Jaka jest relacja między pracownikami, instancjami pracowniczymi i wykonawcami?
W trybie Spark Standalone istnieją węzły master i worker.
Oto kilka pytań:
- czy 2 instancje robocze oznaczają jeden węzeł roboczy z 2 procesami roboczymi?
- czy każda instancja worker posiada executor dla określonej aplikacji (która zarządza pamięcią masową, zadaniem) czy jeden węzeł worker posiada jeden executor?
- czy istnieje schemat blokowy wyjaśniający, w jaki sposób Spark runtime, taki jak liczba słów?
4 answers
Proponuję najpierw przeczytać Spark cluster docs, ale jeszcze bardziej ten Cloudera blog post wyjaśniający te tryby.
Twoje pierwsze pytanie zależy od tego, co rozumiesz przez 'instancje'. Węzeł jest maszyną i nie ma dobrego powodu, aby uruchamiać więcej niż jednego pracownika na maszynę. Więc dwa węzły robocze zazwyczaj oznaczają dwie maszyny, z których każda jest robotnikiem Spark.
Pracownicy posiadają wiele executorów, dla wielu zastosowań. Jedna aplikacja posiada executory na wielu pracowników.
Twoje trzecie pytanie nie jest jasne.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-07-11 13:53:36
Wiem, że to stare pytanie, a odpowiedź Seana była doskonała. Mój writeup jest o SPARK_WORKER_INSTANCES w komentarzu MrQuestion. Jeśli używasz Mesos lub YARN jako Menedżera klastra, możesz uruchomić wiele wykonawców na tej samej maszynie z jednym pracownikiem, więc naprawdę nie ma potrzeby uruchamiania wielu pracowników na maszynę. Jeśli jednak używasz samodzielnego menedżera klastrów, obecnie nadal zezwala on tylko na jeden wykonawca na każdy proces roboczy na każdej fizycznej maszynie. Tak więc w przypadku masz super dużą maszynę i chciałbyś uruchomić na niej wiele exectuorów, musisz uruchomić więcej niż 1 proces roboczy. To właśnie SPARK_WORKER_INSTANCES w spark-env.sh jest dla. Domyślną wartością jest 1. Jeśli używasz tego ustawienia, upewnij się, że ustawiłeś SPARK_WORKER_CORES jawnie, aby ograniczyć rdzenie na worker, w przeciwnym razie każdy worker spróbuje użyć wszystkich rdzeni.
To samodzielne ograniczenie menedżera klastrów powinno wkrótce zniknąć. Zgodnie z tym Spark-1706, ten problem zostanie naprawiony i wydany w wersji Spark 1.4.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-04-21 18:22:06
Rozszerzając o inne świetne odpowiedzi, chciałbym opisać kilkoma obrazkami.
W trybie samodzielnym Spark są węzły master i worker.
Jeśli reprezentujemy zarówno master jak i workers w jednym miejscu dla trybu samodzielnego.
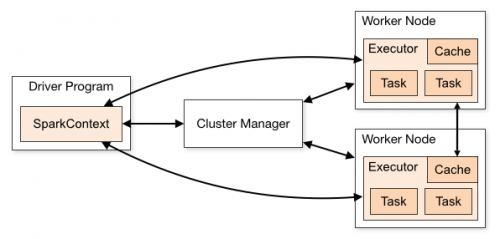
Jeśli jesteś ciekaw, jak Spark działa z włóczką? sprawdź ten post Spark on YARN
1. Czy 2 instancje worker oznaczają jeden węzeł worker z 2 worker procesy?
W ogólności nazywamy instancję workera jako slave, ponieważ jest to proces do wykonywania zadań/zadań spark . Na przykład, w przypadku mapowania dla węzła(maszyny fizycznej lub wirtualnej) i workera jest to,
1 Node = 1 Worker process
2. Czy każda instancja worker posiada executor dla określonej aplikacji (która zarządza pamięcią masową, zadaniem) czy jeden węzeł worker posiada jeden executor?
Tak, węzeł worker może posiadać wiele executorów (procesy) , jeśli posiada wystarczającą ilość procesora, pamięci i pamięci masowej .
Sprawdź węzeł roboczy na danym obrazku.
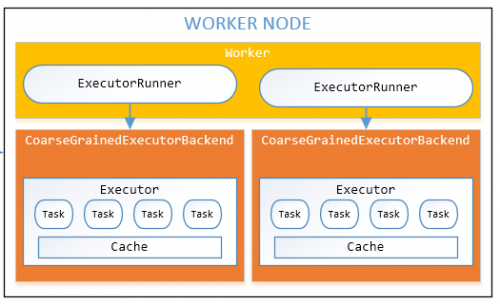
BTW, Liczba executorów w węźle workera w danym momenciejest całkowicie zależna od obciążenia pracą klastrai zdolności węzła do uruchomienia ilu executorów.
3. Czy istnieje schemat blokowy wyjaśniający, w jaki sposób Spark runtime?
Jeśli spojrzymy na wykonanie z Spark perspective nad dowolnym menedżerem zasobów dla programu, który join Dwa rdd s i wykonuje jakąś reduce operację następnie filter

HIH
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-03-21 06:37:27
Jak mówił Lan, użycie wielu instancji roboczych ma znaczenie tylko w trybie autonomicznym. Istnieją dwa powody, dla których chcesz mieć wiele instancji: (1) zbieracz pauz może zaszkodzić przepustowości dla dużych JVMs (2) sterta o rozmiarze >32 GB nie może używać CompressedOoops
Dowiedz się więcej o Jak skonfigurować wiele instancji workera .
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-06-05 08:47:15