Wykreślanie szybkiej transformacji Fouriera w Pythonie
Mam dostęp do numpy i scipy i chcę stworzyć prosty FFT zbioru danych. Mam dwie listy, jedna to wartości y, a druga to znaczniki czasu dla tych wartości Y.
Jaki jest najprostszy sposób, aby wprowadzić te listy do metody scipy lub numpy i wykreślić wynik FFT?
Szukałem przykładów, ale wszystkie polegają na stworzeniu zestawu fałszywych danych z pewną liczbą punktów danych, częstotliwością itp. i tak naprawdę nie pokazuje, jak to zrobić za pomocą tylko zestawu danych i odpowiednie znaczniki czasu.
Wypróbowałem następujący przykład:
from scipy.fftpack import fft
# Number of samplepoints
N = 600
# sample spacing
T = 1.0 / 800.0
x = np.linspace(0.0, N*T, N)
y = np.sin(50.0 * 2.0*np.pi*x) + 0.5*np.sin(80.0 * 2.0*np.pi*x)
yf = fft(y)
xf = np.linspace(0.0, 1.0/(2.0*T), N/2)
import matplotlib.pyplot as plt
plt.plot(xf, 2.0/N * np.abs(yf[0:N/2]))
plt.grid()
plt.show()
Ale kiedy zmienię argument fft na mój zestaw danych i wykreślę go, otrzymuję bardzo dziwne wyniki, wygląda na to, że skalowanie dla częstotliwości może być wyłączone. nie jestem pewien.
Tutaj jest pastebin danych, które próbuję FFTHttp://pastebin.com/0WhjjMkb http://pastebin.com/ksM4FvZS
Kiedy robię fft na całej rzeczy, to po prostu ma ogromny skok na zero i nic więcej
Oto Mój kod:
## Perform FFT WITH SCIPY
signalFFT = fft(yInterp)
## Get Power Spectral Density
signalPSD = np.abs(signalFFT) ** 2
## Get frequencies corresponding to signal PSD
fftFreq = fftfreq(len(signalPSD), spacing)
## Get positive half of frequencies
i = fftfreq>0
##
plt.figurefigsize=(8,4));
plt.plot(fftFreq[i], 10*np.log10(signalPSD[i]));
#plt.xlim(0, 100);
plt.xlabel('Frequency Hz');
plt.ylabel('PSD (dB)')
Odstęp jest równy xInterp[1]-xInterp[0]
4 answers
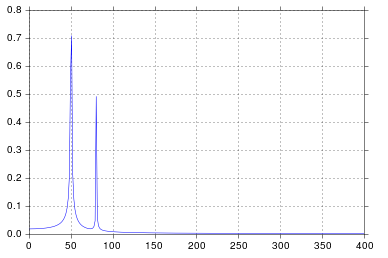
Więc uruchamiam funkcjonalnie równoważną formę Twojego kodu w notatniku IPython:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import scipy.fftpack
# Number of samplepoints
N = 600
# sample spacing
T = 1.0 / 800.0
x = np.linspace(0.0, N*T, N)
y = np.sin(50.0 * 2.0*np.pi*x) + 0.5*np.sin(80.0 * 2.0*np.pi*x)
yf = scipy.fftpack.fft(y)
xf = np.linspace(0.0, 1.0/(2.0*T), N/2)
fig, ax = plt.subplots()
ax.plot(xf, 2.0/N * np.abs(yf[:N//2]))
plt.show()
Dostaję to, co uważam za bardzo rozsądne wyjście.
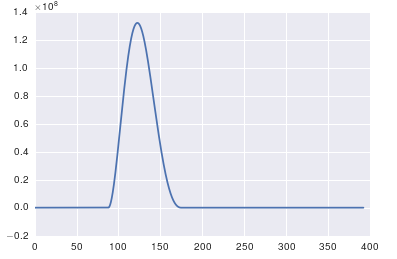
W odpowiedzi na publikowane dane i komentarze
Problem polega na tym, że nie masz okresowych danych. Zawsze powinieneś sprawdzić dane, które wprowadzasz do dowolnego algorytmu, aby upewnić się, że jest to właściwe.
import pandas
import matplotlib.pyplot as plt
#import seaborn
%matplotlib inline
# the OP's data
x = pandas.read_csv('http://pastebin.com/raw.php?i=ksM4FvZS', skiprows=2, header=None).values
y = pandas.read_csv('http://pastebin.com/raw.php?i=0WhjjMkb', skiprows=2, header=None).values
fig, ax = plt.subplots()
ax.plot(x, y)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-27 20:30:29
Ważną rzeczą w fft jest to, że może być stosowany tylko do danych, w których znacznik czasu jest jednolity (tj. jednolite pobieranie próbek w czasie, jak pokazano powyżej).
W przypadku niejednorodnego pobierania próbek należy użyć funkcji do dopasowania danych. Istnieje kilka samouczków i funkcji do wyboru:
Https://github.com/tiagopereira/python_tips/wiki/Scipy%3A-curve-fitting http://docs.scipy.org/doc/numpy/reference/generated/numpy.polyfit.html
Jeśli dopasowanie nie jest opcją, możesz bezpośrednio użyć jakiejś formy interpolacji, aby interpolować dane do jednolitego pobierania próbek:
Https://docs.scipy.org/doc/scipy-0.14.0/reference/tutorial/interpolate.html
Gdy masz jednolite próbki, będziesz musiał tylko martwić się o delta czasu (t[1] - t[0]) swoich próbek. W takim przypadku możesz bezpośrednio użyć fft funkcje
Y = numpy.fft.fft(y)
freq = numpy.fft.fftfreq(len(y), t[1] - t[0])
pylab.figure()
pylab.plot( freq, numpy.abs(Y) )
pylab.figure()
pylab.plot(freq, numpy.angle(Y) )
pylab.show()
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-01-24 20:35:35
Wysoki skok, jaki masz, wynika z części DC (niezrównanej, tj. freq = 0) twojego sygnału. To kwestia skali. Jeśli chcesz zobaczyć zawartość częstotliwości innej niż DC, do wizualizacji może być konieczne wykreślenie z offsetu 1, a nie z offsetu 0 FFT sygnału.
