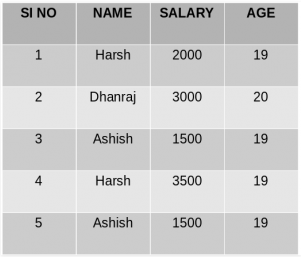
Potraktuj zapytanie jako pokazano poniżej dla grupy według pojedynczej kolumny w tabeli pracowników:-
SELECT NAME, SUM(SALARY)
FROM Employee
GROUP BY NAME;
Wyjście grupy przez pojedynczą kolumnę to:-
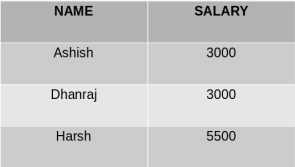
Jak widać na powyższym wyjściu, wiersze o zduplikowanych nazwach są pogrupowane pod tą samą nazwą, a ich odpowiadająca pensja jest sumą wynagrodzenia zduplikowanych wierszy. Funkcja SUM() SQL jest tutaj używana do obliczania sumy.
W drugim przykładzie grupujemy według wielu kolumn. Oznacza to umieszczenie wszystkich wiersze o tych samych wartościach obu kolumn column1 i column2 w jednej grupie. Zobacz tabelę uczniów poniżej: -
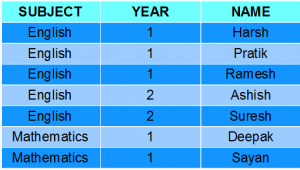
Rozważmy poniższe zapytanie dla grupy według wielu kolumn w tabeli uczniów:-
SELECT SUBJECT, YEAR, Count(*)
FROM Student
GROUP BY SUBJECT, YEAR;
Wyjście grupy przez wiele kolumn to:-
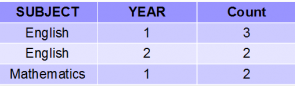
Jak widać na powyższym wykładzie uczniowie z tego samego przedmiotu I roku są umieszczani w tej samej grupie. I tych, których jedyny przedmiot jest taki sam, ale nie Rok należy do różnych grup. Więc tutaj pogrupowaliśmy tabelę według dwóch kolumn lub więcej niż jednej kolumny.
Podobnie jak w przypadku Uporządkuj według, możemy zastąpić liczby nazw kolumn w grupie klauzulą. Generalnie zaleca się to robić tylko wtedy, gdy grupujesz wiele kolumn lub gdy coś innego powoduje, że tekst w klauzuli GROUP BY jest zbyt długi. Są to niektóre podstawowe regiony do użycia GROUP BY w SQL.
- The GROUP BY Klauzula SQL służy do grupowania wierszy o tych samych wartościach.
- Klauzula GROUP BY jest używana razem z instrukcją SQL SELECT .
- Instrukcja SELECT użyta w klauzuli GROUP BY może być używana tylko w nazwach kolumn, funkcji agregujących, stałych i wyrażeń.
- SQLHaving Clause jest używany do ograniczenia wyników zwracanych przez grupę przez klauzulę.
- GRUPA MYSQL Klauzula by jest używana do zbierania danych z wielu rekordów i zwracanego rekordu ustawionego przez jedną lub więcej kolumn.
To jest GROUP BY oficjalny dokument SQL, aby lepiej zrozumieć grupę BY.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2021-01-21 05:37:29
W prostym języku angielskim z GROUP BY z dwoma parametrami to co robimy to szukamy podobnych par wartości i otrzymujemy liczbę do trzeciej kolumny.
