Co oznaczają 'real', 'user' i ' sys ' na wyjściu czasu(1)?
$ time foo
real 0m0.003s
user 0m0.000s
sys 0m0.004s
$
Co oznaczają 'real', 'user' i ' sys ' na wyjściu czasu?
Który z nich ma znaczenie podczas porównywania mojej aplikacji?
7 answers
Statystyki czasu rzeczywistego, użytkownika i Sys
Jedna z tych rzeczy nie jest taka jak druga. Real odnosi się do rzeczywistego czasu, który upłynął; User i Sys odnoszą się do czasu procesora używanego {23]}tylko przez proces.
Real {[20] } to zegar ścienny-czas Od początku do końca połączenia. Jest to cały czas, który upłynął wraz z plasterkami czasu używanymi przez inne procesy i czasem, który proces spędza zablokowany (na przykład, jeśli czeka na wejście / wyjście kompletny).
User to ilość czasu procesora spędzonego w kodzie trybu użytkownika (poza jądrem) w obrębie procesu. Jest to tylko rzeczywisty czas procesora używany podczas wykonywania procesu. Inne procesy i czas, który proces spędza zablokowany, nie liczą się do tej liczby.
Sys to ilość czasu CPU spędzonego w jądrze w procesie. Oznacza to wykonywanie czasu procesora spędzonego w wywołaniach systemowych wewnątrz jądra, jako w przeciwieństwie do kodu biblioteki, który nadal działa w przestrzeni użytkownika. Podobnie jak "użytkownik", jest to tylko czas procesora używany przez proces. Poniżej znajduje się Krótki opis trybu jądra (znanego również jako tryb nadzorcy) oraz mechanizmu wywołania systemowego.
User+Sys powie Ci, ile rzeczywistego czasu procesora wykorzystałeś. Zauważ, że dotyczy to wszystkich procesorów, więc jeśli proces ma wiele wątków (a proces ten działa na komputerze z więcej niż jednym procesorem), może potencjalnie przekrocz czas zegara ściennego podany przez Real (który zwykle występuje). Zauważ, że na wyjściu te liczby zawierają User i Sys Czas wszystkich procesów potomnych (i ich potomków), jak również kiedy mogły zostać zebrane, np. przez wait(2) lub waitpid(2), chociaż podstawowe wywołania systemowe zwracają statystyki dla procesu i jego potomków oddzielnie.
Pochodzenie danych statystycznych przekazywanych przez time (1)
Statystyki przekazywane przez time są zbierane z różne wywołania systemowe. "User" i " Sys " pochodzą z wait (2) (POSIX ) lub times (2) (POSIX ), w zależności od konkretnego systemu. "Real" jest obliczany od czasu rozpoczęcia i zakończenia zebranego z gettimeofday (2) sprawdzam. W zależności od wersji systemu, różne inne statystyki, takie jak liczba przełączników kontekstowych, mogą być również gromadzone przez time.
Na maszynie wieloprocesorowej, wielowątkowy proces lub proces rozwidlający dzieci mogą upłynął czas mniejszy niż całkowity czas procesora-ponieważ różne wątki lub procesy mogą działać równolegle. Ponadto zgłaszane statystyki czasu pochodzą z różnych źródeł, więc czasy rejestrowane dla bardzo krótkich zadań biegowych mogą podlegać błędom zaokrąglania, jak pokazuje przykład podany na oryginalnym plakacie.
W 2011 roku w kernelu odbyła się premiera filmu pt.]} W systemie Unix lub dowolnym systemie operacyjnym z chronioną pamięcią, tryb "Kernel" lub "Supervisor" odnosi się do tryb uprzywilejowany w którym procesor może pracować. Niektóre akcje uprzywilejowane, które mogą mieć wpływ na bezpieczeństwo lub stabilność, mogą być wykonywane tylko wtedy, gdy procesor pracuje w tym trybie; te akcje nie są dostępne dla kodu aplikacji. Przykładem takiego działania może być manipulacja MMU w celu uzyskania dostępu do przestrzeni adresowej innego procesu. Zwykle tryb użytkownika kod nie może tego zrobić (z dobrego powodu), chociaż może zażądać współdzielonej pamięci Z jądro, które Może być odczytywane lub pisane przez więcej niż jeden proces. W tym przypadku pamięć dzielona jest bezpośrednio wymagana od jądra za pośrednictwem bezpiecznego mechanizmu i oba procesy muszą się do niej wyraźnie dołączyć, aby z niej korzystać.
