W jakich okolicznościach listy połączone są przydatne?
Najczęściej widzę, że ludzie próbują używać linkowanych list, wydaje mi się to słabym (lub bardzo słabym) wyborem. Być może warto byłoby zbadać okoliczności, w których powiązana lista jest lub nie jest dobrym wyborem struktury danych.
Najlepiej byłoby odpowiedzieć na kryteria, które należy zastosować przy wyborze struktury danych i które struktury danych mogą działać najlepiej w określonych okolicznościach.
Edit: muszę powiedzieć, że jestem pod wrażeniem nie tylko liczby, ale jakość odpowiedzi. Mogę zaakceptować tylko jedną, ale są jeszcze dwie lub trzy, które muszę powiedzieć, że warto byłoby zaakceptować, gdyby nie było czegoś lepszego. Tylko kilka (zwłaszcza ta, którą zaakceptowałem) wskazało na sytuacje, w których powiązana lista zapewniła prawdziwą przewagę. Myślę, że Steve Jessop zasługuje na jakieś wyróżnienie za wymyślenie Nie jednej, ale trzech różnych odpowiedzi, z których wszystkie uważam za imponujące. Oczywiście, mimo że została zamieszczona tylko jako komentarz, a nie ODPOWIEDŹ, myślę, że wpis Neila na blogu jest również wart przeczytania - nie tylko pouczający, ale także całkiem zabawny.
15 answers
Mogą być użyteczne dla współbieżnych struktur danych. (Poniżej znajduje się próbka nie współbieżnego użycia w świecie rzeczywistym - tego by nie było, gdyby @Neil nie wspominałem o Fortranie. ;-)
Na przykład, ConcurrentDictionary<TKey, TValue> W.NET 4.0 RC używa połączonych list do elementów łańcucha, które hashują do tego samego zasobnika.
Podstawowa struktura danych dla ConcurrentStack<T> jest również listą połączoną.
ConcurrentStack<T> jest jedną ze struktur danych, które służą jako podstawa dla nowego wątku Pool , (z lokalnymi "kolejkami" zaimplementowanymi jako stosy, zasadniczo). (Druga główna konstrukcja nośna to ConcurrentQueue<T>.)
Nowa pula wątków z kolei stanowi podstawę do planowania pracy nowego Task Parallel Library .
Więc z pewnością mogą być użyteczne - powiązana lista służy obecnie jako jedna z głównych konstrukcji nośnych co najmniej jednej wielkiej nowej technologii.
(pojedynczo linkowana lista sprawia, że jest ona atrakcyjna BEZ blokady - ale w takich przypadkach nie można czekać na wybór, ponieważ główne operacje mogą być wykonywane za pomocą jednego CAS (+powtórzenia). W nowoczesnych środowiskach GC-D - takich jak Java i. NET-problem ABA można łatwo uniknąć. Wystarczy zawinąć elementy, które dodajesz w świeżo utworzonych węzłach i nie używać ich ponownie-pozwól GC wykonać swoją pracę. Strona o problemie ABA zapewnia również implementację stosu wolnego od blokady-który faktycznie działa w. Net (&Java) z węzłem (GC-ed) trzymającym pozycji.)
Edit :
@ Neil:
właściwie to, co wspomniałeś o Fortranie, przypomniało mi, że ten sam rodzaj połączonych list można znaleźć w prawdopodobnie najczęściej używanej i nadużywanej strukturze danych w. NET:
plain. NET generic Dictionary<TKey, TValue>.
Nie jedna, ale wiele połączonych list jest przechowywanych w tablicy.
- pozwala uniknąć wielu małych (de)przydziałów przy wstawianiu/usuwaniu.
- początkowe Ładowanie tabeli hash jest dość szybkie, ponieważ tablica jest wypełniana sekwencyjnie (gra bardzo ładnie z cache procesora).
- nie wspominając już o tym, że tablica haszująca jest droga pod względem pamięci - i ta "sztuczka" tnie "rozmiary wskaźników" o połowę na x64.
Zasadniczo wiele połączonych list jest przechowywanych w tablicy. (po jednym na każde używane wiadro.) Wolna lista węzłów wielokrotnego użytku jest "przeplatana" między nimi(jeśli były usuwane). Tablica jest przydzielana na początku / na początku, a węzły łańcuchów są w niej przechowywane. Istnieje również wolny Wskaźnik-Indeks do tablicy-następuje usunięcie. ;- ) Więc-Wierzcie lub nie - Technika FORTRAN nadal żyje. (...i nigdzie indziej, niż w jednej z najczęściej używanych struktur danych. NET; -).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:02:05
Listy linkowane są bardzo przydatne, gdy trzeba zrobić dużo wstawiania i usuwania, ale nie za dużo wyszukiwania, na liście o dowolnej (nieznanej w czasie kompilacji) długości.
