Pomiń listę a binarne drzewo wyszukiwania
Ostatnio natknąłem się na strukturę danych znaną jako pomiń listę. Wydaje się, że ma bardzo podobne zachowanie do binarnego drzewa wyszukiwania.
Dlaczego w ogóle chcesz używać listy przeskoków nad binarnym drzewem wyszukiwania?
7 answers
Listy przeskoków są bardziej podatne na jednoczesny dostęp/modyfikację. Herb Sutter napisał Artykuł o strukturze danych w środowiskach współbieżnych. Ma więcej szczegółowych informacji.
Najczęściej używaną implementacją binarnego drzewa wyszukiwania jest czerwono-czarne drzewo . Współbieżne problemy pojawiają się, gdy drzewo jest modyfikowane, często musi się równoważyć. Operacja równoważenia może mieć wpływ na duże części drzewa, co wymagałoby blokady mutex na wielu węzły drzew. Wstawianie węzła do listy pominięć jest znacznie bardziej zlokalizowane, tylko węzły bezpośrednio połączone z danym węzłem muszą być zablokowane.
Aktualizacja od Jon Harrops Komentarze
Czytałem najnowszą pracę Frasera i Harrisa Programowanie współbieżne bez blokad . Naprawdę dobre rzeczy, jeśli jesteś zainteresowany strukturami danych bez blokad. W artykule skupiono się na pamięci transakcyjnej i teoretycznej operacji Multiword-compare-and-swap MCA. Oba są symulowane w oprogramowaniu, ponieważ żaden sprzęt nie obsługuje ich jeszcze. Jestem pod wrażeniem, że w ogóle byli w stanie zbudować MCA w oprogramowaniu.
Nie uważam, że pamięć transakcyjna jest szczególnie interesująca, ponieważ wymaga garbage collector. Również pamięć transakcyjna oprogramowania {[2] } jest nękana problemami z wydajnością. Byłbym jednak bardzo podekscytowany, gdyby pamięć transakcyjna sprzętowa kiedykolwiek stała się powszechna. W końcu to nadal badania i nie będzie używany do kodu produkcyjnego dla innego około dekady.
W sekcji 8.2 porównują wydajność kilku współbieżnych implementacji drzewa. Podsumuję ich wnioski. Warto pobrać pdf, ponieważ ma kilka bardzo pouczających wykresów na stronach 50, 53 i 54.
- blokowanie list przeskoków jest szalenie szybkie. Skalują się niesamowicie dobrze wraz z liczbą jednoczesnych dostępów. To sprawia, że listy skip są specjalne, inne struktury danych oparte na blokadach mają tendencję do wykrzywiania się pod ciśnienie.
- listy przeskoków bez blokady są konsekwentnie szybsze niż listy przeskoków bez blokady, ale tylko w niewielkim stopniu.
- listy przeskoków transakcyjnych są konsekwentnie 2-3 razy wolniejsze niż wersje blokujące i nieblokujące.
- blokowanie Czerwono-Czarnych drzew krakanie pod współbieżnym dostępem. Ich wydajność pogarsza się liniowo z każdym nowym użytkownikiem współbieżnym. Z dwóch znanych implementacji drzewa blokującego czerwono-czarne, jedna zasadniczo ma blokadę globalną podczas równoważenie drzew. Drugi używa fantazyjnego (i skomplikowanego) eskalacji blokady, ale nadal nie wykonuje znacząco wersji global lock.
- wolne od blokad czerwono-czarne drzewa nie istnieją(już nie są prawdziwe, zobacz Update).
- drzewa transakcyjne czerwono-czarne są porównywalne z Transakcyjnymi listami przeskoków. To było bardzo zaskakujące i obiecujące. Pamięć transakcyjna, choć wolniejsza, jeśli o wiele łatwiejsza do zapisania. Może to być tak proste, jak szybkie wyszukiwanie i wymiana na wersja nie współbieżna.
Update
Oto artykuł o drzewach wolnych od blokad: czerwono-czarne drzewa wolne od blokad przy użyciu CAS.
Nie przyjrzałem się temu głęboko, ale na powierzchni wydaje się solidny.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-06-13 07:02:38
Po pierwsze, nie można uczciwie porównać randomizowanej struktury danych z taką, która daje najgorszą gwarancję.
