Lista Big-O dla funkcji PHP
Po używaniu PHP przez jakiś czas, zauważyłem, że nie wszystkie funkcje wbudowane w PHP są tak szybkie, jak oczekiwano. Rozważ poniższe dwie możliwe implementacje funkcji, która znajduje, czy liczba jest liczbą pierwszą, używając buforowanej tablicy liczb pierwszych.
//very slow for large $prime_array
$prime_array = array( 2, 3, 5, 7, 11, 13, .... 104729, ... );
$result_array = array();
foreach( $prime_array => $number ) {
$result_array[$number] = in_array( $number, $large_prime_array );
}
//speed is much less dependent on size of $prime_array, and runs much faster.
$prime_array => array( 2 => NULL, 3 => NULL, 5 => NULL, 7 => NULL,
11 => NULL, 13 => NULL, .... 104729 => NULL, ... );
foreach( $prime_array => $number ) {
$result_array[$number] = array_key_exists( $number, $large_prime_array );
}
Dzieje się tak dlatego, że in_array jest zaimplementowany za pomocą wyszukiwania liniowego O (n), które będzie liniowo zwalniać w miarę wzrostu $prime_array. Gdzie funkcja array_key_exists jest zaimplementowana z funkcją wyszukiwania hash O (1), która nie zwalnia tempa, chyba że tabela hash zostanie ekstremalnie wypełniony (w takim przypadku jest to tylko O (n)).
Do tej pory musiałem odkryć big-O ' S metodą prób i błędów, a czasami patrząc na kod źródłowy . Teraz pytanie...
Czy istnieje lista teoretycznych (lub praktycznych) wielkich czasów dla wszystkich * wbudowanych funkcji PHP?
* a przynajmniej te ciekawe
Na przykład bardzo trudno jest przewidzieć, jakie Duże O z wymienionych funkcji, ponieważ możliwa implementacja zależy od nieznane podstawowe struktury danych PHP: array_merge, array_merge_recursive, array_reverse, array_intersect, array_combine, str_replace (z wejściami tablicy), itd.
4 answers
Ponieważ wydaje się, że nikt nie robił tego wcześniej, pomyślałem, że dobrze byłoby mieć to gdzieś w celach informacyjnych. Poszedłem jednak i albo poprzez benchmark, albo code-skimming, aby scharakteryzować funkcje array_*. Próbowałem umieścić bardziej interesujący Big-O blisko góry. Ta lista nie jest kompletna.
Uwaga: Wszystkie Duże-o, gdzie obliczane przy założeniu, że szukanie hash jest O(1), nawet jeśli jest naprawdę O (n). Współczynnik n jest tak niski, że napowietrzność pamięci RAM jest wystarczająco duża array zaszkodziłoby, zanim właściwości wyszukiwania Big-O zaczną działać. Na przykład różnica między wywołaniem {[2] } przy N=1 i n = 1,000,000 wynosi ~50% wzrost czasu.
Ciekawe Punkty :
-
isset/array_key_existsjest znacznie szybszy niżin_arrayiarray_search -
+(union) jest nieco szybszy niżarray_merge(i wygląda ładniej). Ale to działa inaczej, więc miej to na uwadze. -
shufflejest na tym samym poziomie Big-O coarray_rand -
array_pop/array_pushjest szybszy niżarray_shift/array_unshiftze względu na karę ponownego indeksowania
Lookups :
array_key_exists O (n), ale naprawdę blisko O(1) - wynika to z liniowego sondowania w kolizjach, ale ponieważ szansa na kolizje jest bardzo mała, współczynnik jest również bardzo mały. Uważam, że traktujesz szukanie hash jako O (1), aby dać bardziej realistyczne big-O. na przykład różnica między N=1000 i N=100000 jest tylko o 50% spowolniona.
isset( $array[$index] ) O (n) ale bardzo blisko O(1) - używa tego samego wyszukiwania co array_key_exists. Ponieważ jest to konstrukcja językowa, będzie buforować wyszukiwanie, jeśli klucz jest zakodowany na twardo, co spowoduje przyspieszenie w przypadkach, gdy ten sam klucz jest używany wielokrotnie.
in_array O (n) - dzieje się tak dlatego, że dokonuje przeszukiwania liniowego tablicy, dopóki nie znajdzie wartości.
array_search O ( n) - używa tej samej podstawowej funkcji co in_array, ale zwraca wartość.
Funkcje kolejki :
array_push O (var var_i, dla wszystkich i)
array_pop O (1)
array_shift O (n) - musi reindeksować wszystkie klucze
array_unshift O (n + var var_i, for all i) - musi reindexować wszystkie klucze
Array Intersection, Union, Subtraction :
array_intersect_key jeśli przecięcie 100% do O(Max(param_i_size)*param param_i_count, dla wszystkich i), jeśli przecięcie 0% intersect O (∑param_i_size, dla wszystkich i)
array_intersect if przecięcie 100% do O(n^2*∑param_i_count, for all I), if przecięcie 0% intersect O (n^2)
array_intersect_assoc jeśli przecięcie 100% do O(Max(param_i_size)*param param_i_count, dla wszystkich i), jeśli przecięcie 0% intersect O (∑param_i_size, dla wszystkich i)
array_diff o (π param_i_size, dla wszystkich i) - to iloczyn wszystkich param_sizes
array_diff_key O (∑param_i_size, for i != 1) - dzieje się tak dlatego, że nie musimy iteracji nad pierwszą tablicą.
array_merge O (arra array_i, i != 1) - nie wymaga iteracji nad pierwszą tablicą
+ (union) O (n), gdzie n jest wielkością array_first + array_second) - mniej narzutu niż array_merge, ponieważ nie musi zmieniać numeracji
array_replace O (arra array_i, for all I)
Losowe:
shuffle O (n)
array_rand O (n) - wymaga liniowej ankiety.