Dzielenie i łączenie (dwukierunkowe) list jest bardzo efektywne.
Można również łączyć listy połączone - np. struktury drzewiaste mogą być zaimplementowane jako "pionowe" listy połączone (relacje rodzic/dziecko) łącząc ze sobą połączone listy poziome (rodzeństwo).
Używanie listy opartej na tablicy dla cele te mają poważne ograniczenia:
- dodanie nowego elementu oznacza, że tablica musi zostać ponownie przydzielona (lub musisz przydzielić więcej miejsca niż potrzebujesz, aby umożliwić przyszły wzrost i zmniejszyć liczbę ponownych alokacji)
- usunięcie przedmiotów pozostawia zmarnowane miejsce lub wymaga realokacji
- wstawianie elementów w dowolnym miejscu z wyjątkiem końca polega na (ewentualnie ponownym przydzieleniu i) kopiowaniu partii danych w górę o jedną pozycję
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-11 22:46:28
Listy połączone są bardzo elastyczne: po modyfikacji jednego wskaźnika można dokonać ogromnej zmiany, gdzie ta sama operacja byłaby bardzo nieefektywna na liście tablic.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-11 22:37:56
Tablice są strukturami danych, do których zwykle porównywane są połączone listy.
Normalnie połączone listy są przydatne, gdy trzeba dokonać wielu modyfikacji samej listy, podczas gdy tablice działają lepiej niż listy przy bezpośrednim dostępie do elementu.
Oto lista operacji, które mogą być wykonywane na listach i tablicach, w porównaniu ze względnym kosztem operacji (N = długość listy/tablicy):
- Dodawanie elementu:
- na listach wystarczy przydzielić pamięć dla nowy element i wskaźniki przekierowujące. O (1)
- na tablicach musisz przenieść tablicę. O (n)
- usuwanie elementu
- na listach po prostu przekierowujesz wskaźniki. O (1).
- na tablicach spędzasz O (n) czas na przeniesienie tablicy, jeśli element do usunięcia nie jest pierwszym lub ostatnim elementem tablicy; w przeciwnym razie możesz po prostu przenieść wskaźnik na początek tablicy lub zmniejszyć długość tablicy
- uzyskanie elementu w znane stanowisko:
- na listach musisz przejść listę Od pierwszego elementu do elementu w określonej pozycji. Najgorszy przypadek: O (n)
- na tablicach można uzyskać natychmiastowy dostęp do elementu. O (1)
Jest to bardzo niskopoziomowe porównanie tych dwóch popularnych i podstawowych struktur danych i widać, że listy działają lepiej w sytuacjach, w których trzeba dokonać wielu modyfikacji samej listy (usunięcie lub dodanie elementów). Z drugiej strony tablice działają lepiej niż listy, gdy trzeba uzyskać bezpośredni dostęp do elementów tablicy.
Z punktu widzenia alokacji pamięci listy są lepsze, ponieważ nie ma potrzeby, aby wszystkie elementy były obok siebie. Z drugiej strony istnieje (mały) narzut przechowywania wskaźników do następnego (lub nawet do poprzedniego) elementu.
Znajomość tych różnic jest dla programistów ważna do wyboru pomiędzy listami i tablicami w ich wdrożenia.
Zauważ, że jest to porównanie list i tablic. Istnieją dobre rozwiązania zgłaszanych tu problemów (np.: Skiplisty, Tablice dynamiczne itp...). W tej odpowiedzi wziąłem pod uwagę podstawową strukturę danych, o której każdy programista powinien wiedzieć.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-12 01:50:35
Lista pojedynczo-linkowana jest dobrym wyborem dla wolnej listy w alokatorze komórek lub puli obiektów:
- potrzebujesz tylko stosu, więc pojedyncza lista jest wystarczająca.
- Wszystko jest już podzielone na węzły. Nie ma narzutu alokacji dla natrętnego węzła listy, pod warunkiem, że komórki są wystarczająco duże, aby zawierały wskaźnik.
