Jak Hadoop wykonuje podziały wejściowe?
Jest to pytanie koncepcyjne dotyczące Hadoop/HDFS. Powiedzmy, że masz plik zawierający 1 miliard linii. Dla uproszczenia przyjrzyjmy się, że każda linia ma postać <k,v>, gdzie k jest przesunięciem linii od początku, a wartość jest zawartością linii.
Teraz, Kiedy mówimy, że chcemy uruchomić N zadań map, Czy framework dzieli plik wejściowy na N podziałów i uruchamia każde zadanie mapowe na tym podziale? czy musimy napisać partycjonowanie funkcja, która dokonuje podziału N i uruchamia każde zadanie mapy na wygenerowanym podziale?
Chcę tylko wiedzieć, czy podziały są wykonywane wewnętrznie, czy musimy dzielić dane ręcznie?
Dokładniej, przy każdym wywołaniu funkcji map() jakie są jej parametry Key key and Value val?
Dzięki, Deepak
10 answers
InputFormat jest odpowiedzialny za zapewnienie podziałów.
Ogólnie rzecz biorąc, jeśli masz węzły n, HDFS rozdzieli plik na wszystkie węzły N. Jeśli rozpoczniesz pracę, domyślnie będzie n maperów. Dzięki Hadoop maper na maszynie przetworzy część danych przechowywanych na tym węźle. Myślę, że to się nazywa Rack awareness.
Krótko mówiąc: wgraj dane do HDFS i rozpocznij pracę MR. Hadoop zadba o zoptymalizowaną realizację.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-05-14 13:37:14
Pliki są dzielone na bloki HDFS, a bloki są replikowane. Hadoop przypisuje węzeł do podziału w oparciu o zasadę lokalizacji danych. Hadoop spróbuje uruchomić mapera na węzłach, w których znajduje się blok. Z powodu replikacji istnieje wiele takich węzłów hostujących ten sam blok.
W przypadku, gdy węzły nie są dostępne, Hadoop spróbuje wybrać węzeł, który jest najbliżej węzła, który hostuje blok danych. Może na przykład wybrać inny węzeł w tej samej szafie. Węzeł może nie są dostępne z różnych powodów; wszystkie sloty mapy mogą być używane lub węzeł może być po prostu nieaktywny.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-12-13 02:44:36
Na szczęście wszystko będzie załatwione przez framework.
Przetwarzanie danych MapReduce jest napędzane przez tę koncepcję input splits . Liczba podziałów wejściowych, które są obliczane dla konkretnej aplikacji, określa liczbę zadań mapera.
Liczba map jest zwykle zależna od liczby bloków DFS w plikach wejściowych.
Każde z tych zadań mapera jest przypisywane, o ile to możliwe, do węzła slave, w którym przechowywany jest podział danych wejściowych. Na Resource Manager (lub JobTracker, jeśli jesteś w Hadoop 1) dokłada wszelkich starań, aby zapewnić, że podziały wejściowe są przetwarzane lokalnie.
Jeśli Lokalizacja danych nie można osiągnąć z powodu podziałów wejściowych przekraczających granice węzłów danych, niektóre dane zostaną przeniesione z jednego węzła danych do innego węzła danych.
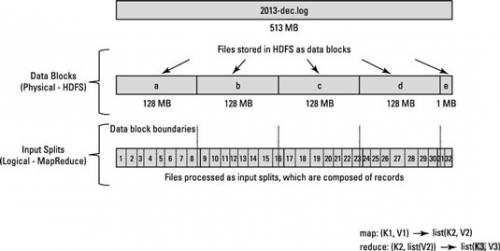
Załóżmy, że jest 128 MB bloku, a ostatni rekord nie zmieścił się w bloku a i spreaduje w bloku B , wtedy dane w bloku B zostaną skopiowane do węzeł posiadający Blok A
Spójrz na ten diagram.
Zobacz podobne pytania
O podziale plików Hadoop / HDFS
W Jaki Sposób rekordy procesów Hadoop są dzielone między granice bloków?
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 11:46:57
Myślę, że Deepak pytał bardziej o to, w jaki sposób dane wejściowe dla każdego wywołania funkcji mapy są ustalane, a nie dane obecne na każdej mapie węzła. Mówię to na podstawie drugiej części pytania: dokładniej, przy każdym wywołaniu funkcji map () jakie są jej parametry klucza i wartości val?
Właściwie to samo pytanie mnie tu sprowadziło, a gdybym był doświadczonym programistą hadoop, mógłbym zinterpretować to jak odpowiedzi powyżej.
Aby odpowiedzieć na pytanie,
Plik w danym węźle mapy jest dzielony na podstawie wartości InputFormat. (jest to wykonywane w Javie za pomocą setInputFormat () ! )
Przykład:
Conf.setInputFormat (TextInputFormat.Klasa); Tutaj, przekazując TextInputFormat do funkcji setInputFormat, mówimy hadoop, aby traktował każdy wiersz pliku wejściowego w węźle Mapy jako wejście do funkcji map. Liniowiec lub carriage-return są używane do sygnalizowania końca linii. więcej informacji na TextInputFormat!