:
array_fill O (n)
array_fill_keys O (n)
range O (n)
array_splice O (offset + Długość)
array_slice O (offset + długość) lub O (n) jeżeli długość = NULL
array_keys O (n)
array_values O (n)
array_reverse O (n)
array_pad o (pad_size)
array_flip O (n)
array_sum O (n)
array_product O (n)
array_reduce O (n)
array_filter O (n)
array_map O (n)
array_chunk O (n)
array_combine O (n)
Chciałbym podziękować Eureqa za ułatwienie znalezienia Big-O funkcji. Jest to niesamowity darmowy program, który może znaleźć najlepsze dopasowanie funkcja dla dowolnych danych.
EDIT:
Dla tych, którzy wątpią, że PHP array lookups są O(N), napisałem benchmark, aby to przetestować(nadal są one skutecznie O(1) dla najbardziej realistycznych wartości).
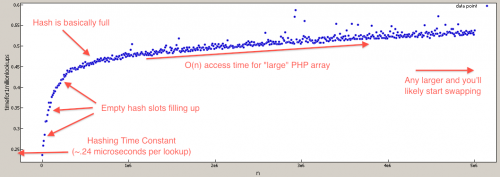
$tests = 1000000;
$max = 5000001;
for( $i = 1; $i <= $max; $i += 10000 ) {
//create lookup array
$array = array_fill( 0, $i, NULL );
//build test indexes
$test_indexes = array();
for( $j = 0; $j < $tests; $j++ ) {
$test_indexes[] = rand( 0, $i-1 );
}
//benchmark array lookups
$start = microtime( TRUE );
foreach( $test_indexes as $test_index ) {
$value = $array[ $test_index ];
unset( $value );
}
$stop = microtime( TRUE );
unset( $array, $test_indexes, $test_index );
printf( "%d,%1.15f\n", $i, $stop - $start ); //time per 1mil lookups
unset( $stop, $start );
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-06-01 03:33:18
Prawie zawsze chcesz używać isset zamiast array_key_exists. Nie patrzę na wewnętrzne, ale jestem prawie pewien, że array_key_exists Jest O (N), ponieważ iterauje się nad każdym kluczem tablicy, podczas gdy isset próbuje uzyskać dostęp do elementu za pomocą tego samego algorytmu skrótu, który jest używany podczas dostępu do indeksu tablicy. To powinno być O (1).
Jeden "mam cię" do pilnowania jest to:
$search_array = array('first' => null, 'second' => 4);
// returns false
isset($search_array['first']);
// returns true
array_key_exists('first', $search_array);
Byłem ciekawy, więc porównałem różnicę:
<?php
$bigArray = range(1,100000);
$iterations = 1000000;
$start = microtime(true);
while ($iterations--)
{
isset($bigArray[50000]);
}
echo 'is_set:', microtime(true) - $start, ' seconds', '<br>';
$iterations = 1000000;
$start = microtime(true);
while ($iterations--)
{
array_key_exists(50000, $bigArray);
}
echo 'array_key_exists:', microtime(true) - $start, ' seconds';
?>
is_set: 0.132308959961 sekundyarray_key_exists: 2.33202195168 sekund
Oczywiście, to nie pokazuje złożoności czasu, ale pokazuje, jak dwie funkcje porównują się ze sobą.
Aby sprawdzić złożoność czasową, porównaj czas potrzebny na uruchomienie jednej z tych funkcji na pierwszym i ostatnim kluczu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-20 05:23:54
Wyjaśnieniem opisanego przypadku jest to, że tablice asocjacyjne są zaimplementowane jako tabele hashowe - więc wyszukiwanie według klucza (i odpowiednio array_key_exists) jest O(1). Jednak tablice nie są indeksowane według wartości, więc jedynym sposobem w ogólnym przypadku, aby dowiedzieć się, czy wartość istnieje w tablicy, jest wyszukiwanie liniowe. Nic dziwnego.
Nie wydaje mi się, aby istniała szczegółowa dokumentacja złożoności algorytmicznej metod PHP. Jednak, jeśli jest wystarczająco duży aby zagwarantować ten wysiłek, zawsze możesz przejrzeć kod źródłowy .
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-18 23:17:57
Gdyby ludzie mieli problemy w praktyce z kolizjami kluczy, zaimplementowaliby kontenery z wtórnym wyszukiwaniem hashów lub zrównoważonym drzewem. Zbalansowane drzewo daje o (log n) najgorszy przypadek zachowania i o (1) avg. case (sam hash). Napowietrzność nie jest tego warta w najbardziej praktycznych zastosowaniach pamięci, ale być może istnieją bazy danych, które implementują tę formę strategii mieszanej jako domyślny przypadek.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-18 21:38:46