Łączenie strun z kilku rzędów za pomocą Pandy groupby
Chcę połączyć kilka łańcuchów w ramce danych opartej na groupedby w pandach.
To jest mój kod do tej pory:
import pandas as pd
from io import StringIO
data = StringIO("""
"name1","hej","2014-11-01"
"name1","du","2014-11-02"
"name1","aj","2014-12-01"
"name1","oj","2014-12-02"
"name2","fin","2014-11-01"
"name2","katt","2014-11-02"
"name2","mycket","2014-12-01"
"name2","lite","2014-12-01"
""")
# load string as stream into dataframe
df = pd.read_csv(data,header=0, names=["name","text","date"],parse_dates=[2])
# add column with month
df["month"] = df["date"].apply(lambda x: x.month)
Chcę, aby efekt końcowy wyglądał tak:
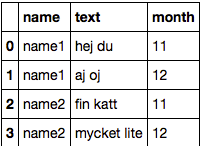
Nie rozumiem, jak mogę użyć groupby i zastosować jakiś rodzaj konkatenacji łańcuchów w kolumnie "tekst". Każda pomoc mile widziana!
5 answers
Możesz grupować kolumny 'name' i 'month', następnie wywołać transform, które zwrócą dane wyrównane do oryginalnego df i zastosować lambda, gdzie join wpisy tekstowe:
In [119]:
df['text'] = df[['name','text','month']].groupby(['name','month'])['text'].transform(lambda x: ','.join(x))
df[['name','text','month']].drop_duplicates()
Out[119]:
name text month
0 name1 hej,du 11
2 name1 aj,oj 12
4 name2 fin,katt 11
6 name2 mycket,lite 12
Podaję oryginalny df, przekazując listę interesujących kolumn df[['name','text','month']] tutaj, a następnie wywołuję drop_duplicates
EDIT właściwie mogę po prostu zadzwonić apply i wtedy reset_index:
In [124]:
df.groupby(['name','month'])['text'].apply(lambda x: ','.join(x)).reset_index()
Out[124]:
name month text
0 name1 11 hej,du
1 name1 12 aj,oj
2 name2 11 fin,katt
3 name2 12 mycket,lite
Update
lambda jest tu niepotrzebny:
In[38]:
df.groupby(['name','month'])['text'].apply(','.join).reset_index()
Out[38]:
name month text
0 name1 11 du
1 name1 12 aj,oj
2 name2 11 fin,katt
3 name2 12 mycket,lite
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-10 09:48:27
Możemy groupby kolumny 'Nazwa' i 'miesiąc', następnie wywołać funkcje agg() obiektów ramki danych Pandy.
Funkcja agregacji dostarczana przez funkcję agg () umożliwia obliczanie wielu statystyk na grupę w jednym obliczeniu.
df.groupby(['name', 'month'], as_index = False).agg({'text': ' '.join})

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-12-11 10:48:40
ODPOWIEDŹ Edchuma zapewnia Ci dużą elastyczność, ale jeśli chcesz po prostu połączyć łańcuchy w kolumnę obiektów listy, możesz również:
output_series = df.groupby(['name','month'])['text'].apply(list)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-08-28 19:18:24
Dla mnie powyższe rozwiązania były bliskie, ale dodano trochę niechcianych /n i dtype: object, więc oto zmodyfikowana wersja:
df.groupby(['name', 'month'])['text'].apply(lambda text: ''.join(text.to_string(index=False))).str.replace('(\\n)', '').reset_index()
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-06-28 15:00:16
Jeśli chcesz połączyć swój "tekst"na liście:
df.groupby(['name', 'month'], as_index = False).agg({'text': list})
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-11-25 21:19:53