W tym przykładzie: Klucze to pozycja w pliku, a wartości to linia tekstu.
Mam nadzieję, że to pomoże.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-03-19 20:53:26
Różnica między rozmiarem bloku a rozmiarem podziału wejścia.
Input Split jest logicznym podziałem danych, zasadniczo używanym podczas przetwarzania danych w programie MapReduce lub innych technikach przetwarzania. Wielkość podziału wejściowego jest wartością zdefiniowaną przez użytkownika, a programista Hadoop może wybrać rozmiar podziału na podstawie rozmiaru danych (ile danych przetwarzasz).
Input Split jest w zasadzie używany do kontrolowania liczby maperów w programie MapReduce. Jeśli nie zdefiniowano wielkości wejścia podziel rozmiar w Program MapReduce wtedy domyślny podział bloków HDFS będzie traktowany jako podział danych wejściowych podczas przetwarzania danych.
Przykład:
Załóżmy, że masz plik 100MB, a domyślna konfiguracja bloku HDFS to 64MB, wtedy zostanie on podzielony na 2 bloki i zajmie dwa bloki HDFS. Teraz masz program MapReduce do przetwarzania tych danych, ale nie określiłeś podziału wejściowego wtedy na podstawie liczby bloków (Blok 2) będzie uważany za podział wejściowy dla przetwarzania MapReduce i dwóch mapper zostanie przydzielony do tej pracy. Ale załóżmy, że określiłeś rozmiar podziału (powiedzmy 100MB) w swoim programie MapReduce, wtedy oba bloki (2 bloki) będą traktowane jako pojedynczy podział dla przetwarzania MapReduce i jeden maper zostanie przypisany do tego zadania.
Teraz Załóżmy, że określiłeś rozmiar podziału (powiedzmy 25MB) w programie MapReduce, wtedy będzie 4 Podział wejściowy dla programu MapReduce, a 4 Mapper zostanie przypisany do praca.
Wniosek:
- Input Split jest logicznym podziałem danych wejściowych, podczas gdy HDFS block jest fizycznym podziałem danych.
- domyślny rozmiar bloku HDFS jest domyślnym rozmiarem podzielonym, jeśli podział wejściowy nie jest określony przez kod.
- Split jest zdefiniowany przez użytkownika i użytkownik może kontrolować rozmiar split w swoim programie MapReduce.
- jeden podział może być mapowany na wiele bloków i może być wiele podziału jednego bloku.
- liczba zadań na mapie (Mapper) są równe liczbie podziałów wejściowych.
Źródło : https://hadoopjournal.wordpress.com/2015/06/30/mapreduce-input-split-versus-hdfs-blocks/
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-08-15 07:21:57
FileInputFormat jest klasą abstrakcyjną, która określa, w jaki sposób pliki wejściowe są odczytywane i rozlewane. FileInputFormat udostępnia następujące funkcjonalności: 1. wybierz pliki / obiekty, które mają być użyte jako dane wejściowe 2. Definiuje inputsplits, który rozbija plik na zadanie.
Zgodnie z podstawową funkcjonalnością hadoopp, jeśli jest n podziałów, to będzie n mapper.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-11-25 08:05:18
Gdy zadanie Hadoop jest uruchomione, dzieli pliki wejściowe na kawałki i przypisuje każdy podział do mapera do przetworzenia; nazywa się to InputSplit.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-08-01 11:56:27
Krótka odpowiedź to InputFormat dbaj o podział pliku.
Podchodzę do tego pytania patrząc na domyślną klasę TextInputFormat:
Wszystkie klasy InputFormat są podklasą FileInputFormat, która zajmuje się podziałem.
W szczególności funkcja Getsplit FileInputFormat generuje listę InputSplit z listy plików zdefiniowanych w JobContext. Podział opiera się na wielkości bajtów, których Min i Max można zdefiniować dowolnie w pliku XML projektu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-11-20 22:37:51
Istnieje osobne zadanie zmniejszania map, które dzieli pliki na bloki. Użyj FileInputFormat dla dużych plików i CombineFileInput Format dla mniejszych. Można również sprawdzić, czy dane wejściowe można podzielić na bloki metodą issplittable. Każdy blok jest następnie przesyłany do węzła danych, gdzie uruchamiane jest zadanie map reduce w celu dalszej analizy. rozmiar bloku zależy od rozmiaru, o którym wspomniałeś w mapred.max.split.parametr rozmiaru.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-03-19 09:43:41
FileInputFormat.addInputPath( job, new Path(args[ 0])); or
Conf.setInputFormat (TextInputFormat.class);
Class FileInputFormat funcation addInputPath ,setInputFormat dbaj o inputsplit, również ten kod określa liczbę tworzonych maperów. możemy powiedzieć, że inputsplit i liczba maperów jest bezpośrednio proporcjonalna do liczby bloków używanych do przechowywania pliku wejściowego na HDFS.
Ex. jeśli mamy plik wejściowy o rozmiarze 74 Mb, plik ten przechowywane na HDFS w dwóch blokach (64 MB i 10 Mb). tak więc inputsplit dla tego pliku jest dwa i dwie instancje mapera są tworzone do odczytu tego pliku wejściowego.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-07-02 06:49:21