Lista przeskoków jest odpowiednikiem losowo zbalansowanego binarnego drzewa wyszukiwania (RBST) w sposób bardziej szczegółowo wyjaśniony w dziele Deana i Jonesa"Exploring the Duality Between przeskoków Lists and Binary search Trees".Na odwrót, można również mieć deterministyczne listy pominięć, które gwarantują najgorszą wydajność, por. Munro et al.
W przeciwieństwie do tego, co niektórzy twierdzą powyżej, możesz mieć implementacje binarnych drzew wyszukiwania (BST), które dobrze sprawdzają się w programowaniu współbieżnym. Potencjalnym problemem z BST skupionymi na współbieżności jest to, że nie można łatwo uzyskać takich samych gwarancji dotyczących równoważenia, jak z drzewa czerwono-czarnego (RB). (Ale "standardowe", tzn. losowe, listy przeskoków też nie dają tych gwarancji.) Istnieje kompromis między utrzymaniem równowagi przez cały czas a dobrym (i łatwym do zaprogramowania) współbieżny dostęp, więc relaxed drzewa RB są zwykle używane, gdy pożądana jest dobra współbieżność. Relaksacja polega na tym, że nie od razu równoważymy drzewo. Aby zapoznać się z nieco datowaną (1998) ankietą zobacz Hanke ' a "wydajność równoległych algorytmów drzewa Czerwono-czarnego" [ps.gz] .
Jedną z nowszych ulepszeń na nich jest tak zwane drzewo chromatyczne (zasadniczo masz taką wagę, że czarny będzie 1, A Czerwony będzie zero, ale możesz również pozwolić wartości pomiędzy). A jak drzewo chromatyczne radzi sobie z listą przeskoków? Zobaczmy, co Brown et al. "Ogólna Technika nieblokujących drzew" (2014) musi powiedzieć:
Mając 128 wątków, nasz algorytm przewyższa nieblokującą listę skiplistów Javy o 13% do 156%, oparte na blokadzie drzewo AVL Bronson et al. od 63% do 224%, a RBT, który używa pamięci transakcyjnej oprogramowania (STM) od 13 do 134 razy
EDIT to add: Pugh ' s lock-based skip list, which was benchmarked w Fraser and Harris (2007) "Programowanie współbieżne bez blokady" jako Zbliżające się do ich własnej wersji bez blokady (punkt obficie podkreślony w górnej odpowiedzi tutaj), jest również poprawiony dla dobrej pracy współbieżnej, por. Pugh 's " równoczesne utrzymanie list przeskoków " , choć w dość łagodny sposób. Niemniej jednak jeden nowszy / 2009 papier "prosty optymistyczny algorytm pominięcia listy" Przez Herlihy et al., który proponuje rzekomo prostszy (niż implementacja współbieżnych list przeskoków, krytykowana przez Pugh za brak dostatecznie przekonującego dla nich dowodu poprawności. Pomijając ten (może zbyt pedantyczny) qualm, Herlihy et al. pokazuje, że ich prostsza implementacja listy przeskoków oparta na blokadach faktycznie nie jest skalowana, podobnie jak implementacja JDK wolna od blokad, ale tylko w przypadku dużych kontrowersji (50% wstawia, 50% usuwa i 0% wyszukuje)... których Fraser i Harris w ogóle nie testowali; Fraser i Harris testowali tylko 75% odsłon, 12,5% wstawia i usuwa 12,5% (na liście pominięć z ~500K elementów). Prostsze wdrożenie Herlihy et al. również zbliża się do rozwiązania lock-free z JDK w przypadku niskiego twierdzenia, że testowali( 70% lookups, 20% wstawia, 10% usuwa); oni rzeczywiście pokonać rozwiązanie lock-free dla tego scenariusza, gdy zrobili ich lista przeskoków wystarczająco duży, tj. przechodząc od 200k do 2m elementów, tak, że prawdopodobieństwo niezgody na dowolnym zamku stał się znikomy. Byłoby miło, gdyby Herlihy et al. przebolały ich problemy z dowodem Pugha i przetestowały jego implementację, ale niestety tego nie zrobili.
EDIT2: znalazłem (opublikowany 2015) motherlode wszystkich benchmarków: Gramoli ' s "więcej niż kiedykolwiek chciałeś wiedzieć o synchronizacji. Synchrobench, mierzenie wpływu synchronizacji na algorytmy współbieżne " : oto fragment obrazu istotny dla tego pytania.