- wektor lub deque narzuciłby narzut jednego wskaźnika na blok. Jest to istotne, biorąc pod uwagę, że podczas pierwszego tworzenia sterty, wszystkie komórki są bezpłatne, więc jest to koszt z góry. W najgorszym przypadku podwaja zapotrzebowanie na pamięć na komórkę.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-12 01:08:00
Double-linked list jest dobrym wyborem do zdefiniowania kolejności hashmapy, która również definiuje kolejność elementów (LinkedHashMap w Javie), zwłaszcza gdy jest uporządkowana według ostatniego dostępu:
- Więcej narzutu pamięci niż skojarzony wektor lub deque (2 wskaźniki zamiast 1), ale lepsza wydajność wstawiania/usuwania.
- Brak narzutu alokacji, ponieważ i tak potrzebujesz węzła do wpisu hash.
- Lokalizacja odniesienia nie jest dodatkowym problemem w porównaniu z wektorem lub deque ' em wskaźniki, ponieważ każdy obiekt musiałby być zapisany w pamięci.
Jasne, można dyskutować o tym, czy pamięć podręczna LRU jest dobrym pomysłem, w porównaniu z czymś bardziej wyrafinowanym i przestrajalnym, ale jeśli masz taką, jest to dość przyzwoita implementacja. Nie chcesz wykonywać delete-from-middle-and-add-to-the-end na wektorze lub deque przy każdym dostępie do odczytu, ale przenoszenie węzła na ogon jest zazwyczaj w porządku.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-12 01:08:26
Są przydatne, gdy potrzebujesz szybkiego push, pop i obracać, i nie przeszkadza O (n) indeksowania.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-11 22:36:40
Listy pojedynczo połączone są oczywistą implementacją typu danych common "list"w funkcyjnych językach programowania:
- Dodawanie do głowicy jest szybkie, a
(append (list x) (L))i(append (list y) (L))mogą udostępniać prawie wszystkie swoje dane. Nie ma potrzeby kopiowania przy zapisie w języku bez zapisów. Programiści funkcjonalni wiedzą, jak z tego skorzystać. - Dodawanie do ogona jest niestety powolne, ale tak samo jak każda inna implementacja.
Dla porównania, wektor lub deque byłby zazwyczaj wolno dodawać na obu końcach, wymagając (przynajmniej w moim przykładzie dwóch odrębnych załączników), aby skopiować całą listę (wektor) lub blok indeksu i blok danych, do którego są dołączane (deque). Właściwie, może być coś do powiedzenia tam deque na dużych listach, które trzeba dodać na ogonie z jakiegoś powodu, nie jestem wystarczająco poinformowany o programowaniu funkcyjnym, aby ocenić.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-12 01:28:24
Listy połączone są jednym z naturalnych wyborów, gdy nie możesz kontrolować, gdzie są przechowywane dane, ale nadal musisz jakoś przejść od jednego obiektu do następnego.
Na przykład podczas implementacji śledzenia pamięci w C++ (new/delete replacement) albo potrzebujesz jakiejś struktury danych sterujących, która śledzi, które wskaźniki zostały zwolnione, co w pełni musisz zaimplementować samodzielnie. Alternatywą jest całkowita alokacja i dodanie listy połączonej do początku każdego z danych chunk.
Ponieważ zawsze natychmiast wiesz, gdzie jesteś na liście po wywołaniu delete, możesz łatwo zrezygnować z pamięci w O(1). Również dodanie nowego fragmentu, który właśnie został malloced, znajduje się w O(1). Chodzenie po liście jest bardzo rzadko potrzebne w tym przypadku, więc koszt O(n) nie jest tutaj problemem(chodzenie po strukturze to i tak O (n)).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-11-07 23:28:24
Z mojego doświadczenia wynika, że implementacja rzadkich macierzy i stosów Fibonacciego. Listy połączone dają większą kontrolę nad ogólną strukturą takich struktur danych. Chociaż nie jestem pewien, czy sparse-matrices są najlepiej zaimplementowane za pomocą list linked - prawdopodobnie jest lepszy sposób , ale to naprawdę pomogło poznać ins-and-out sparse matrices za pomocą list linked w undergrad CS:)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-08-04 16:15:48
Jednym z przykładów dobrego wykorzystania listy linkowanej jest sytuacja, w której elementy listy są bardzo duże, tj. wystarczająco duży, że tylko jeden lub dwa mogą zmieścić się w pamięci podręcznej procesora w tym samym czasie. W tym momencie przewaga, jaką mają sąsiadujące kontenery blokowe, takie jak wektory lub tablice iteracji, jest mniej lub bardziej zniwelowana, a przewaga wydajności może być możliwa, jeśli wiele wstawiań i usuwania występuje w czasie rzeczywistym.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-02-23 04:57:57
Rozważ, że lista połączona może być bardzo przydatna w implementacji stylu projektowania opartego na domenie systemu, który zawiera części, które blokują się z powtarzaniem.
