Jaka jest różnica między kompilacją a interpretacją?
Właśnie rozmawiałem z kolegą i gdzie rozmawialiśmy o silniku JavaScript V8. Według Wikipedii,
V8 kompiluje JavaScript do natywnego kodu maszynowego [...] przed wykonaniem go, zamiast bardziej tradycyjnych technik, takich jak interpretacja kodu bajtowego lub kompilacja całego programu do kodu maszynowego i wykonanie go z systemu plików.
Where (popraw mnie jeśli się mylę) " interpretowanie kodu bajtowego " jest sposobem działania Javy, a "kompilowanie całego programu " miałoby zastosowanie do języków takich jak C lub c++. Teraz zastanawialiśmy się, debatowaliśmy i stawialiśmy fałszywe twierdzenia i przypuszczenia o różnicach, podobieństwach. Aby to zakończyć, zaleciłem zapytać ekspertów w tej sprawie.
Więc, kto jest w stanie
-
Jest to metoda, która pozwala na określenie, wyjaśnienie i/lub odwołanie się do wszystkich głównych metod (np. precompilowanie a interpretacja środowiska uruchomieniowego)
- do wizualizacji lub dostarczenia schematu o relacjach między źródłami, kompilacją i interpretacja
- podaj przykłady (nazwy języków programowania) dla głównych metod #1.
Uwagi:
- nie szukam długiego prozaicznego eseju o różnych paradygmatach, ale wizualnie wspieranego, szybkiego przeglądu.
- wiem, że Stackoverflow nie ma być encyklopedią dla programistów (ale raczej platformą pytań i Odpowiedzi dla bardziej szczegółowych pytań). Ale ponieważ mogę znaleźć wiele popularnych pytań, tego rodzaju zapewniają encyklopedyczne spojrzenie na niektóre tematy (np. [1], [2], [3], [4], [5]), zacząłem to pytanie.
- jeśli to pytanie woli pasować do jakiejkolwiek innej strony StackExchange (np. cstheory ), daj mi znać lub oznacz to pytanie do moderacji.
2 answers
Jest prawie niemożliwe, aby odpowiedzieć na twoje pytanie z jednego prostego powodu: nie ma kilku podejść, są one raczej kontinuum. Rzeczywisty kod związany z tym kontinuum jest również dość identyczny, jedyną różnicą jest to, kiedy coś się dzieje i czy pośrednie kroki są zapisywane w jakiś sposób, czy nie. Różne punkty w tym kontinuum (które nie jest pojedynczą linią, progresją, ale raczej prostokątem z różnymi narożnikami, do których można być blisko) są:
- odczyt Źródło kod
- zrozumienie kodu
- wykonując to, co zrozumiałeś Buforowanie różnych pośrednich danych wzdłuż drogi, a nawet uporczywe zapisywanie ich na dysku.
Na przykład, czysto zinterpretowany język programowania praktycznie nie działa w #4, A #2 występuje w domyśle między 1 A 3, więc prawie go nie zauważysz. Po prostu czyta fragmenty kodu i natychmiast na nie reaguje. Oznacza to, że tam jest niski narzut do faktycznego rozpoczęcia wykonywania, ale np. w pętli te same linie tekstu są odczytywane i ponownie odczytywane.
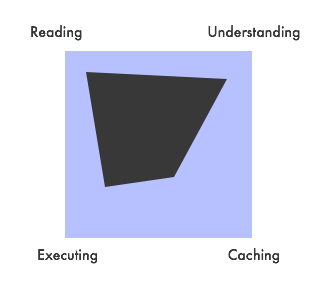
W innym rogu prostokąta znajdują się tradycyjnie skompilowane języki, w których zazwyczaj punkt # 4 polega na trwałym zapisaniu rzeczywistego kodu maszynowego do pliku, który można następnie uruchomić w późniejszym czasie. Oznacza to, że na początku czekasz stosunkowo długo, aż cały program zostanie przetłumaczony (nawet jeśli wywołujesz tylko pojedyncza funkcja w nim), ale pętle OTOH są szybsze, ponieważ źródło nie musi być ponownie odczytywane.