Tryb uprzywilejowany jest zwykle określany jako "kernel", ponieważ jądro jest wykonywane przez procesor działający w tym trybie. Aby przełączyć się w tryb jądra musisz wydać określoną instrukcję (często nazywaną pułapka) to przełącza procesor do pracy w trybie jądra i uruchamia kod z określonego miejsca trzymanego w tabeli skoków. ze względów bezpieczeństwa, nie można przełączyć się w tryb jądra i wykonać dowolny kod - pułapki są zarządzane za pomocą tabeli adresów, na które nie można zapisać, chyba że procesor działa w trybie nadzorcy. Pułapka z wyraźnym numerem pułapki i adres jest sprawdzany w tabeli skoku; jądro ma skończoną liczbę kontrolowanego wpisu punktów.
Wywołania 'system' w bibliotece C (szczególnie te opisane w sekcji 2 stron podręcznika) mają komponent trybu użytkownika, który jest tym, co w rzeczywistości wywołujesz z programu C. Za kulisami mogą wydawać jedno lub więcej wywołań systemowych do jądra w celu wykonania określonych usług, takich jak I/O, ale nadal mają również kod uruchomiony w trybie użytkownika. Jest również całkiem możliwe bezpośrednie wydanie pułapki w trybie jądra z dowolnego kodu przestrzeni użytkownika, jeśli jest to pożądane, chociaż może być konieczne napisanie fragment języka asemblacji, aby poprawnie skonfigurować rejestry dla wywołania.
Więcej o ' sys '
Są rzeczy, których Twój kod nie może zrobić z trybu użytkownika - takie jak przydzielanie pamięci lub dostęp do sprzętu (HDD, sieci itp.). Są one pod nadzorem jądra i tylko ono może je wykonać. Niektóre operacje jak malloc lubfread/fwrite wywoła te funkcje jądra, które wtedy będą liczone jako czas 'sys'. Niestety nie jest to takie proste jak "każde połączenie do malloc będzie liczone w' sys 'czasie". Wywołanie malloc wykona własne przetwarzanie (nadal liczone w czasie 'user') i gdzieś po drodze może wywołać funkcję w jądrze (liczoną w czasie 'sys'). Po powrocie z wywołania jądra, będzie trochę więcej czasu w 'user', a następnie malloc powróci do Twojego kodu. Co do tego, kiedy następuje przełączenie i ile z tego jest wydawane w trybie jądra... nie możesz powiedzieć. To zależy od implementacji biblioteki. Ponadto inne pozornie niewinne funkcje mogą również używać malloc i tym podobnych w tle, które ponownie będą miały trochę czasu w 'sys'.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-06-25 11:28:44
Aby rozwinąć zaakceptowaną odpowiedź, chciałem tylko podać inny powód, dla którego real ≠ user + sys.
Należy pamiętać, że real reprezentuje rzeczywisty czas, który upłynął, podczas gdy user i sys reprezentuje czas wykonania procesora. W rezultacie, w systemie wielordzeniowym, user i/lub sys czas (jak również ich suma) może faktycznie przekroczyć Czas rzeczywisty. Na przykład, w aplikacji Java używam dla klasy otrzymuję ten zestaw wartości:
real 1m47.363s
user 2m41.318s
sys 0m4.013s
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:34:44
• real : rzeczywisty czas spędzony na uruchamianiu procesu od początku do końca, tak jakby był mierzony przez człowieka za pomocą stopera
• Użytkownik : łączny czas spędzony przez wszystkie procesory podczas obliczeń
• sys : łączny czas spędzony przez wszystkie procesory podczas zadań związanych z systemem, takich jak alokacja pamięci.
Zauważ, że czasami user + sys może być większy niż rzeczywisty, ponieważ wiele procesorów może pracować w równolegle.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-24 19:05:56
Minimal runnable POSIX C examples
Aby wszystko było bardziej konkretne, chcę zilustrować kilka ekstremalnych przypadków time z minimalnymi programami testowymi C.
Wszystkie programy mogą być kompilowane i uruchamiane za pomocą:
gcc -ggdb3 -o main.out -pthread -std=c99 -pedantic-errors -Wall -Wextra main.c
time ./main.out
Sen
Non-busy sen nie liczy się ani w user ani w sys, tylko w real.
Na przykład program, który śpi przez sekundę:
#define _XOPEN_SOURCE 700
#include <stdlib.h>
#include <unistd.h>
int main(void) {
sleep(1);
return EXIT_SUCCESS;
}
Wypisuje coś w stylu:
real 0m1.003s
user 0m0.001s
sys 0m0.003s
To samo dotyczy programów blokowanych na IO, które stają się dostępne.
Na przykład następujący program czeka na wpisanie znaku przez użytkownika i naciśnięcie klawisza enter:
#include <stdio.h>
#include <stdlib.h>
int main(void) {
printf("%c\n", getchar());
return EXIT_SUCCESS;
}
I jeśli poczekasz około jednej sekundy, wyświetli podobnie jak przykład snu coś w stylu:
real 0m1.003s
user 0m0.001s
sys 0m0.003s
Z tego powodu time może pomóc w rozróżnieniu programów CPU i IO bound: co oznaczają terminy "CPU bound" i "I/O bound"?
