Jak zapisać i załadować numpy.array () dane poprawnie?
Zastanawiam się, jak poprawnie zapisać i załadować numpy.array Dane. Obecnie używam metody numpy.savetxt(). Na przykład, jeśli mam tablicę markers, która wygląda tak:
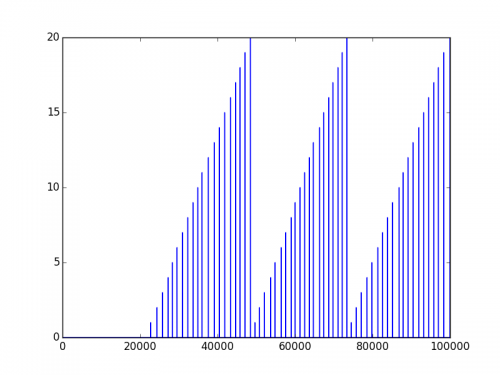
Staram się go zapisać za pomocą:
numpy.savetxt('markers.txt', markers)
W innym skrypcie próbuję otworzyć wcześniej zapisany plik:
markers = np.fromfile("markers.txt")
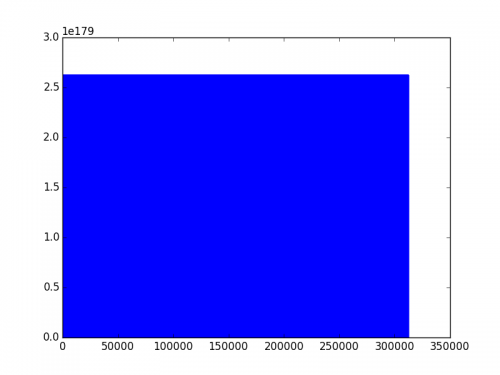
Zapisane dane najpierw wyglądają tak:
0.000000000000000000e+00
0.000000000000000000e+00
0.000000000000000000e+00
0.000000000000000000e+00
0.000000000000000000e+00
0.000000000000000000e+00
0.000000000000000000e+00
0.000000000000000000e+00
0.000000000000000000e+00
0.000000000000000000e+00
Ale kiedy zapisuję tylko załadowane dane za pomocą tej samej metody, ie. numpy.savetxt() wygląda tak:
1.398043286095131769e-76
1.398043286095288860e-76
1.396426376485745879e-76
1.398043286055061908e-76
1.398043286095288860e-76
1.182950697433698368e-76
1.398043275797188953e-76
1.398043286095288860e-76
1.210894289234927752e-99
1.398040649781712473e-76
4 answers
Najbardziej niezawodnym sposobem, jaki znalazłem, jest użycie np.savetxt z np.loadtxt, a nie np.fromfile, co lepiej nadaje się do plików binarnych zapisanych za pomocą tofile. Metody np.fromfile i np.tofile zapisują i odczytują pliki binarne, podczas gdy np.savetxt zapisują plik tekstowy.
Na przykład:
a = np.array([1, 2, 3, 4])
np.savetxt('test1.txt', a, fmt='%d')
b = np.loadtxt('test1.txt', dtype=int)
a == b
# array([ True, True, True, True], dtype=bool)
Lub:
a.tofile('test2.dat')
c = np.fromfile('test2.dat', dtype=int)
c == a
# array([ True, True, True, True], dtype=bool)
Używam pierwszej metody, nawet jeśli jest wolniejsza i tworzy większe pliki( czasami): format binarny może być zależny od platformy (na przykład format pliku zależy od endianness twojego system).
Istnieje niezależny od platformy format dla tablic NumPy, który można zapisywać i odczytywać za pomocą np.save i np.load:
np.save('test3.npy', a) # .npy extension is added if not given
d = np.load('test3.npy')
a == d
# array([ True, True, True, True], dtype=bool)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-11-18 13:27:37
np.save('data.npy', num_arr) # save
new_num_arr = np.load('data.npy') # load
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-03-08 07:48:54
np.fromfile() posiada argument ze słowem kluczowym sep=:
Separator między elementami, jeśli plik jest plikiem tekstowym. Separator Empty ("") oznacza, że plik powinien być traktowany jako binarny. Spacje ( "" ) w separatorze odpowiadają zero lub więcej białym znakom. Separator składający się tylko ze spacji musi pasować do co najmniej jednej białej spacji.
Domyślna wartość sep="" oznacza, że np.fromfile() próbuje odczytać ją jako plik binarny, a nie jako plik tekstowy oddzielony spacjami, więc otrzymujesz wartości nonsensowne do tyłu. Jeśli użyjesz np.fromfile('markers.txt', sep=" "), otrzymasz wynik, którego szukasz.
Jednak, jak wskazywali inni, np.loadtxt() jest preferowanym sposobem konwersji plików tekstowych na tablice numpy i jeśli plik nie musi być czytelny dla człowieka, zwykle lepiej jest użyć formatów binarnych (np. np.load()/np.save()).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-02-10 19:54:43
Aby uzyskać krótką odpowiedź, należy użyć np.save i np.load. Zaletą jest to, że są one wykonane przez programistów biblioteki numpy i już działają (plus są prawdopodobnie już ładnie zoptymalizowane) np.]}
import numpy as np
from pathlib import Path
path = Path('~/data/tmp/').expanduser()
path.mkdir(parents=True, exist_ok=True)
lb,ub = -1,1
num_samples = 5
x = np.random.uniform(low=lb,high=ub,size=(1,num_samples))
y = x**2 + x + 2
np.save(path/'x', x)
np.save(path/'y', y)
x_loaded = np.load(path/'x.npy')
y_load = np.load(path/'y.npy')
print(x is x_loaded) # False
print(x == x_loaded) # [[ True True True True True]]
Odpowiedź Rozszerzona:
W końcu to naprawdę zależy od twoich potrzeb, ponieważ możesz również zapisać go w formacie czytelnym dla człowieka (zobacz to zrzuć tablicę NumPy do pliku csv ) lub nawet z innymi bibliotekami, jeśli Twoje pliki są bardzo duże (zobacz to najlepszy sposób na zachowanie tablic numpy na dysku dla rozszerzonej dyskusji).