Przykładem, który przychodzi mi do głowy, może być modelowanie wiszącego łańcucha. Jeśli chcesz wiedzieć, jakie jest napięcie na danym łączu, Twój interfejs może zawierać getter dla "pozornej" wagi. Których wykonanie zawierałoby link z pytaniem o jego wagę pozorną, a następnie dodanie własną wagę do wyniku. W ten sposób cała długość do dołu będzie oceniana za pomocą jednego wywołania od klienta łańcucha.
Będąc zwolennikiem kodu, który czyta się jak język naturalny, podoba mi się, jak to pozwoli programiście zapytać ogniwo łańcucha, ile waży. Utrzymuje również troskę o obliczanie tych dzieci właściwości w granicach implementacji ogniwa, eliminując potrzebę usługi obliczania masy łańcucha".
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-19 22:22:50
Jednym z najbardziej użytecznych przypadków, jakie znajduję dla list połączonych, pracujących w dziedzinach o krytycznym znaczeniu, takich jak siatka i przetwarzanie obrazów, silniki fizyki i raytracing, jest to, że korzystanie z list połączonych faktycznie poprawia lokalizację odniesienia i zmniejsza alokację sterty, a czasami nawet zmniejsza zużycie pamięci w porównaniu z prostymi alternatywami.
Teraz to może wydawać się kompletnym oksymoronem, że połączone listy mogą to wszystko zrobić, ponieważ są znani z tego, że często robią odwrotnie, ale mają unikalną właściwość w tym, że każdy węzeł listy ma stałe wymagania dotyczące rozmiaru i wyrównania, które możemy wykorzystać, aby umożliwić ich jednoczesne przechowywanie i usuwanie w stałym czasie w sposób, którego rzeczy o zmiennej wielkości nie mogą.
W rezultacie, weźmy przypadek, w którym chcemy zrobić analogiczny odpowiednik przechowywania sekwencji o zmiennej długości, która zawiera milion zagnieżdżonych pod sekwencji o zmiennej długości. Konkretnym przykładem jest indeksowana siatka zawierająca milion wielokątów (niektóre Trójkąty, niektóre czasami wielokąty są usuwane z dowolnego miejsca w siatce, a czasami wielokąty są przebudowywane, aby wstawić wierzchołek do istniejącego wielokąta lub usunąć go. W takim przypadku, jeśli przechowamy milion malutkich std::vectors, wtedy staniemy przed przydzieleniem sterty dla każdego pojedynczego wektora, a także potencjalnie wybuchowym wykorzystaniem pamięci. Milion małych SmallVectors może nie cierpieć tego problemu tak bardzo w zwykłych przypadkach, ale wtedy ich wstępnie przydzielony bufor, który nie jest oddzielnie przydzielone sterty mogą nadal powodować wybuchowe użycie pamięci.
Jeśli zamiast tego zrobimy to:
struct FaceVertex
{
// Points to next vertex in polygon or -1
// if we're at the end of the polygon.
int next;
...
};
struct Polygon
{
// Points to first vertex in polygon.
int first_vertex;
...
};
struct Mesh
{
// Stores all the face vertices for all polygons.
std::vector<FaceVertex> fvs;
// Stores all the polygons.
std::vector<Polygon> polys;
};
... następnie znacznie zmniejszyliśmy liczbę przydziałów sterty i braków w pamięci podręcznej. Zamiast wymagać alokacji sterty i potencjalnie obowiązkowych braków w pamięci podręcznej dla każdego pojedynczego wielokąta, do którego mamy dostęp, wymagamy teraz tylko alokacji sterty, gdy jeden z dwóch wektorów przechowywanych w całej siatce przekracza ich pojemność (koszt zamortyzowany). I chociaż krok, aby przejść z jednego wierzchołka do następnego, może nadal powodować udział braków pamięci podręcznej, nadal jest często mniejszy niż Jeśli każdy pojedynczy wielokąt przechowuje oddzielną tablicę dynamiczną, ponieważ węzły są przechowywane obok siebie i istnieje prawdopodobieństwo, że sąsiedni wierzchołek może być dostępny przed eksmisją(zwłaszcza biorąc pod uwagę, że wiele wielokątów doda swoje wierzchołki na raz, co sprawia, że lwia część wierzchołków wielokątów doskonale przylega).