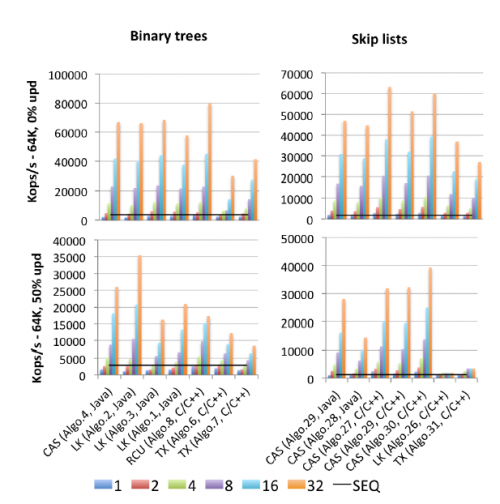
"Algo.4 " jest prekursorem (wersja starsza, 2011) Brown et al./ align = "left" / (Nie wiem, o ile lepsza lub gorsza jest wersja 2014). "Algo.26" to wspomniany wyżej Herlihy; jak widać na UPDATE ' ach robi się tandetnie, a znacznie gorzej na procesorach Intela używanych tutaj niż na procesorach Sun z oryginalnego papieru. "Algo.28 " jest ConcurrentSkipListMap z JDK; nie działa tak dobrze, jak można było się spodziewać w porównaniu z innymi implementacjami list przeskoków opartych na CAS. Laureatami konkursu są "Algo.2 " algorytm oparty na blokadzie (!!) opisane przez Crain i in. w "A Contention-Friendly Binary Search Tree" i " Algo.30 " to "obrotowa lista skiplist" z " logarytmiczne struktury danych dla multicores " . "Algo.29"jest " brak hot spot non-blocking skip lista " . Należy pamiętać, że Gramoli jest współautorem wszystkich trzech prac z algorytmami zwycięzców. "Algo.27 " jest implementacją C++ z listy przeskoków.
Wniosek Gramoli jest taki, że o wiele łatwiej spieprzyć implementację drzewa współbieżnego opartą na CAS niż jest to, aby spieprzyć podobną listę przeskoków. I na podstawie danych, trudno się nie zgodzić. Jego wyjaśnienie dla tego faktu jest następujące:
Trudność w zaprojektowaniu drzewa, które jest wolne od blokady wynika z trudność modyfikacji wielu odwołań atomicznie. Pomiń listy składają się z wież połączonych ze sobą za pomocą wskaźników następczych i w którym każdy węzeł wskazuje na węzeł bezpośrednio pod nim. Są to często uważane za podobne do drzew, ponieważ każdy węzeł ma następcę w wieży następcy i pod nią, jednak główną różnicą jest że wskaźnik w dół jest na ogół niezmienny, stąd uproszczenie atomowa modyfikacja węzła. Rozróżnienie to jest prawdopodobnie powód, dla którego pomiń listy przewyższają drzewa pod dużym jak widać na rysunku [powyżej].
Przezwyciężenie tej trudności było kluczowym problemem w Brown et al.ostatnie prace. Mają cały oddzielny (2013) papier " pragmatyczne prymitywy dla nieblokujących danych Struktury " na budowaniu wielokanałowych związków LL/SC "prymitywów", które nazywają LLX/SCX, sami zaimplementowali przy użyciu (na poziomie maszynowym) CAS. Brown i in. w 2014 r. (ale nie w 2011 r.) użyto tego bloku konstrukcyjnego LLX/SCX.
Myślę, że być może warto tutaj również podsumować podstawowe idee z "no hot spot"/contention-friendly (CF) lista przeskoków. Uzupełnia istotną ideę relaksujących drzew RB (i podobnych struktury danych): wieże nie są już budowane natychmiast po włożeniu, ale opóźnione, dopóki nie będzie mniej sporów. I odwrotnie, usunięcie wysokiej wieży może wywołać wiele sporów; zauważono to już w artykule Pugh z 1990 roku, dlatego Pugh wprowadził odwrócenie wskaźnika przy usuwaniu (ciekawostka, o której Strona Wikipedii na listach przeskoków nadal nie wspomina, niestety). Lista przeskoków CF idzie o krok dalej i opóźnia usuwanie górnych poziomów wysoka wieża. Oba rodzaje opóźnionych operacji w listach przeskoków CF są wykonywane przez (oparty na CAS) osobny wątek przypominający garbage-collector, który jego autorzy nazywają "adaptującym wątkiem".