Wiele wątków
Poniższy przykład wykonuje niters iteracje bezużytecznych, czysto związanych z CPU wątków na nthreads:
#define _XOPEN_SOURCE 700
#include <assert.h>
#include <inttypes.h>
#include <pthread.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
uint64_t niters;
void* my_thread(void *arg) {
uint64_t *argument, i, result;
argument = (uint64_t *)arg;
result = *argument;
for (i = 0; i < niters; ++i) {
result = (result * result) - (3 * result) + 1;
}
*argument = result;
return NULL;
}
int main(int argc, char **argv) {
size_t nthreads;
pthread_t *threads;
uint64_t rc, i, *thread_args;
/* CLI args. */
if (argc > 1) {
niters = strtoll(argv[1], NULL, 0);
} else {
niters = 1000000000;
}
if (argc > 2) {
nthreads = strtoll(argv[2], NULL, 0);
} else {
nthreads = 1;
}
threads = malloc(nthreads * sizeof(*threads));
thread_args = malloc(nthreads * sizeof(*thread_args));
/* Create all threads */
for (i = 0; i < nthreads; ++i) {
thread_args[i] = i;
rc = pthread_create(
&threads[i],
NULL,
my_thread,
(void*)&thread_args[i]
);
assert(rc == 0);
}
/* Wait for all threads to complete */
for (i = 0; i < nthreads; ++i) {
rc = pthread_join(threads[i], NULL);
assert(rc == 0);
printf("%" PRIu64 " %" PRIu64 "\n", i, thread_args[i]);
}
free(threads);
free(thread_args);
return EXIT_SUCCESS;
}
GitHub upstream + kod wykresu .
Następnie wykreślamy wall, user i sys jako funkcję liczby w przeciwieństwie do innych komputerów, które nie są w pełni kompatybilne z procesorem hyperthread, nie są w pełni kompatybilne z procesorem hyperthread.]}
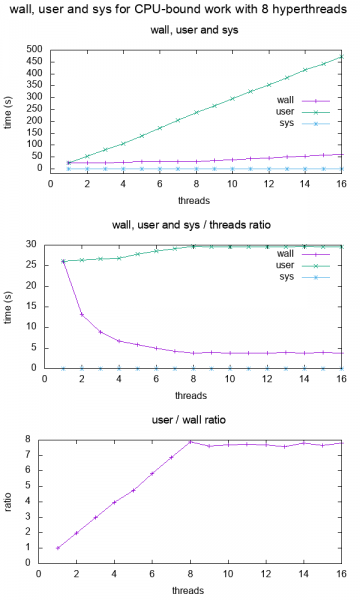
Z wykresu widzimy, że:
- W przypadku aplikacji jednordzeniowych, wall i użytkownik są mniej więcej takie same.]}
-
Dla 2 rdzeni, użytkownik jest około 2x ścianą, co oznacza, że czas użytkownika jest liczony we wszystkich wątkach.
Użytkownik w zasadzie podwoił się, a ściana pozostała taka sama.
-
To kontynuuje do 8 wątków, co odpowiada mojej liczbie hyperthreads w moim komputerze.
Po 8, wall również zaczyna się zwiększać, ponieważ nie mamy żadnych dodatkowych procesorów, aby włożyć więcej pracy w danym czasie!
Stosunek w tym momencie.
Zauważ, że ten wykres jest tak przejrzysty i prosty, ponieważ praca jest czysto związana z procesorem: gdyby była związana z pamięcią, to spadlibyśmy wydajność znacznie wcześniej z mniejszą ilością rdzeni, ponieważ pamięć dostęp byłby wąskim gardłem, jak pokazano na co oznaczają terminy" CPU bound "i" I / O bound"?
W ten sposób można w prosty sposób określić, że program jest wielowątkowy, a im bliżej jest tego stosunku do liczby rdzeni, tym bardziej efektywna jest równoległość, np.:]}- wielowątkowe łączniki: czy gcc może używać wielu rdzeni podczas łączenia?
- C++ parallel sort: to zaimplementowane algorytmy równoległe C++17 już?
Sys ciężka praca z sendfile
Najcięższym obciążeniem sys, jakie mogłem wymyślić, było użycie sendfile, które wykonuje operację kopiowania plików w przestrzeni jądra: skopiuj plik w rozsądny, bezpieczny i wydajny sposób {37]}
Więc wyobrażałem sobie, że to jądro memcpy będzie intensywne działanie procesora.