Spójrz na poniższy przykład w celach informacyjnych. Tutaj używam Międzynarodowe wyniki piłkarskie od 1872 do 2020
+----------+----------------+--------+---+---+--------+---------+-------------------+-----+
| _c0| _c1| _c2|_c3|_c4| _c5| _c6| _c7| _c8|
+----------+----------------+--------+---+---+--------+---------+-------------------+-----+
|1872-11-30| Scotland| England| 0| 0|Friendly| Glasgow| Scotland|FALSE|
|1873-03-08| England|Scotland| 4| 2|Friendly| London| England|FALSE|
|1874-03-07| Scotland| England| 2| 1|Friendly| Glasgow| Scotland|FALSE|
|1875-03-06| England|Scotland| 2| 2|Friendly| London| England|FALSE|
|1876-03-04| Scotland| England| 3| 0|Friendly| Glasgow| Scotland|FALSE|
|1876-03-25| Scotland| Wales| 4| 0|Friendly| Glasgow| Scotland|FALSE|
|1877-03-03| England|Scotland| 1| 3|Friendly| London| England|FALSE|
|1877-03-05| Wales|Scotland| 0| 2|Friendly| Wrexham| Wales|FALSE|
|1878-03-02| Scotland| England| 7| 2|Friendly| Glasgow| Scotland|FALSE|
|1878-03-23| Scotland| Wales| 9| 0|Friendly| Glasgow| Scotland|FALSE|
|1879-01-18| England| Wales| 2| 1|Friendly| London| England|FALSE|
|1879-04-05| England|Scotland| 5| 4|Friendly| London| England|FALSE|
|1879-04-07| Wales|Scotland| 0| 3|Friendly| Wrexham| Wales|FALSE|
|1880-03-13| Scotland| England| 5| 4|Friendly| Glasgow| Scotland|FALSE|
|1880-03-15| Wales| England| 2| 3|Friendly| Wrexham| Wales|FALSE|
|1880-03-27| Scotland| Wales| 5| 1|Friendly| Glasgow| Scotland|FALSE|
|1881-02-26| England| Wales| 0| 1|Friendly|Blackburn| England|FALSE|
|1881-03-12| England|Scotland| 1| 6|Friendly| London| England|FALSE|
|1881-03-14| Wales|Scotland| 1| 5|Friendly| Wrexham| Wales|FALSE|
|1882-02-18|Northern Ireland| England| 0| 13|Friendly| Belfast|Republic of Ireland|FALSE|
+----------+----------------+--------+---+---+--------+---------+-------------------+-----+
A teraz idę do grupy według podobnego kraju (kolumna _c7) i turnieju(_c5) wartości pary GROUP BY operacji,
SELECT `_c5`,`_c7`,count(*) FROM res GROUP BY `_c5`,`_c7`
+--------------------+-------------------+--------+
| _c5| _c7|count(1)|
+--------------------+-------------------+--------+
| Friendly| Southern Rhodesia| 11|
| Friendly| Ecuador| 68|
|African Cup of Na...| Ethiopia| 41|
|Gold Cup qualific...|Trinidad and Tobago| 9|
|AFC Asian Cup qua...| Bhutan| 7|
|African Nations C...| Gabon| 2|
| Friendly| China PR| 170|
|FIFA World Cup qu...| Israel| 59|
|FIFA World Cup qu...| Japan| 61|
|UEFA Euro qualifi...| Romania| 62|
|AFC Asian Cup qua...| Macau| 9|
| Friendly| South Sudan| 1|
|CONCACAF Nations ...| Suriname| 3|
| Copa Newton| Argentina| 12|
| Friendly| Philippines| 38|
|FIFA World Cup qu...| Chile| 68|
|African Cup of Na...| Madagascar| 29|
|FIFA World Cup qu...| Burkina Faso| 30|
| UEFA Nations League| Denmark| 4|
| Atlantic Cup| Paraguay| 2|
+--------------------+-------------------+--------+
Explanation: znaczenie pierwszego wiersza polega na tym, że były Łącznie na terenie Rodezji Południowej odbyło się 11 towarzyskich turniejów.
Uwaga: tutaj obowiązkowe jest użycie kolumny licznika w tym przypadku.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-12-26 14:33:58