Jednak (robiąc rozszerzenie, ponieważ używasz słowa "prawidłowo" w swoim pytaniu) nadal myślę, że korzystanie z funkcji numpy po wyjęciu z pudełka(i większość kodu!) najprawdopodobniej zaspokoi większość potrzeb użytkownika. Najważniejszym powodem jest to, że to już działa . Próba użycia czegoś innego z jakiegokolwiek innego powodu może zabrać cię w nieoczekiwanie długą króliczą norę, aby dowiedzieć się, dlaczego to nie działa i wymusić praca.
Weźmy na przykład próbę uratowania go za pomocą ogórka. Próbowałem tego tylko dla zabawy i zajęło mi co najmniej 30 minut, aby uświadomić sobie, że pickle nie zapisałby moich rzeczy, chyba że otworzyłem i przeczytałem plik w trybie bajtów za pomocą wb. Zajęło to trochę czasu, aby google, spróbować, zrozumieć komunikat o błędzie itp... Drobny szczegół, ale fakt, że to już wymagało ode mnie, aby otworzyć plik skomplikowane rzeczy w nieoczekiwany sposób. Dodam, że wymagało to od mnie ponownego przeczytania tego (co btw jest trochę mylące) różnica między trybami a, a+, w, w+ i r+ we wbudowanej funkcji otwartej?.
Więc jeśli istnieje interfejs, który spełnia Twoje potrzeby, użyj go, chyba że masz (bardzo) dobry powód(np. kompatybilność z matlabem lub z jakiegoś powodu naprawdę chcesz przeczytać plik i drukowanie w Pythonie naprawdę nie spełnia Twoich potrzeb, co może być wątpliwe). Co więcej, najprawdopodobniej jeśli chcesz go zoptymalizować, dowiesz się później (zamiast poświęcać wieki na debugowanie bezużyteczne rzeczy jak otwarcie prostego pliku numpy).
Więc użyj interfejsu / numpy provide . To może nie być idealne, najprawdopodobniej jest w porządku, szczególnie dla biblioteki, która istnieje tak długo, jak numpy.
Spędziłem już zapisywanie i ładowanie danych z numpy w kilka sposobów, więc baw się dobrze, mam nadzieję, że to pomoże!
import numpy as np
import pickle
from pathlib import Path
path = Path('~/data/tmp/').expanduser()
path.mkdir(parents=True, exist_ok=True)
lb,ub = -1,1
num_samples = 5
x = np.random.uniform(low=lb,high=ub,size=(1,num_samples))
y = x**2 + x + 2
# using save (to npy), savez (to npz)
np.save(path/'x', x)
np.save(path/'y', y)
np.savez(path/'db', x=x, y=y)
with open(path/'db.pkl', 'wb') as db_file:
pickle.dump(obj={'x':x, 'y':y}, file=db_file)
## using loading npy, npz files
x_loaded = np.load(path/'x.npy')
y_load = np.load(path/'y.npy')
db = np.load(path/'db.npz')
with open(path/'db.pkl', 'rb') as db_file:
db_pkl = pickle.load(db_file)
print(x is x_loaded)
print(x == x_loaded)
print(x == db['x'])
print(x == db_pkl['x'])
print('done')
Kilka uwag na temat tego, czego się nauczyłem:
-
np.savezgodnie z oczekiwaniami, to już dobrze kompresuje (zobacz https://stackoverflow.com/a/55750128/1601580 ), działa po wyjęciu z pudełka bez otwierania pliku. Czysto. Spokojnie. Wydajny. Użyj go. -
np.savezużywa nieskompresowanego formatu (zobacz docs)Save several arrays into a single file in uncompressed.npzformat.jeśli zdecydujesz się tego użyć (zostałeś ostrzeżony, aby odejść od standardowego rozwiązania, więc spodziewaj się błędów!) może się okazać, że musisz użyć nazw argumentów, aby je zapisać, chyba że chcesz użyć domyślnych nazw. Więc nie używaj tego, jeśli pierwszy już działa (lub jakiekolwiek użycie działa to!) - Pickle pozwala również na dowolne wykonywanie kodu. Niektórzy ludzie mogą nie chcieć tego używać ze względów bezpieczeństwa.
- czytelne dla człowieka pliki są drogie w tworzeniu itp. Pewnie nie warto.
- istnieje coś o nazwie
hdf5dla dużych plików. Super! https://stackoverflow.com/a/9619713/1601580
Uwaga nie jest to wyczerpująca odpowiedź. Ale dla innych zasobów sprawdź to:
- dla ogórków (chyba najlepszą odpowiedzią jest nie use pickle us
np.save): Save Numpy Array using Pickle - dla dużych plików (świetna odpowiedź! porównuje rozmiar pamięci, Ładowanie Zapisz i więcej!): https://stackoverflow.com/a/41425878/1601580
- dla Matlaba (musimy zaakceptować, że matlab ma jakieś fajne działki!): "konwertowanie" tablic Numpy na Matlab i odwrotnie
- do zapisania w formacie czytelnym dla człowieka: zrzut tablicy NumPy do pliku csv
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-07-13 19:50:59