Najpierw inicjalizuję duży losowy plik 10gib za pomocą:
dd if=/dev/urandom of=sendfile.in.tmp bs=1K count=10M
Następnie uruchom kod:
#define _GNU_SOURCE
#include <assert.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/sendfile.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
int main(int argc, char **argv) {
char *source_path, *dest_path;
int source, dest;
struct stat stat_source;
if (argc > 1) {
source_path = argv[1];
} else {
source_path = "sendfile.in.tmp";
}
if (argc > 2) {
dest_path = argv[2];
} else {
dest_path = "sendfile.out.tmp";
}
source = open(source_path, O_RDONLY);
assert(source != -1);
dest = open(dest_path, O_WRONLY | O_CREAT | O_TRUNC, S_IRUSR | S_IWUSR);
assert(dest != -1);
assert(fstat(source, &stat_source) != -1);
assert(sendfile(dest, source, 0, stat_source.st_size) != -1);
assert(close(source) != -1);
assert(close(dest) != -1);
return EXIT_SUCCESS;
}
Co daje w zasadzie czas systemowy zgodnie z oczekiwaniami:
real 0m2.175s
user 0m0.001s
sys 0m1.476s
Byłem również ciekaw, czy time rozróżniłby syscalls różnych procesów, więc próbowałem: {]}
time ./sendfile.out sendfile.in1.tmp sendfile.out1.tmp &
time ./sendfile.out sendfile.in2.tmp sendfile.out2.tmp &
A wynik był taki:
real 0m3.651s
user 0m0.000s
sys 0m1.516s
real 0m4.948s
user 0m0.000s
sys 0m1.562s
Czas sys jest mniej więcej taki sam dla obu procesów jak dla pojedynczego procesu, ale czas ściany jest większy, ponieważ procesy konkurują o dostęp do odczytu dysku.
Wygląda więc na to, że faktycznie bierze pod uwagę, który proces rozpoczął pracę nad danym jądrem.
Bash source code
Kiedy robisz tylko time <cmd> na Ubuntu, używasz słowa kluczowego Bash, jak widać z:
type time
Które wyjście:
time is a shell keyword
Więc grep źródło w kodzie źródłowym Bash 4.19 Dla ciągu wyjściowego:
git grep '"user\b'
Co prowadzi nas do execute_cmd.C funkcja time_command, która wykorzystuje:
-
gettimeofday()igetrusage()jeśli oba są dostępne -
times()inaczej
Wszystkie są to wywołania systemowe Linuksa oraz funkcje POSIX.
Kod źródłowy GNU Coreutils
Jeśli nazwiemy to jako:
/usr/bin/time
Następnie używa implementacji GNU Coreutils.
Ten jest nieco bardziej złożony, ale odpowiednie źródło wydaje się być w resuse.c i robi:
- a non-POSIX BSD
wait3call if that ' s available -
timesigettimeofdayinaczej
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-09-29 23:09:30
Real pokazuje całkowity czas zwrotu dla procesu; podczas gdy użytkownik pokazuje czas wykonania instrukcji zdefiniowanych przez użytkownika a Sys to czas na wykonywanie wywołań systemowych!
Real time obejmuje również czas oczekiwania (czas oczekiwania na I / O itd.)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-11-05 04:34:14
W bardzo prostych słowach, lubię myśleć o tym w ten sposób:
-
realjest to rzeczywisty czas potrzebny na uruchomienie polecenia (tak, jakbyś mierzył czas za pomocą stopera) -
userisysto ile' pracy ' musiał wykonaćCPU, aby wykonać polecenie. Ta "praca" wyrażona jest w jednostkach czasu.
Ogólnie mówiąc:
-
userile pracy wykonałoCPU, aby uruchomić kod polecenia -
sysjest to, ile pracyCPUmusiał wykonać, aby obsłużyć zadania typu "system overhead" (takie jak przydzielanie pamięci, We/Wy plików, itp.) w celu obsługi komendy running
Ponieważ te dwa ostatnie razy liczą "pracę" wykonaną, nie uwzględniają czasu, jaki wątek mógł poświęcić na oczekiwanie (np. czekanie na inny proces lub na zakończenie wejścia/Wyjścia dysku).
real, jednak jest miarą rzeczywistego czasu pracy, a nie "pracy", więc zawiera każdy czas oczekiwania.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-07-19 01:13:15
Chcę wspomnieć o innym scenariuszu, gdy czas rzeczywisty jest znacznie większy niż user + sys. Stworzyłem prosty serwer, który reaguje po długim czasie
real 4.784
user 0.01s
sys 0.01s
Problem polega na tym, że w tym scenariuszu proces czeka na odpowiedź, która nie znajduje się na Stronie Użytkownika ani w systemie.
Coś podobnego dzieje się po uruchomieniu find polecenia. W takim przypadku czas spędzany jest głównie na żądaniu i otrzymywaniu odpowiedzi od dysku SSD.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-10-30 13:50:20