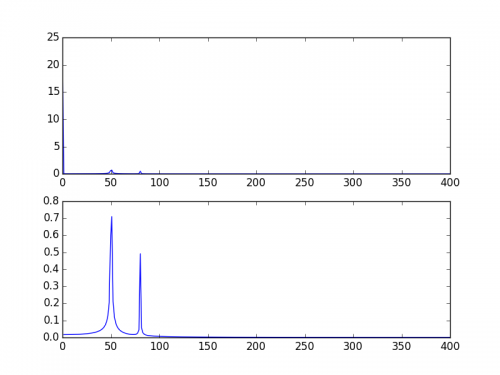
Modyfikowanie przykładu podanego powyżej przez @ PaulH
import numpy as np
import matplotlib.pyplot as plt
import scipy.fftpack
# Number of samplepoints
N = 600
# sample spacing
T = 1.0 / 800.0
x = np.linspace(0.0, N*T, N)
y = 10 + np.sin(50.0 * 2.0*np.pi*x) + 0.5*np.sin(80.0 * 2.0*np.pi*x)
yf = scipy.fftpack.fft(y)
xf = np.linspace(0.0, 1.0/(2.0*T), N/2)
plt.subplot(2, 1, 1)
plt.plot(xf, 2.0/N * np.abs(yf[0:N/2]))
plt.subplot(2, 1, 2)
plt.plot(xf[1:], 2.0/N * np.abs(yf[0:N/2])[1:])
Wykresy wyjściowe:
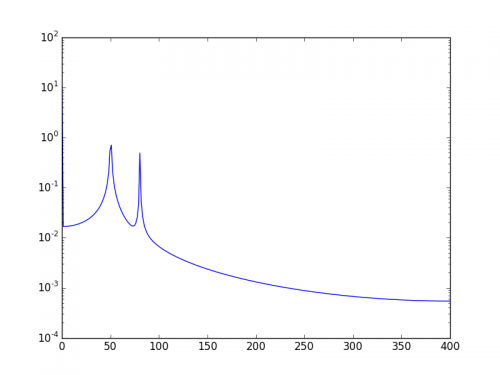
Innym sposobem jest wizualizacja danych w skali logów:
Użycie:
plt.semilogy(xf, 2.0/N * np.abs(yf[0:N/2]))
Pokaże:
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-05-06 13:24:45
[1]} jako uzupełnienie udzielonych już odpowiedzi, chciałbym zwrócić uwagę, że często ważne jest, aby bawić się wielkością pojemników na FFT. Sensowne byłoby przetestowanie kilku wartości i wybranie tej, która ma większy sens dla Twojej aplikacji. Często jest w tej samej wielkości liczby próbek. Zostało to przyjęte przez większość udzielonych odpowiedzi i daje wspaniałe i rozsądne wyniki. Jeśli ktoś chce to zbadać, Oto Mój kod Wersja:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import scipy.fftpack
fig = plt.figure(figsize=[14,4])
N = 600 # Number of samplepoints
Fs = 800.0
T = 1.0 / Fs # N_samps*T (#samples x sample period) is the sample spacing.
N_fft = 80 # Number of bins (chooses granularity)
x = np.linspace(0, N*T, N) # the interval
y = np.sin(50.0 * 2.0*np.pi*x) + 0.5*np.sin(80.0 * 2.0*np.pi*x) # the signal
# removing the mean of the signal
mean_removed = np.ones_like(y)*np.mean(y)
y = y - mean_removed
# Compute the fft.
yf = scipy.fftpack.fft(y,n=N_fft)
xf = np.arange(0,Fs,Fs/N_fft)
##### Plot the fft #####
ax = plt.subplot(121)
pt, = ax.plot(xf,np.abs(yf), lw=2.0, c='b')
p = plt.Rectangle((Fs/2, 0), Fs/2, ax.get_ylim()[1], facecolor="grey", fill=True, alpha=0.75, hatch="/", zorder=3)
ax.add_patch(p)
ax.set_xlim((ax.get_xlim()[0],Fs))
ax.set_title('FFT', fontsize= 16, fontweight="bold")
ax.set_ylabel('FFT magnitude (power)')
ax.set_xlabel('Frequency (Hz)')
plt.legend((p,), ('mirrowed',))
ax.grid()
##### Close up on the graph of fft#######
# This is the same histogram above, but truncated at the max frequence + an offset.
offset = 1 # just to help the visualization. Nothing important.
ax2 = fig.add_subplot(122)
ax2.plot(xf,np.abs(yf), lw=2.0, c='b')
ax2.set_xticks(xf)
ax2.set_xlim(-1,int(Fs/6)+offset)
ax2.set_title('FFT close-up', fontsize= 16, fontweight="bold")
ax2.set_ylabel('FFT magnitude (power) - log')
ax2.set_xlabel('Frequency (Hz)')
ax2.hold(True)
ax2.grid()
plt.yscale('log')
Wykresy wyjściowe:

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-01-14 20:30:35