Oto kolejny przykład:
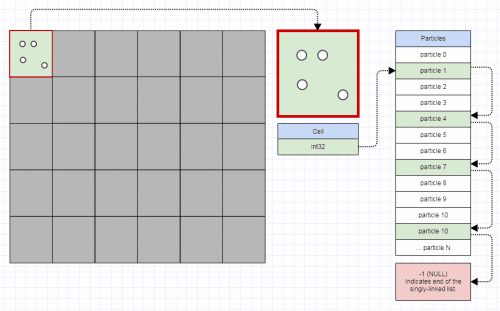
... gdzie komórki siatki są używane do przyspieszania kolizji cząstka-cząstka dla, powiedzmy, 16 miliony cząstek poruszających się w każdej klatce. W tym przykładzie siatki cząstek, używając list połączonych, możemy przenieść cząstkę z jednej komórki siatki do drugiej, zmieniając tylko 3 indeksy. Wymazywanie z wektora i przesuwanie z powrotem do innego może być znacznie droższe i wprowadzić więcej alokacji sterty. Połączone listy zmniejszają również pamięć komórki do 32 bitów. Wektor, w zależności od implementacji, może prealokować swoją tablicę dynamiczną do punktu, w którym może zająć 32 bajty dla pustego wektora. Jeśli mamy około miliona komórek siatki, to spora różnica.
... i to jest miejsce, w którym listy połączone są najbardziej przydatne w dzisiejszych czasach, a szczególnie uważam, że odmiana "indeksowana lista połączona"jest przydatna, ponieważ indeksy 32-bitowe zmniejszają o połowę Wymagania pamięci linków na maszynach 64-bitowych i sugerują, że węzły są przechowywane w tablicy.
Często łączę je również z indeksowanymi darmowymi listami, aby umożliwić ciągłe usuwanie i wstawianie anywhere:

W takim przypadku indeks next wskazuje następny wolny indeks, jeśli węzeł został usunięty, lub następny używany indeks, jeśli węzeł nie został usunięty.
I to jest najlepszy przypadek użycia, który obecnie znajduję dla połączonych list. Jeśli chcemy zapisać, powiedzmy, milion pod sekwencji o zmiennej długości, średnio po 4 elementy (ale czasami z elementami usuwanymi i dodawanymi do jednej z tych pod sekwencji), lista połączona pozwala nam do przechowywania 4 milionów połączonych węzłów listy w sposób ciągły zamiast 1 miliona kontenerów, z których każdy jest indywidualnie alokowany: jeden olbrzymi wektor, tzn. nie milion małych.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-01-09 07:29:10
Używałem list połączonych (nawet podwójnie połączonych) w przeszłości w aplikacji C / C++. To było przed. NET, a nawet stl.
Prawdopodobnie nie użyłbym teraz listy linkowanej w języku. NET, ponieważ cały kod, którego potrzebujesz, jest dostarczany za pomocą metod rozszerzenia Linq.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-11 22:36:04
Istnieją dwie komplementarne operacje, które są trywialnie o (1) na listach i bardzo trudne do zaimplementowania w O(1) w innych strukturach danych - usunięcie i wstawienie elementu z dowolnej pozycji, zakładając, że trzeba zachować kolejność elementów.
Mapy Hashowe mogą oczywiście wstawiać i usuwać w O(1), ale wtedy nie można iteracji nad elementami w kolejności.
Biorąc pod uwagę powyższy fakt, mapę hashową można połączyć z połączoną listą, aby utworzyć sprytny bufor LRU: mapę, która przechowuje stałą liczbę par klucz-wartość i upuszcza najmniej Ostatnio dostępny klucz, aby zrobić miejsce dla nowych.
Wpisy na mapie hash muszą mieć wskaźniki do połączonych węzłów listy. Podczas uzyskiwania dostępu do mapy skrótu węzeł listy połączonej jest odłączany od bieżącej pozycji i przenoszony na początek listy(o (1), yay dla list połączonych!). Gdy zachodzi potrzeba usunięcia ostatnio używanego elementu, ten z ogona listy musi zostać upuszczony (ponownie o(1) zakładając, że zachowasz wskaźnik do węzła ogonowego) wraz z powiązanym wpisem mapy hash (więc konieczne są Linki zwrotne z listy do mapy hash.)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-11-11 08:08:13