Kod Synchrobench (w tym wszystkie przetestowane algorytmy) jest dostępny pod adresem: https://github.com/gramoli/synchrobench . Najnowszy Brown i in. implementacja (nieuwzględniona w powyższym) jest dostępna pod adresem http://www.cs.toronto.edu / ~tabrown/chromatic/ConcurrentChromaticTreeMap.java robi czy ktoś ma dostępną maszynę 32 + core? J / K chodzi mi o to, że możecie sami to zrobić.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-02-02 18:32:36
Również, oprócz udzielonych odpowiedzi (łatwość wdrożenia połączona z porównywalną wydajnością do zbalansowanego drzewa). Uważam, że implementacja w kolejności przechodzenia (do przodu i do tyłu) jest o wiele prostsza, ponieważ lista pominięć skutecznie ma listę połączoną wewnątrz swojej implementacji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-11-02 06:32:23
W praktyce okazało się, że wydajność B-tree w moich projektach okazała się lepsza niż skip-list. Listy pominięć wydają się łatwiejsze do zrozumienia, ale implementacja drzewa B nie jest trudna.
Jedyną zaletą, o której wiem, Jest to, że niektórzy sprytni ludzie wymyślili, jak zaimplementować wolną od blokad listę współbieżnych pominięć, która wykorzystuje tylko operacje atomowe. Na przykład Java 6 zawiera klasę ConcurrentSkipListMap i można do niej odczytać kod źródłowy, jeśli szaleństwo.
Ale nie jest to zbyt trudne, aby napisać równoległy wariant B-tree albo-widziałem to zrobić przez kogoś innego - jeśli prewencyjnie podzielić i scalić węzły "na wszelki wypadek", jak idziesz w dół drzewa, to nie będziesz musiał martwić się o impas i zawsze trzeba trzymać blokadę na dwóch poziomach drzewa na raz. Narzut synchronizacji będzie nieco wyższy, ale B-tree jest prawdopodobnie szybszy.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-11-16 06:45:31
Z Wikipedii artykuł, który zacytowałeś:
Θ (n) operacje, które zmuszają nas do odwiedzenia każdego węzła w kolejności rosnącej(np. drukowanie całej listy) dają możliwość przeprowadzenia derandomizacji za kulisami struktury poziomów listy pominięć w optymalny sposób, doprowadzając listę pominięć do czasu Wyszukiwania O (log n). [...] Listę przeskoków, na której nie mamy ostatnio wykonane [takie] operacje Θ (n), nie podaj ten sam bezwzględny worst-case gwarancja wydajności jako więcej tradycyjne zbilansowane dane drzew struktur , ponieważ zawsze jest możliwe (choć przy bardzo niskim prawdopodobieństwo), że monety-flipy używane aby zbudować listę przeskoków wytworzy źle zbalansowana struktura
EDIT: więc jest to kompromis: Pomiń listy zużywają mniej pamięci, ryzykując, że mogą przekształcić się w niezrównoważone drzewo.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-06-11 08:41:10
Pomiń listy są implementowane przy użyciu list.
Rozwiązania typu Lock free istnieją dla list pojedynczo i Podwójnie połączonych - ale nie istnieją rozwiązania typu lock free, które bezpośrednio używają tylko CAS dla dowolnej struktury danych o (logn).
Możesz jednak używać list opartych na CAS do tworzenia list pominięć.
(zauważ, że MCA, które jest tworzone za pomocą CAS, pozwala na dowolne struktury danych i dowód koncepcji czerwono-czarne drzewo zostało utworzone za pomocą MCA).
Tak więc, dziwne jak są, okazują się be very useful : -)
Listy przeskakujące mają tę zaletę, że blokują blokadę. Ale, czas runt zależy od tego, jak poziom nowego węzła jest zdecydowany. Zwykle odbywa się to za pomocą funkcji Random (). W słowniku 56000 słów pomiń listę zajęło więcej czasu niż drzewo splay, a drzewo zajęło więcej czasu niż tabela hash. Dwie pierwsze nie mogły dorównać czasowi trwania tabeli hash. Również tablica tabeli hash może być zablokowana w sposób współbieżny.
Pomiń listę i podobne uporządkowane listy są używane, gdy potrzebne jest odniesienie. W przypadku ex: wyszukiwanie lotów obok i przed datą we wniosku.
Inmemory Binary Search splay tree jest świetny i częściej używany.
Pomiń listę vs splay Tree Vs Hash Table Runtime on dictionary find op
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-04-06 08:17:08