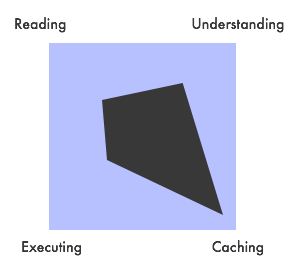
I są rzeczy pomiędzy, np. maszyna wirtualna: dla przenośności, wiele języków programowania nie kompiluje się do rzeczywistego kodu maszynowego, ale do kodu bajtowego. Istnieje kompilator, który generuje kod bajtowy, oraz interpreter, który pobiera ten kod bajtowy i faktycznie go uruchamia (skutecznie "zamieniając go w kod maszynowy"). Chociaż jest to ogólnie wolniej niż kompilowanie i przechodzenie bezpośrednio do kodu maszynowego, łatwiej jest portować taki język na inną platformę, ponieważ wystarczy portować interpreter kodu bajtowego, który jest często napisany w języku wysokiego poziomu, co oznacza, że możesz użyć istniejącego kompilatora do tego "skutecznego tłumaczenia na kod maszynowy" i nie musisz tworzyć i utrzymywać zaplecza dla każdej platformy, na której chcesz uruchomić. Ponadto, to Może być szybsze, jeśli można wykonać kompilację do kodu bajtowego raz, a następnie tylko rozpowszechniaj skompilowany kod bajtowy, aby inni ludzie nie musieli poświęcać cykli procesora na np. uruchamianie optymalizatora nad kodem i płacić tylko za tłumaczenie kodu bajtowego na natywny, które może być nieistotne w Twoim przypadku użycia. Poza tym, nie rozdajesz kodu źródłowego.
Inną rzeczą pomiędzy byłby Just-In-Time kompilator (JIT), który jest w rzeczywistości interpreterem, który przechowuje kod, który został uruchomiony raz, w formie skompilowanej. To "trzymanie się" czyni go wolniejszym niż czysty interpreter (np. dodany narzut i użycie pamięci RAM prowadzące do zamiany i dostępu do dysku), ale sprawia, że jest szybszy podczas wielokrotnego wykonywania fragmentu kodu. Może być również szybszy niż czysty kompilator kodu, gdzie np. tylko jedna funkcja jest wielokrotnie wywoływana, ponieważ nie marnuje czasu na kompilowanie reszty programu, jeśli nie jest używana.
I wreszcie, można znaleźć inne spoty na tym prostokącie np. nie zapisując skompilowanego kodu na stałe, ale usuwając skompilowany kod z pamięci podręcznej jeszcze raz. W ten sposób można np. zaoszczędzić miejsce na dysku lub pamięć RAM na systemach wbudowanych, kosztem być może konieczności skompilowania rzadko używanego fragmentu kodu po raz drugi. Wiele kompilatorów JIT tak robi.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-07-08 14:38:19
Wiele środowisk wykonawczych używa obecnie kodu bajtowego (lub czegoś podobnego) jako pośredniej reprezentacji kodu. Tak więc kod źródłowy jest najpierw skompilowany do języka pośredniego, który następnie jest interpretowany przez maszynę Wirtualną (która dekoduje zestaw instrukcji bajtowych) lub jest skompilowany dalej do kodu maszynowego i wykonywany przez sprzęt.
Istnieje bardzo niewiele języków produkcyjnych, które są interpretowane Bez bycia prekompilowany w jakąś formę pośrednią. Jednak łatwo jest konceptualizować taki interpreter: wystarczy pomyśleć o hierarchii klas z podklasami dla każdego rodzaju elementu języka (if statement, for, itd.), a każda klasa ma metodę Evaluate, która ocenia dany węzeł. Jest to również powszechnie znane jako interpreter design pattern .
Jako przykład rozważ następujący fragment kodu implementujący if oświadczenie w hipotetycznym interpreterze (zaimplementowanym w C#):
class IfStatement : AstNode {
private readonly AstNode condition, truePart, falsePart;
public IfStatement(AstNode condition, AstNode truePart, AstNode falsePart) {
this.condition = condition;
this.truePart = truePart;
this.falsePart = falsePart;
}
public override Value Evaluate(EvaluationContext context) {
bool yes = condition.Evaluate(context).IsTrue();
if (yes)
truePart.Evaluate(context);
else
falsePart.Evaluate(context);
return Value.None; // `if` statements have no value.
}
}
Jest to bardzo prosty, ale w pełni funkcjonalny interpreter.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-06-24 08:33:18